SELECT SUM(Verkauf.Verkäufe)
FROM Verkauf, Geographie
WHERE Verkauf.GeoID = Geographie.GeoID AND
Geographie.Stadt = ’Magdeburg’
7.5 Mehrdimensionale Indexstrukturen
Man kann mit einem „normalen“ eindimensionalen Index mehrere Dimensio-
nen indexieren, indem die Werte konkateniert werden. Wie wir gesehen haben,
sind derartige Lösungen asymmetrisch. Echte mehrdimensionale Indexstruktu-
ren sind symmetrisch, also in der Performance nicht empfindlich gegen Ände-
rungen der Dimensionsreihenfolge.
Hash-basierte Indexstrukturen basieren auf der Kodierung von Werten.
Wir werden Grid-Files und mehrdimensionales dynamisches Hashen als kon-
krete Verfahren vorstellen. Baumbasierte Strukturen erweitern das Prinzip
der Suchbäume auf mehrdimensionale Bereiche. Konkret werden wir den KdB-
Baum, den R-Baum und den UB-Baum vorstellen.
All diese Verfahren werden in [SSH11] detaillierter vorgestellt. Wir werden
daher hier jeweils nur knapp die Basisideen präsentieren.
7.5.1 Grid-File
Das Grid-File ist eine symmetrische mehrdimensionale Dateiorganisations-
form, die eine Kombination von Elementen der Schlüsseltransformation (Hash-
Verfahren) und Indexdateien (Baumverfahren) realisiert. Die Idee ist dabei, ein
(mehrdimensionales) Gitter (das Grid) über den aufgespannten Datenraum zu
legen, das den Raum in Zellen einteilt. Jeder Datenpunkt ist dann einer Zelle
zugeordnet. Die Zellengröße wird dann durch Verfeinerung des Gitters derart
gewählt, dass Zellen im schlechtesten Fall eine maximale Anzahl von Daten-
punkten enthalten, die einer optimalen Speichereinheit entsprechen. Da das
Gitter regulär ist, gibt es natürlich dann Zellen mit zu geringer Auslastung.
Daher können Zellen zu Regionen zusammengefasst werden.
Genauer erfolgt eine Dimensionsverfeinerung, indem eine gleichmäßige
Aufteilung des mehrdimensionalen Raumes in der ausgewählten Dimensi-
on durch einen vollständigen Schnitt vorgenommen wird. Mathematisch ent-
spricht dies dem Einziehen einer Hyperebene.
Der Datenraum wird durch die Hyperebenen in mehrdimensionale Qua-
der aufgeteilt. Für k Dimensionen entsprechen daher unterstützte Suchregio-
nen ebenfalls k-dimensionalen Quadern. Um eine Nachbarschaftserhaltung bei
der Speicherung zu erzielen (ermöglicht Prefetching bzw. effiziente Bearbeitung
von Suchregionen, die mehrere Zellen enthalten) wird möglichst eine Spei-
214 7 Indexstrukturen
cherung ähnlicher Objekte auf der gleichen Seite realisiert. Das Grid-File er-
möglicht eine symmetrische Behandlung aller Raumdimensionen und behan-
delt daher Partial-Match-Anfragen für unterschiedliche Dimensionsauswahlen
gleich.
Eine Herausforderung beim Grid-File ist die dynamische Anpassung der
Struktur beim Einfügen und Löschen. Für Exact-Match-Anfragen wird dabei
das Prinzip der zwei Plattenzugriffe realisiert, wie wir im Folgenden sehen wer-
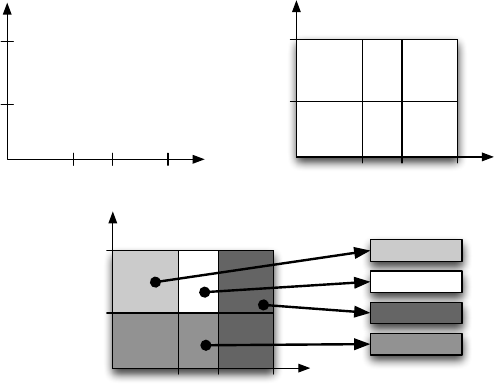
den. Abbildung 7.16 verdeutlicht das Prinzip des Grid-File:
Skalen (Intervalle) Grid-Directory (Zellen)
Regionen Seiten
Abbildung 7.16: Aufbau des Grid-File
• Das Grid wird durch k eindimensionale Felder, die Skalen des Grids, ein-
geteilt. Jede Skala repräsentiert ein Attribut bzw. eine Dimension.
Die Skalen realisieren eine Partition der zugeordneten Wertebereiche in
Intervalle. Skalen werden im Hauptspeicher gehalten.
• Das Grid-Directory definiert die Grid-Zellen, die den Datenraum in Quader
zerlegen.
Das Grid-Directory definiert ein Array, bei dem jeder Zelle die Adresse ei-
ner Speichereinheit zugeordnet ist. Das Grid-Directory kann so groß wer-
den, dass eine Verwaltung außerhalb des Hauptspeichers notwendig wird.
• Mehrere Grid-Zellen bilden eine Grid-Region, der genau eine Datensatz-
seite zugeordnet ist. Alle Zellen derselben Region haben also im Directory
denselben Eintrag.
7.5 Mehrdimensionale Indexstrukturen 215
Get Data Warehouse Technologien now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

