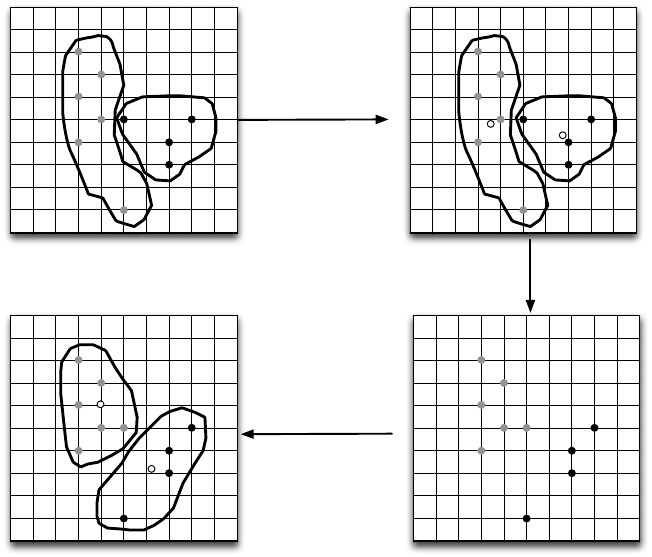
Berechnung der
neuen Centroide
Zuordnung zum nächsten Centroid
Berechnung der
neuen Centroide
Abbildung 9.12: Illustration des Clusterverfahrens
9.3.3 Klassifikationsverfahren
Klassifikationsverfahren werden sowohl im Bereich des Machine Learning als
auch in der Statistik entwickelt. Hierzu zählen Verfahren vom Naive Bayes und
Bayes’schen Netzwerken über neuronale Netze und Support Vector Machines.
Wir wollen uns in diesem Abschnitt auf den Entscheidungsbaum fokussieren.
Daneben existieren unter anderem folgende Klassifikationsmethoden:
• Regelbasierte Klassifikatoren
• Lineare Diskriminanzanalyse nach Fisher [Fis36]
• Kategorielle Regression bzw. log-lineare Modelle
• Neuronale Netze
• Naive Bayes und Bayesian Belief Networks
• Support-Vektor-Maschinen
9.3 Data Mining im BI-Umfeld 293
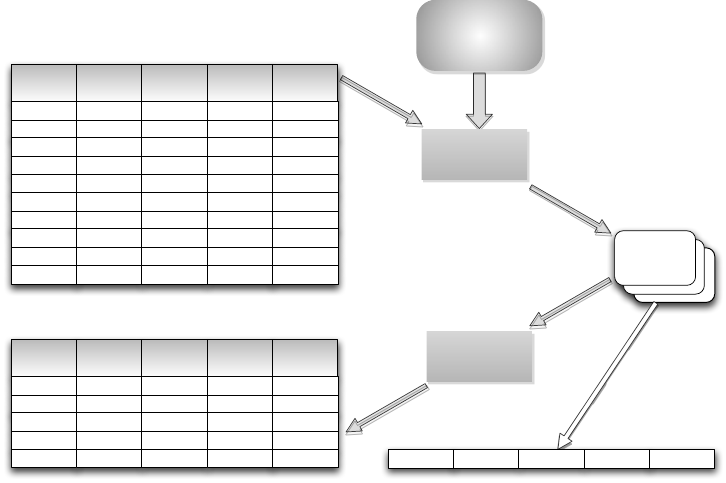
Modell
Modell
TID Weinart
Restsüße
g/l
Alkohol-
gehalt
Ja/Nein
1 Weiß 18 10 Ja
2 Rot 20 9 Ja
3 Rosé 22 9 Nein
4 Rosé 15 8 Nein
5 Rot 30 5 Ja
6 Weiß 18 10 Ja
7 Rot 15 15 Nein
8 Weiß 45 5 Ja
Schmeckt uns der Wein?
9 Weiß 18 14 Ja
10 Rot 8 10 Nein
TID Weinart
Restsüße
g/l
Alkohol-
gehalt
Ja/Nein
11 Rot 23 10 ?
12 Rosé 15 12 ?
13 Weiß 22 10 ?
14 Weiß 30 6 ?
15 Rot 12 14 ?
Trainingsset
Testset
Lerne
Modell
Wende
Modell an
Modell
Induktion
Deduktion
Lern-
algorithmen
17 Weiß 5 16 ?
Inferenz
Abbildung 9.13: Beispiel für Klassifikation
Abbildung 9.13 stellt das Problem der Klassifikation grafisch anhand un-
seres Verkaufsladen dar. Ausgangspunkt ist die Frage, welcher Wein dem Kun-
den schmeckt. Hierzu werden unterschiedliche Merkmale, wie Farbe, Restsüße
und Alkoholgehalt genutzt, um eine Klassifikation vorzunehmen. Die Grundla-
ge sind dafür Trainingsdaten, bei denen die Zuordnung zu den Klassen erfolgt
ist. Mittels Lernalgorithmen wird dann versucht, das zugrunde liegende Mo-
dell zu lernen. Dabei erfolgt eine Induktion von den Daten auf die Modellwelt.
Im Anschluss muss das erlernte Modell noch überprüft werden. Hierzu werden
Testdaten herangezogen, bei denen ebenfalls die Klassenzugehörigkeit bekannt
ist. So kann eine Modellgüte berechnet werden. Zudem ist es möglich, Inferenz
für unbekannte Klassenelemente anhand ihrer Merkmale zu betreiben.
