Chapter 4. The Analyst Organization
A really great data analyst should get people excited... I knew I was the first to get the data, so I was the first to know the story. It’s fun discovering stuff.
Dan Murray
The human component of a great data-driven organization is a great analytics organization. Who are those people, and how should they be organized?
In this chapter, I will cover the analytics organization itself: the types of staff that comprise it and the skills that they should possess. I’ll examine the breadth of analytics positions, and we’ll meet some of the people in those varied roles. In addition, there are a number of ways in which analysts can be organized, each with a different set of pros and cons, and so I’ll step through various organizational structures.
Types of Analysts
A data-driven organization is likely to have a variety of analyst roles, typically organized into multiple teams. Different people describe different analyst roles differently, and many of the skills are overlapping among them, but I’ll outline a general description of my version of data analysts, data and analytics engineers, business analysts, data scientists, statisticians, quants, accountants and financial analysts, and data-visualization specialists. For each, I’ll describe the types of skills they tend to possess, the tools they use, and provide an example of someone in that role. Your organization may have a different set of titles, but the skills described here are generally necessary in order to make the most of your data.
Data Analyst
This is the broadest, most common term, at least compared to the more specialized roles discussed next. In many cases, they are T-shaped: they have shallower experience across a broad spectrum of skills but deep skills and domain knowledge in a dominant area. Data analysts range from entry-level positions, which are often more focused on data gathering and preparation, to highly skilled and very specialized analysts. Such analysts are often domain experts, focusing on a wealth of different areas, such as voice of the customer, loyalty programs, email marketing, geo-specialized military intelligence, or certain segments of the stock market. The particular roles in an organization depend on the organization’s size, maturity, domain, and market. In all these roles, their output is likely to be a mix of both reporting and analysis. As well as breadth of domain, analysts vary widely in their level of technical skills.
At one end are analysts who work solely in the world of Excel and vendor dashboards. At the other end are people, such as Samarth, who write Scala code against raw, large-scale data stores at Etsy. Samarth’s background is in political science, but he got his analytics training while working on Barack Obama’s 2012 re-election campaign. There he picked up R, SQL, and Python—the typical data scientist’s trifecta—to run web and email experiments. He is now data analyst at Etsy in New York, where he still works on web and email experiments but also clickstream analysis, analyzing trends, and writing reports and white papers. He works with a variety of product managers, engineers, and designers across the company to help design experiments, analyze them with Scala/Scalding, R, and SQL, and interpret those results. He also writes general company-wide white papers as well as more specific memos for executives to understand trends, user behavior, or specific features.
An analyst with a very different profile is Samantha. She has a bachelor’s degree in accountancy and works as a data analyst for Progressive Insurance in Cleveland, Ohio at in their claims control finance team. She manages an escheatment (the transfer of unclaimed or abandoned property to the state) process for claims through audit, analysis, and compliance with state escheatment laws. That involves creating reports to track abandoned property, analyzing outstanding drafts, and summarizing the financial risk associated with those. She uses a mix of SAS, Excel, and Oracle, as well as domain-specific tools, such as ClaimStation. She has a broad set of internal “customers” who rely on her work including Corporate Tax, Financial Operations, IT, Claims Business Leaders, as well as individual claims representatives in the field and is driven, she says, by “seeing my analysis pay off to the financial benefit of both Progressive and our insured customers.” Being in a more heavily regulated industry and with particular responsibilities for ensuring that Progressive comply with state laws, attention to detail is an especially important trait in her role.
Data Engineers and Analytics Engineers
Primarily responsible for obtaining, cleaning, and munging data and getting it into a form that analysts can access and analyze. They are responsible for operational concerns, such as throughput, scaling, peak loads, and logging, and may also be responsible for building business intelligence tools that analysts use.
