Hauptspeichersuchen entwickelt wurden. Der Aufwand ist (bei ausgeglichener
Baumstruktur) wie bei Suchbäumen üblich von der Größenordnung O(log n) bei
Exact-Match-Anfragen. Partial-Match-Anfragen sind typischerweise ebenfalls
deutlich besser als O(n), da ganze Teilbäume nicht durchsucht werden müssen.
A
B
E
I
J
F
C
D
H
G
x
y
x:40
x:26
y:51
x:80
y:60
{E} {A,B} {I,J} {D} {H,G} {F,C}
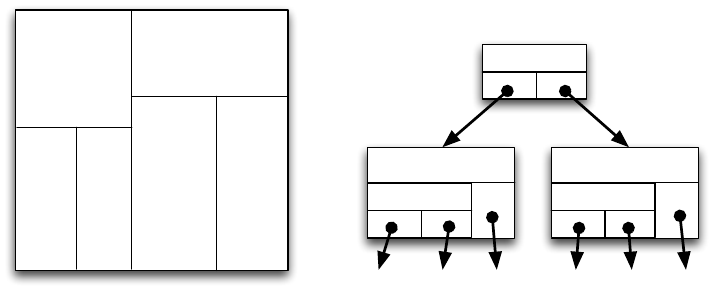
Abbildung 7.18: KdB-Baum
Abbildung 7.18 verdeutlicht den Aufbau eines KdB-Baums anhand zweier
Dimensionen x und y. Bei einem KdB-Baum vom Typ (b, t) enthalten die Be-
reichsseiten (die inneren Knoten): einen kd-Baum mit maximal b internen Kno-
ten und die Satzseiten (die Blätter) bis zu t Tupel der gespeicherten Relation.
Im Beispiel haben beide Werte den Wert 2.
Der KdB-Baum ist nicht symmetrisch, da die Trennattribute zyklisch fest-
gelegt werden. Bei der Festlegung der Reihenfolge kann man die Selektivität
einbeziehen, indem ein Zugriffsattribut mit hoher Selektivität möglichst früh
und häufiger als Schnittelement eingesetzt wird. Bei der Wahl der Trennattri-
butwerte ist es notwendig, eine geeignete Mitte des aufzuteilenden Wertebe-
reichs aufgrund von Verteilungsinformationen zu finden.
KdB-Bäume speichern auch schlecht verteilte Daten effizient, sind aber
für mehr als drei Dimensionen schwer handhabbar. Abbildung 7.19 zeigt die
Aufteilung des Raumes für nicht gleich verteilte Daten. Man sieht, dass die
Suchregionen sich zwar an die Verteilung anpassen (im Gegensatz etwa zum
Grid-File), aber durchaus große, dünn besetzte Regionen entstehen.
7.5.4 R-Bäume
Der R-Baum ist die Generalisierung des eindimensionalen B-Baums auf mehr-
dimensionale Bereiche. Ursprünglich für die Indexierung ausgedehnter Objek-
te mit umschreibenden Rechtecken entwickelt, eignet er sich auch sehr gut für
die Indexierung von Punkten im mehrdimensionalen Raum.
218 7 Indexstrukturen
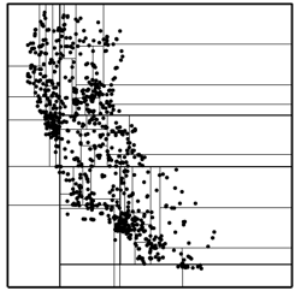
Abbildung 7.19: Daten im KdB-Baum
Ein R-Baum für eine Dimension d hat analog zum B-Baum eine Ordnung
k. Jeder Knoten des R-Baums speichert maximal m Indexeinträge für m = 2k,
und jeder Knoten (außer der Wurzel) enthält mindestens n Einträge für n = k.
Ein d-dimensionaler R-Baum verwendet d-dimensionale Intervalle (Rechtecke,
Quader, Hyperquader) zur Indexierung des Datenraums. Ein Eintrag auf der
Blattebene hat die Form (I, tid), wobei I ein d-dimensionales Intervall und tid
ein Tupelidentifikator ist, der den entsprechenden Datensatz referenziert. Für
Punktdaten sind die umschreibenden Intervalle ebenfalls Punkte (obere Gren-
ze gleich untere Grenze). Ein Eintrag in einem inneren Knoten hat die Form
(I, cp), wobei I ein d-dimensionales Intervall ist, das alle Intervalle der Ein-
träge des Kindknotens umfasst (also eine minimum bounding box), und cp der
Zeiger auf diesen Kindknoten (child pointer) ist.
Abbildung 7.20 zeigt ein Beispiel für einen 2-dimensionalen R-Baum der
Ordnung 2. Die Datensätze sind hierbei ausgedehnte Rechtecke, keine Punkt-
daten.
Prinzipiell übertragen sich die Operationen (Suchen, Einfügen, Löschen)
von B
+
-Bäumen auf R-Bäume, natürlich angepasst an k-dimensionale Recht-
ecke anstelle eindimensionaler Intervalle. Einige Besonderheiten im Vergleich
zum B
+
-Baum müssen jedoch beachtet werden. Beim Suchen können sich ver-
schiedene Regionen von Knoten gleicher Ebene überlappen. In diesem Fall müs-
sen selbst bei Punktanfragen eventuell mehrere Nachfolger traversiert werden.
Beim Einfügen wird versucht, ein Intervall zu finden, das nicht erweitert wer-
den muss. Gelingt dies nicht, wird das Intervall genommen, das am wenigsten
erweitert werden muss (eventuell auf jeder Ebene nötig). Das Löschen von Da-
ten spielt für das Data Warehouse keine Rolle.
Da sich DW-Systeme durch ein Einfügen nur in größeren Abständen (dann
aber oft mit vielen neuen Tupeln) auszeichnen, muss allerdings eine effiziente
Möglichkeit des Bottom-up-Aufbaus der R-Baum-Struktur realisiert werden.
7.5 Mehrdimensionale Indexstrukturen 219
Get Data Warehouse Technologien now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

