8.1.2 Star-Join-Optimierung
Eine wesentliche Teilaufgabe der physischen Optimierung ist die Bestimmung
der Verbundreihenfolge, d.h. die Festlegung, in welcher Reihenfolge Verbund-
operationen ausgeführt werden soll. Im Interesse einer effizienten Anfragever-
arbeitung sollten zunächst die Verbunde ausgeführt werden, die möglichst klei-
ne Zwischenergebnisse liefern. Hierzu muss der Anfrageoptimierer alle mög-
lichen Kombinationen von Verbundreihenfolgen ermitteln und die jeweiligen
Ausführungskosten abschätzen. Da die Anzahl der Kombinationen bei größe-
ren Verbunden sehr groß wird, wird der Suchraum oft durch Heuristiken ein-
geschränkt. So werden etwa nur bestimmte Formen von Verbundbäumen be-
trachtet oder Verbunde, die zu Kreuzprodukten entarten, nicht berücksichtigt.
Betrachten wir hierzu als Beispiel einen Verbund der Faktentabelle Verkauf
mit den drei Dimensionstabellen Produkt, Zeit und Ort:
SELECT
*
FROM Verkauf, Ort, Zeit, Produkt
WHERE V
_
Ort
_
ID = O
_
ID AND V
_
Zeit
_
ID = Z
_
ID AND
V
_
Produkt
_
ID = P
_
ID AND O
_
Bundesland = ’Thüringen’ AND
YEAR
_
MONTH(Z
_
Datum) = 201101 AND P
_
Produktkategorie = ’Bier’
Dieser 4-Wege-Verbund wird üblicherweise durch eine Sequenz binärer
Verbunde berechnet, wobei es 4! mögliche Reihenfolgen gibt. Mit einer der oben
erwähnten Heuristik – Verbunde zwischen Relationen, die nicht über eine Ver-
bundbedingung verknüpft sind, werden nicht berücksichtigt – wird beispiels-
weise der in Abbildung 8.2 angegebene Ausführungsplan erstellt.
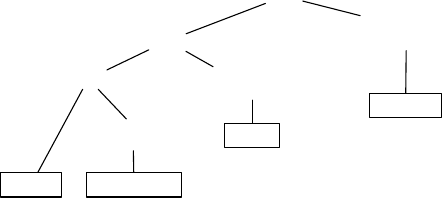
Verkauf Ort
Zeit
σ
Produktkategorie='Bier"
⋈
⋈
⋈
Produkt
σ
Bundesland='Thüringen'
σ
Datum=201101
Abbildung 8.2: Anfrageplan mit Verbundreihenfolge für Star Join
Eine typische Data-Warehouse-Anfrage folgt jedoch meist dem Star-Join-
Muster, bei dem eine sehr große Faktentabelle mit mehreren, deutlich kleine-
ren und voneinander unabhängigen Dimensionstabellen verbunden wird. Der
Verbund mit den Dimensionstabellen dient dabei oft der Selektion, die jedoch
erst zum Tragen kommt, wenn die Faktentabelle schon komplett gelesen wur-
de. Es wäre daher unter Umständen günstiger, zunächst das Kreuzprodukt der
234 8 Anfrageverarbeitung und materialisierte Sichten

Dimensionstabellen zu berechnen und dabei die Selektionen auf den Dimensio-
nen auszuführen und erst danach die relevanten Tupel aus der Faktentabelle
zu lesen (Abbildung 8.3).
Verkauf
OrtZeit
σ
Produktkategorie='Bier'
×
×
⋈
Produkt
σ
Bundesland='Thüringen'
σ
Datum=201101
Abbildung 8.3: Alternativer Anfrageplan mit Kreuzprodukten
Diese Technik wurde in Oracle als Star-Join-Optimierung vor der Einfüh-
rung von Bitmap-Indexen in Version 7.3 genutzt. Voraussetzung für die Anwen-
dung ist ein zusammengesetzter Index auf der Faktentabelle über alle Fremd-
schlüsselattribute (hier auf (V
_
Zeit
_
ID, V
_
Ort
_
ID, V
_
Produkt
_
ID)).
Ein einfaches Berechnungsbeispiel soll den Vorteil illustrieren. Wir gehen
von einer Faktentabelle Verkauf mit 10.000.000 Datensätzen und der obigen
Anfrage aus.
Die Selektionen haben folgende Selektivitäten, wobei zur Vereinfachung
eine Gleichverteilung aller Attributwerte angenommen sei:
• 10 Filialen in Thüringen (von insgesamt 1000),
• 20 Verkaufstage im Januar 2011 (von 1000 gespeicherten Tagen),
• 50 Produkte in Produktkategorie „Bier“ (von 1000 Produkten).
Für die beiden oben betrachteten Pläne ergeben sich daraus die in Tabelle 8.1
dargestellten Kardinalitäten der Zwischenergebnisse: Offensichtlich ist die Va-
riante mit den Kreuzprodukten hier vorteilhafter.