Meet Anna. While working toward a Ph.D. in physics, she realized her true passion lay in data science and joined Bitly as a data scientist, leaving her graduate program with a master’s degree. At Bitly she created visualizations from large datasets, crunched data with Hadoop, and implemented machine learning algorithms. She then joined Rent The Runway and is now a data engineer. Using tools such as SQL, Python, Vertica, and bash, she now maintains the data infrastructure that supports the analysts, develops new tools to make data more reliable, timely, and scalable, and she acts as the touchpoint with the rest of the organization’s engineers to understand any changes that they are making that will impact data.
Business Analysts
Analysts who typically serve as the interface between business stakeholders (such as department heads) and the technology department (such as software developers). Their role is to improve business processes or help design and develop new or enhanced features in backend systems or frontend systems, such as an enhanced checkout flow on a customer-facing website.
Lynn is senior business analyst for Macys.com. With a bachelor’s degree in fine arts, experience as an application developer, and Project Management Professional certification, Lynn has a decade of experience of project management and business analysis, mostly in bookselling ecommerce. Her role involves analysis of project requirements, understanding clients’ needs, process improvement, and project management, often using an agile approach. “There isn’t a typical day,” she said. “Some days I talk with the users” (i.e., merchants who use Macy’s product information management system) “about their needs, some days I review user stories with the developers, or answer questions from QA or developers about the user stories.”
Data Scientists
A broad term that tends to include more mathematically or statistically inclined staff, typically with both advanced degrees (often in quantitative subjects, such as math, sciences, and computer science) and developed coding skills. I like Josh Wills’ pithy definition: “Data Scientist (n.): Person who is better at statistics than any software engineer and better at software engineering than any statistician." However, it doesn’t fully capture their role, which might be to build “data products,” such as recommendation engines using machine learning, or to do predictive modeling and natural language processing.1
Trey, a senior data scientist at Zulily, a daily-deals site based in Seattle, is one such data scientist. With a master’s degree in sociology, Trey splits his time working on a variety of projects ranging from building statistical models and recommendation algorithms that improve customer experience to helping product managers interpret the results of an A/B test. He mostly uses Python (using libraries such as pandas, scikit-learn, and statsmodels) and will pull down data to analyze using SQL and Hive. While he has the technical skills to build statistical models, he considers the the ability to explain those models to nonexperts a crucial data science skill. This love of teaching is reflected in his hobby, the spread, a blog that teaches data science concepts using American football data as well as how to become more informed consumers of sports statistics.
Statisticians
Skilled personnel who focus on statistical modeling across the organization. They typically have at least a master’s degree in statistics and are especially prevalent in insurance, healthcare, research and development, and government. One quarter of statisticians in the US work for federal, state, and local government. They are often involved in not just analysis but the design of surveys, experiments, and collection protocols to obtain the raw data.
Meet Shaun, a statistician supporting quantitative marketing at Google’s Boulder office. With a bachelor’s degree in mathematics and computational science and a Ph.D. in statistics, Shaun now has a varied role supporting employees on other teams, often moving from project to project as needs arise. One on hand, his work can involve pulling, cleaning, visualizing, and verifying the quality of a new data source. One the other, he taps into his statistical skills to develop clustering algorithms to improve online search geo-experiments, develop Bayesian structural time series models, or to estimate individual-level viewership from household-level data using Random Forests. He spends most of his time in R, especially to analyze and visualize data (notably packages like ggplot2, plyr/dplyr, and data.table). However, he also extracts data with SQL-like languages and uses some Python and Go.
Quants
Mathematically skilled quantitative analysts who typically work in the financial services sector modeling securities, risk management, and stock movements on both the buy and sell side of the market. For example, a pension fund may employ a quant to put together an optimal portfolio of bonds to meet the fund’s future liabilities. They often come from mathematics, physics, or engineering backgrounds, and some—especially algorithmic trading analysts (the highest paid of all analyst positions)—are especially strong programmers in languages, such as C++, that can process data and generate actions with very low latency.
