• und dem Summationstyp SumTyp, der die erlaubten Aggregationsopera-
tionen definiert.
Damit kann das Schema M über einer nichtleeren Teilmenge der im Schema
existierenden Fakten F
1
, . . . F
k
definiert werden:
M = (G, f(F
1
, . . . , F
k
), SumTyp)
Beim Summationstyp lassen sich folgende drei Formen unterscheiden:
• Der Typ FLOW beschreibt ein Maß zu einem bestimmten Zeitpunkt. Hier-
bei sind Fakten und Kennzahlen beliebig aggregierbar. Ein Beispiel ist die
Bestellmenge eines Artikels pro Tag.
• Der Typ STOCK charakterisiert ein Maß über einen Zeitraum, d.h. einen
zeitlich andauernden Bestand, und ist somit beliebig aggregierbar mit Aus-
nahme von temporalen Dimensionen. Ein Beispiel hierfür ist der Lager-
bestand eines Produktes. Zwar kann die Summe über mehrere Produkte
berechnet werden, um den Gesamtlagerbestand zu ermitteln. Die Summe
der Lagerbestände eines Produktes über mehrere Tage hinweg ergibt je-
doch keinen Sinn.
• VALUE-PER-UNIT (VPU) beschreibt dagegen aktuelle Zustände, die nicht
summierbar sind, wie etwa Wechselkurse oder Steuersätze. Zulässige Ag-
gregatfunktionen sind nur MIN(), MAX() und AVG().
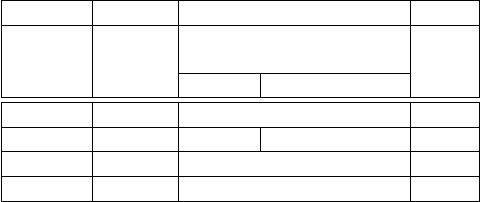
Die Tabelle in Abbildung 3.4 stellt die Eigenschaften dieser Typen noch einmal
gegenüber.
FLOW STOCK VPU
Aggregation über
temporale Dimension?
nein ja
MIN/MAX + + +
SUM + + − −
AVG + + +
COUNT + + +
Abbildung 3.4: Summationstypen für Kennzahlen
3.1.4 Schema des multidimensionalen Datenwürfels
Mit den oben eingeführten Definitionen kann nun des vollständige Schema ei-
nes Datenwürfels eingeführt werden. Seien dazu die Menge der Dimensionen(-
schemata) DS
1
, . . . , DS
n
und die Menge der Kennzahlen M
1
, . . . , M
m
gegeben.
Das Schema eines Würfels C ist demnach:
50 3 Modellierung von Data Warehouses
C = ({DS
1
, . . . , DS
n
}, {M
1
, . . . , M
m
})
Ein solches Schema sollte eine Reihe von Eigenschaften erfüllen, welche die
Unabhängigkeit der Dimensionen sowie die Aggregierbarkeit der Kennzahlen
betreffen:
Orthogonalität. Zunächst gilt die Orthogonalität der Dimensionen: Zwi-
schen den Attributen unterschiedlicher Dimensionen existieren keine funktio-
nalen Abhängigkeiten:
∀i, 1 ≤ i ≤ n, ∀j, 1 ≤ j ≤ n, i 6= j¬∃k, l : DS
i
.D
k
→ DS
j
.D
l
Disjunktheit. Bei der Definition von Aggregationen muss beachtet wer-
den, dass ein konkreter Wert einer Kennzahl nur genau einmal in das Ergebnis
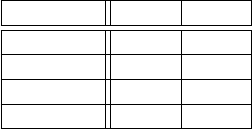
eingeht. Betrachten wir hierzu das Beispiel in Abbildung 3.5, in dem die Um-
satzzahlen für verschiedene Getränke erfasst sind.
Umsatz 2010 2011
Bier 38 42
Biermix 27 31
Softdrinks 54 57
Gesamt 92 99
Abbildung 3.5: Verletzung der Disjunktheit von Aggregaten
Offensichtlich ist der Gesamtumsatz nicht gleich der Summe über alle an-
gegebenen Getränkesorten: In diesem Fall sind Biermixgetränke eine Teilmen-
ge der Biere und dürfen somit nicht extra mit in die Gesamtsumme einbezogen
werden.
Vollständigkeit. Kennzahlen auf höherer Aggregationsebene sollten sich
immer komplett aus Werten tieferer Stufen berechnen lassen. Auch hierzu wol-
len wir wieder ein Beispiel betrachten. In der Tabelle in Abbildung 3.6 sind die
Verkaufszahlen eines Getränkehandels für Weine aus drei Hauptanbaugebie-
ten dargestellt. Da es neben diesen Gebieten auch noch einige wenige Produ-
zenten aus anderen Gebieten gibt, sind diese in der Zeile „Sonstige“ zusammen-
gefasst. Ohne diese zusätzliche Gruppe könnte die Summe nicht direkt aus den
Verkaufszahlen der aufgelisteten Gebiete berechnet werden.
Verträglichkeit der Aggregationsfunktionen. Entsprechend der Summati-
onstypen der Kennzahlen (siehe Abbildung 3.4) muss sichergestellt werden,
dass neue Kennzahlen nur aus solchen Fakten oder Kennzahlen berechnet wer-
den, wo dies auch zulässig ist. So sollte eine Kennzahl für die durchschnittliche
Verkaufsmenge pro Tag nicht auf für die Durchschnittsberechnung auf einer
höheren Aggregationsebene herangezogen werden.
3.1 Das multidimensionale Datenmodell 51
Get Data Warehouse Technologien now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

