• Die übersetzten SQL-Anfragen sollten effizient ausführbar sein. Dies kann
u.a. bedeuten, Wissen über die Relationen (etwa, ob sie Dimensionsdaten
oder Kennzahlen speichern) auszunutzen oder wiederholte Aggregationen
zu vermeiden.
• Die entstandenen Relationen und physischen Speicherstrukturen (z.B. In-
dexe) sollten leicht wartbar sein und etwas das einfache Laden neuer Daten
erlauben.
• Schließlich sind noch die Anfragecharakteristik (z.B. überwiegend Leseope-
rationen) und das Datenvolumen von Analyseanwendungen zu berücksich-
tigen.
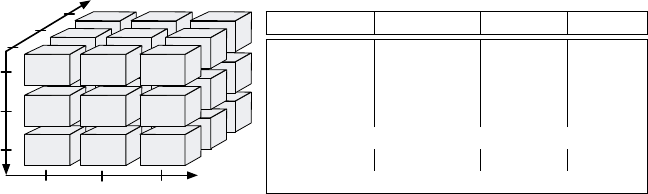
Ausgangspunkt einer relationalen Umsetzung ist die Repräsentation des
Datenwürfels ohne Klassifikationshierarchien. Die Kennzahlen und die Dimen-
sionen (genauer die Kategorieattribute mit der feinsten Granularität) werden
auf die Spalten einer Relation abgebildet, die als Faktentabelle bezeichnet wird.
Jede Zelle des Datenwürfels entspricht somit einem Tupel dieser Faktentabelle
(Abbildung 3.11).
Produkt
Ort
Zeit
Magdeburg
Ilmenau
18.02.2012
19.02.2012
Rotwein
Weißwein
Erfurt
20.02.2012
Hefeweizen
Produkt Filiale Tag Umsatz
Rotwein Magdeburg 18.02.12 145
Weißbier Magdeburg 18.02.12 160
Hefeweizen Magdeburg 18.02.12 259
Rotwein Ilmenau 18.02.12 121
. . .
Rotwein Magdeburg 19.02.12 142
. . .
Abbildung 3.11: Relationale Umsetzung: Faktentabelle
3.3.2 Snowflake-Schema
Für die Abbildung einer Dimension mit Klassifikationshierarchie gibt es zwei
grundsätzliche Varianten. Beim Snowflake-Schema wird für jede Dimension
pro Klassifikationsstufe eine eigene Tabelle eingeführt, die folgende Attribute
enthält:
• eine eindeutige ID für den Klassifikationsknoten,
• beschreibende (dimensionale) Attribute (wie z.B. Marke, Hersteller, Be-
zeichnung),
3.3 Relationale Umsetzung 57
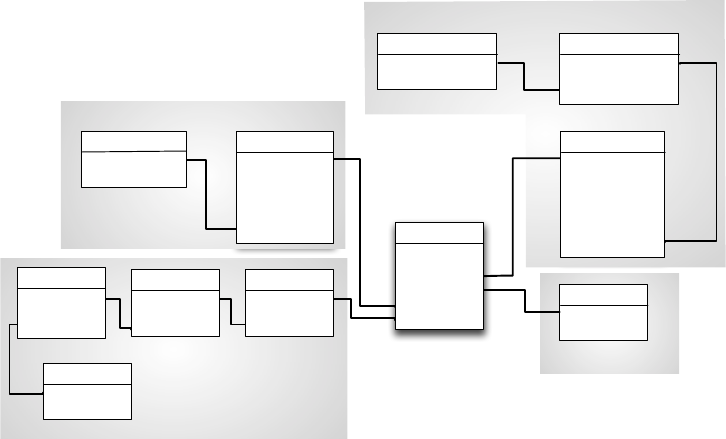
• den Fremdschlüssel der direkt übergeordneten Klassifikationsstufe.
In der Faktentabelle muss dann als Fremdschlüssel die ID der niedrigsten Klas-
sifikationsstufe jeder Dimension aufgenommen werden. Alle Fremdschlüssel
der Dimensionstabellen bilden zusammen den (zusammengesetzten) Primär-
schlüssel der Faktentabelle. In Abbildung 3.12 ist dieses Muster anhand eines
Beispielschemas dargestellt. Der Name „Snowflake“ kommt von der Form des
Schemas, die entsteht, wenn parallele Hierarchien vorhanden sind – in diesem
Fall verzweigen sich die Dimensionstabellen wie in einer Schneeflocke.
Zeit
Z_ID
Z_Datum
1
*
1
1
1
*
*
*
Produkt
P_ID
P_Bezeichnung
P_Verkaufspreis
P_Einkaufspreis
P_Rabatt
P_Steuern
P_PGruppe_ID
Verkauf
V_Anzahl
V_Kanal
V_Produkt_ID
V_Zeit_ID
V_Kunden_ID
V_Filial_ID
Kunde
K_ID
K_Name
K_Wohnort
K_Strasse
K_Geschlecht
K_KGruppe_ID
Filiale
F_ID
F_Filiale
F_Stadt_ID
Stadt
S_ID
S_Name
S_BLand_ID
Bundesland
B_ID
B_Name
B_Land_ID
Land
L_ID
L_Name
Kundengruppe
KG_ID
KG_Bezeichnung
Produktgruppe
PG_ID
PG_Bezeichnung
PG_PKategorie_ID
Produktkategorie
PK_ID
PK_Bezeichnung
11
*
*
*
*
*
*
1
1
1
1
Dimension "Produkt"
Dimension "Zeit"
Dimension "Kunde"
Dimension "Ort"
Abbildung 3.12: Snowflake-Schema
Die Abbildung einer Klassifikationshierarchie auf mehrere, über Fremd-
schlüssel miteinander verbundene Tabellen entspricht der Normalisierung aus
dem klassischen relationalen Datenbankentwurf: Die transitiven Abhängigkei-
ten zwischen den Klassifikationsattributen verletzen die 3. Normalform, sodass
eine Zerlegung notwendig ist.
Formal lässt sich dies wie folgt formulieren: Eine Dimension d mit dem
Schema DS
d
= ({D
1
, D
2
, . . . , D
n
, T op
D
}, →) wird durch n Tabellen mit dem
Schema DimTable
d
i
(DimKey
i
, D
i
,DimKey
i+1
) repräsentiert, wobei das Fremd-
schlüsselattribut Dim
i+1
Key für die n-te Tabelle DimTable
d
n
entfällt. In der Fak-
tentabelle mit m Fakten werden dann die Primärschlüssel DimKey
1
der aus jeder
Dimensionstabelle DimTable
d
1
mit ≤ d ≤ n aufgenommen: FactTable(Dim
1
1
_
Key,
..., Dim
n
1
_
Key, f
1
, ..., f
m
).
58 3 Modellierung von Data Warehouses
Get Data Warehouse Technologien now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