Satish is a quant at Bloomberg in New York, coming to the role with a strong background in both applied math and electrical engineering, including a Ph.D. He uses R (ggplot2, dplyr, reshape2), Python (scikit-learn, pandas), and Excel (for pivot tables) to build a range of statistical models and then C/C++ to roll some of those into production. Those models often cover relative value for various fixed-income asset classes. However, he also serves as an internal consultant and thus gets to work on a diverse set of problems ranging from credit models for mortgage-backed securities to predicting wind power supply in the UK. “The vast amounts of financial data and analytics that are available at Bloomberg are unmatched in the industry,” he says. “As such, it is extremely rewarding to know that most of the models we build are things that provide value to all our customers.” One of the challenges of working with financial data is that it is very long-tailed and thus the models must handle those rare, extreme events gracefully.
Accountants and Financial Analysts
Staff that focus on internal financial statements, auditing, forecasting, analysis of business performance, etc. Meet Patrick. With a Bachelor of Arts in philosophy, politics, and economics and a background as a debt capital markets analyst at RBS Securities, Patrick is now a retail finance and strategy manager for Warby Parker in New York City. He is responsible for retail financial planning and analysis and supporting the development of the company’s store roll-out strategy. He spends his days deep in Excel managing the stores’ profit and losses and KPIs, developing models of future performance, digging into model variance, and analyzing market development. Currently he spends about 60% of his time on reporting and the remainder on analysis, but this is shifting toward analysis as his access, comfort, and skills with the company’s business intelligence tools improve.
Data Visualization Specialists
People with a strong design aesthetic who create infographics, dashboards, and other design assets. They may also code in technologies such as JavaScript, CoffeeScript, CSS, and HTML working with data-visualization libraries, such as D3 (a very powerful and beautiful visualization library covered in Scott Murray’s Interactive Data Visualization for the Web (O’Reilly) and HTML5.
Meet Jim (Jim V in Figure 4-1). After obtaining a master’s degree in computer science, specializing in bioinformatics and machine learning, Jim worked for Garmin developing GUIs for its GPS devices and thereafter at a biological research facility analyzing large-scale sequence data. It was there that he discovered D3 and began to blog about it, developing clear, instructive tutorials. He is now a data-visualization engineer and data scientist at Nordstrom’s data lab in Seattle. Using a mix of Ruby, some Python, and R (especially the packages ggplot2 and dplyr), he splits his time between supporting personalization and recommendation systems and visualizing data, with the primary audience being employees in other teams.
In larger organizations, you may find additional specialized roles such as those who solely generate reports, or who specialize in using a particular business intelligence tool. Others may focus only on big data technologies, such as Hadoop or Spark.
As you can see, there is a huge amount of overlap of these roles and terms. Most are munging data with some sort of SQL-like language. Some code more than others. Many roles involve building statistical models, often with SAS or R. Most involve a mix of both reporting and analysis.
Analytics Is a Team Sport
Analytics is a team sport. A well-oiled, data-driven organization is going to have both a range of analytical personnel with different roles and also personnel with complementary skills. It needs to consider the “portfolio” of skills in the team and the profile of new hires that would work best to flesh out and strengthen missing or weak areas in that team.
For instance, Figure 4-1 shows the team profile of Nordstrom’s data lab in 2013. You can easily spot the strongest mathematicians and statisticians in the team (Elissa, Mark, and Erin), the strongest developers (David and Jason W), and their data-visualization expert, Jim V, profiled earlier. I asked Jason Gowans, the director of the lab, what he thinks about when hiring a new addition. “The first is that we’re proponents of the Jeff Bezos two-pizza rule,” he said. “Therefore, it’s unlikely we’ll be much bigger than we currently are. We think that helps us stay focused on what we think are the big opportunities. The second is that each member brings something unique to the team and can help everyone else ‘level up’.”
They made a smart move early in the team’s history to hire a strong data-visualization guy, something that many teams leave until later. Having beautiful, polished proof-of-concept data products helped the team gain traction and acceptance within the broader organization. “Jim has been a key ingredient in our ability to generate enthusiasm for our work and really bring it to life with his datavisualization skills,” Jason said.
Data scientists, often coming from an academic background, are especially T-shaped. When they have two dominant areas, they are termed Pi-shaped. You can think of hiring and team formation as analytics Tetris.