Allerdings ist die Berechnung des Kreuzprodukts für die Dimensionstabel-
len nur bei ausreichend restriktiven Selektionsbedingungen auf den Dimensio-
nen sinnvoll. Anderenfalls wird das Zwischenergebnis zu groß: Nimmt man für
die obige Anfrage etwa 100 Filialen, 1000 Tage und 1000 Produkte, so erhält
man 100.000.000 Tupel und damit mehr als Tupel der Faktentabelle.
Eine Alternative zur Vermeidung der vollständigen Berechnung des Kreuz-
produktes ist der Einsatz von Semi-Verbunden. Allgemein ist ein Semi-Verbund
ist eine Verbundoperation, die im Ergebnis nur die Attribute der ersten Relati-
on liefert und somit nur die Tupel der ersten Relation liefert, die einen Verbund-
partner besitzen. Für die Unterstützung eines Star Join wird auf der Faktenta-
belle für jede Dimension (d.h. das Fremdschlüsselattribut) ein B+-Baum-Index
8.1 Anfrageplanung 235
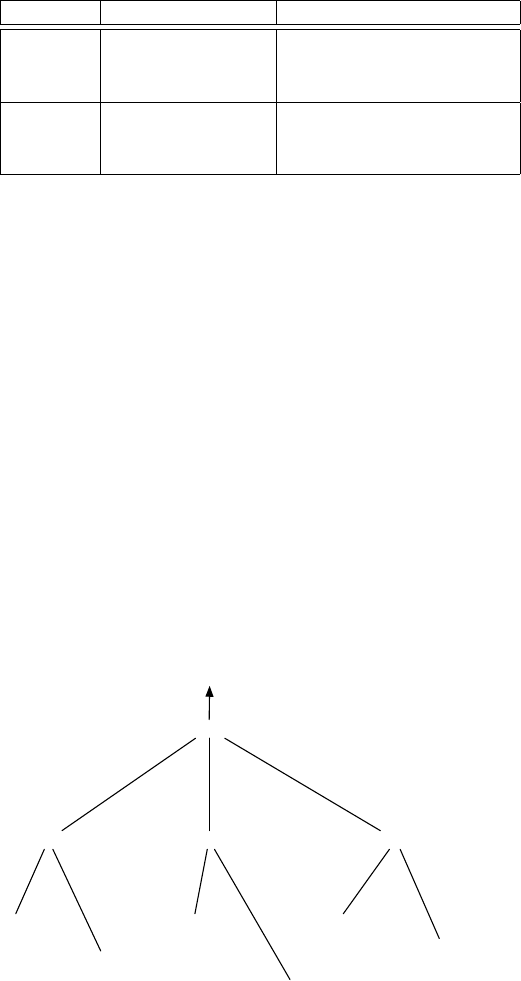
Plan Operation Ergebniskardinalität
Abb. 8.2 1. Join 1.000.000
2. Join 20.000
3. Join 1.000
Abb. 8.3 1. Kreuzprodukt 200
2. Kreuzprodukt 10.000
3. Join 1.000
Tabelle 8.1: Kostenvergleich der Pläne
angelegt. Zur Auswertung wird jede in der Anfrage referenzierte Dimensionsta-
belle gelesen und jeweils über einen Semi-Verbund mit dem zugehörigen Index
der Faktentabelle verknüpft. Der Semi-Verbund liefert dabei nur die Tupeliden-
tifikatoren (TIDs) der inneren Relation – hier die TIDs der in Frage kommen-
den Tupel der Faktentabelle. Diese TID-Mengen (für unser Anfragebeispiel drei
Mengen) werden nun geschnitten. Da es sich hierbei um vergleichsweise kleine
Datenmengen handelt, kann dies meist effizient im Hauptspeicher berechnet
werden. Als Ergebnis entsteht eine Menge von TIDs aller Tupel der Faktenta-
belle, welche die Bedingungen für alle Dimensionen erfüllen. Diese TID-Menge
kann nun genutzt werden, um die eigentlichen Tupel der Faktentabelle zu lesen
und die normalen paarweisen Verbundoperationen mit den Dimensionstabellen
durchzuführen. Abbildung 8.4 illustriert die erste Phase dieses in DB2 verwen-
dete Prinzip an einem Beispiel. Die drei Indexe der Faktentabelle sind dabei als
Verkauf
_
Ort
_
IDX etc. bezeichnet, eventuell anzuwendende Selektionen auf den
Dimensionstabellen im Rahmen der TableScan sind nicht dargestellt.
IndexScan(Verkauf_Or t_IDX,Ort_ID)
IndexScan(Verkauf_Produkt_IDX,Produkt_ID)
SemiJoin
TID-Intersect
IndexScan(Verkauf_Zeit_IDX,Zeit_ID)
TableScan(Ort) TableScan(Produkt) TableScan(Zeit)
SemiJoin SemiJoin
TIDs der Faktentabelle
TIDs
TIDs
TIDs
Abbildung 8.4: Star-Join-Auswertung mit Semi-Verbund
236 8 Anfrageverarbeitung und materialisierte Sichten
Get Data Warehouse Technologien now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