Für das Klassifikationsproblem müssen somit eine Menge von Objekten
o mit den Attributen o = (x
1
, . . . , x
d
) und die Zugehörigkeit zur Klassenmen-
ge C als Vorinformation bekannt sein. Gesucht ist dann der Klassifikator K
für neue Objekte, sodass K : Objekte
neu
→ C. Daraus ergibt sich auch die
Abgrenzung zum Clusterverfahren, da eine Klassenzugehörigkeit für gegebene
Objekte a priori bekannt ist. Vergleichbar ist das Verfahren zur Prognose, siehe
Abschnitt 9.3.4, z.B. zur linearen Regression.
294 9 Business-Intelligence-Anwendungen
Vorhersage
Klasse zugehörig Klasse nicht zugehörig
wahre Klasse zugehörig True Positive (T P ) False Negative (F N )
Werte Klasse nicht zugehörig False Positive (F P ) True Negative (T N )
Tabelle 9.6: Klassifikationsgüte
Die Entscheidungsbaumklassifikation verfolgt in ihrer Vorgehensweise ei-
ne Aufteilungsstrategie, um die Objekte möglichst eindeutig den jeweiligen
Klassen zuzuordnen. Klassifikationsbäume finden dabei nur explizites Wissen,
lassen sich aber gut darstellen. Sie sind für die meisten Nutzer leicht verständ-
lich und können somit einen Entscheidungsprozess nachvollziehbar unterstüt-
zen. Sie stellen hierarchische Klassifikatoren dar, die dann effizient sind, wenn
viele Attribute vorliegen, für die Klassenzuordnung aber nur wenige benötigt
werden. Ziel für den Entscheidungsbaum sind dabei ausbalancierte und kurze
Bäume, um die Anzahl der Vergleiche gering zu halten.
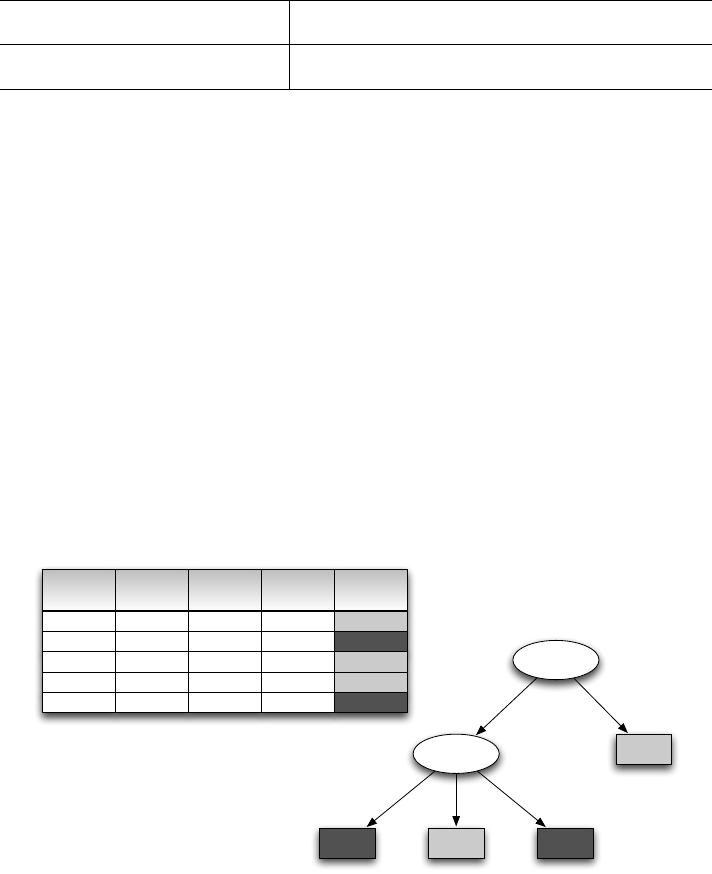
In Abbildung 9.14 ist für unser Beispiel der Entscheidungsbaum abgebil-
det. Zuerst wird anhand der Restsüße im Wein entschieden, denn liebliche Wei-
ne (d.h. mit mehr als 15 g/l) sind der Klasse schmeckt in den Trainingsdaten
zugeordnet. Für weniger süße Weine ist auf der zweiten Ebene die Farbe für die
Klassenzugehörigkeit relevant. Roséweine fallen in die präferierte Klasse, die
anderen Weine nicht.
TID Weinart
Restsüße
g/l
Alkohol-
gehalt
Ja/Nein
1 Rot 23 12 Ja
2 Weiß 15 10 Nein
3 Rose 14 10 Ja
4 Weiß 30 6 Ja
5 Rot 12 14 Nein
Restsüße
Weinart
Nein
Ja
Ja Nein
>15<=15
Rot
RoséWeiß
Abbildung 9.14: Klassifikationsergebnis
Die Güte des erlernten Modells wird mittels der Klassifikationsgüte an-
hand der vorhandenen Testdaten überprüft. Dabei können die in Tabelle 9.6
dargestellten Ereignisse auftreten. Aus diesen möglichen Zuordnungen lassen
sich dann unterschiedliche Bewertungskriterien ableiten.
9.3 Data Mining im BI-Umfeld 295
Get Data Warehouse Technologien now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