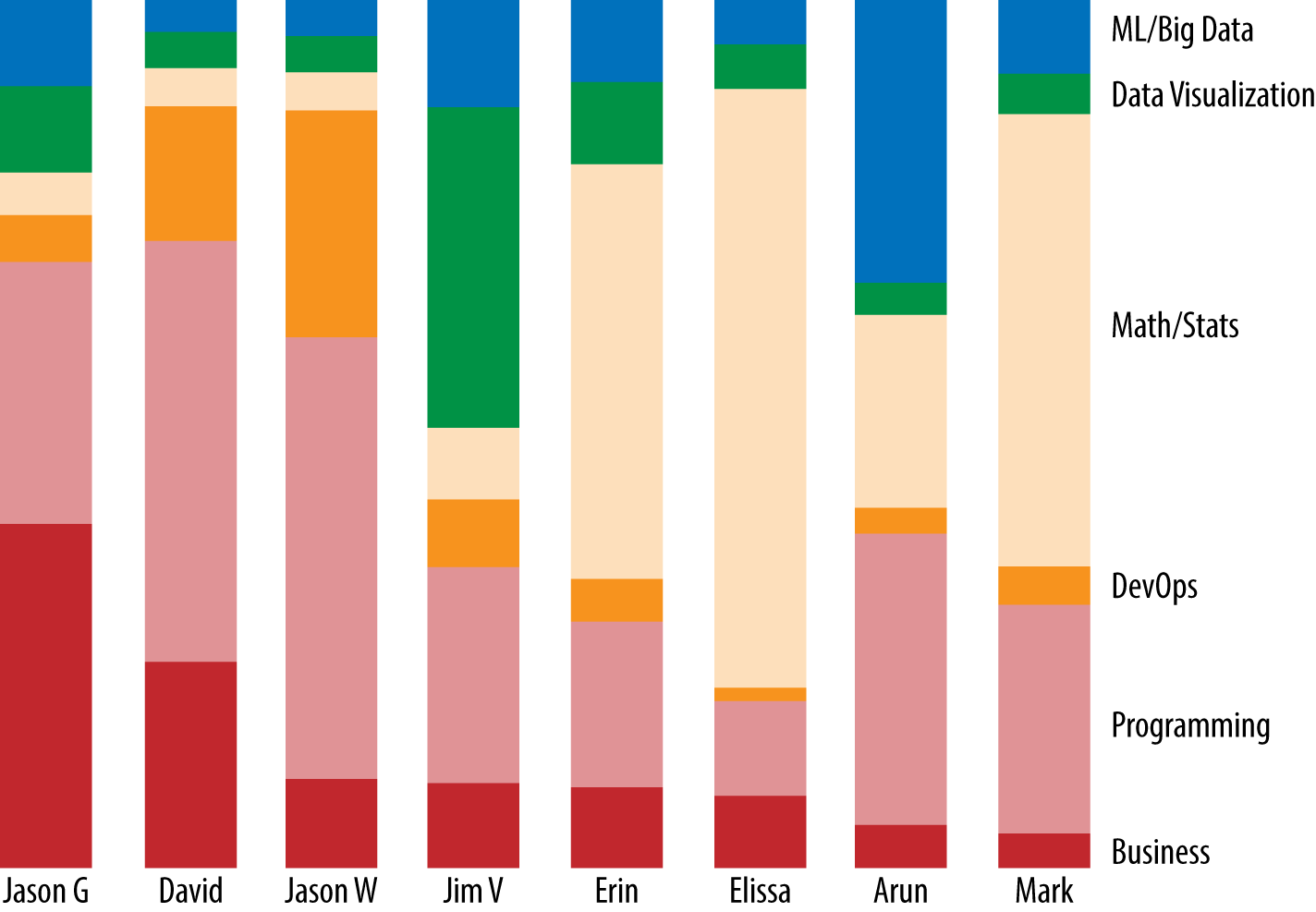
Figure 4-1. Team profile of the Nordstrom data lab (as of Strata 2013). ML = machine learning. Devops is a relatively new term arising from agile software development and represents a mix of IT, system administration, and software engineering.
A 2012 survey of hundreds of self-reporting data personnel by Harris et al. covered five skill groups:
- Business
- Math/operations research
- Machine learning/big data
- Programming
- Statistics
They identified four clusters of roles:
- Data business people
-
“Quite T-shaped with top skills in Business, and moderate skills elsewhere.”
- Data researchers
-
Deep in statistics and less broad with low rankings in machine learning/big data, business, and programming.
- Data developers
-
Pi-shaped with strong programming skills and relatively strong machine learning/big data skills and moderate skills in the other three groups.
- Data creatives
-
The least T-shaped group “who were, on average neither ranked the strongest nor the weakest in any skill group.”
Their average profiles are shown in Figure 4-2. It is easy to spot the wide variation among the four types.
These four roles map imprecisely onto the analyst job titles (Table 4-1); organizations with more personnel and complexity may have a greater number of defined roles; smaller operations will likely have fewer people wearing more hats. It’s also worth noting that while Harris et al. found data creatives “neither strongest nor weakest in any skill group,” they didn’t categorize visualization and communication as a skill group, and it is a vital one for a working team. One might also note that as a data-science problem, this is a weakness of surveys: they are limited to the categories that the survey designers envision. In this case, there was domain knowledge to realize that data creatives were part of successful teams, but not exactly clarity about what they added.
| Data businessperson | Data creative | Data developer | Data researcher |
|---|---|---|---|
| Business analysts | Data-visualization specialists | Data scientists | Statisticians |
| Data analysts | Data engineers | Quants | |
| Accountants and Financial Analysts |
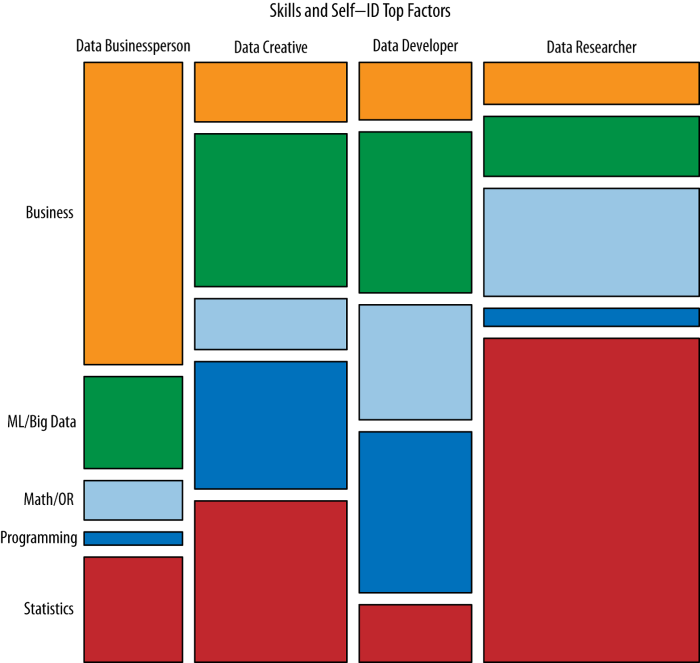
Figure 4-2. The skill profile of the four clusters of respondents (Figure 3-3 from Harris et al., 2013).
Ideally, when hiring, managers have to think at three levels:
- Individual level
-
Is this person a good fit? Do they possess the skills, potential, and drive that we seek?
- Team level
-
Does this person complement the rest of the team and fill in missing holes or shore up a weak spot?
- Work level
-
How does the team profile match the work that is required? That is, what is the team profile that best fits what we are trying to achieve? For instance, work that focuses primarily on financial predictive models may have a different optimal staffing skill set than work focused on optimizing customer service.
Skills and Qualities
What are the traits that make for a great analyst?2
- Numerate
-
They don’t have to have a Ph.D. in math or stats, but they should at least be comfortable with descriptive statistics (median, mode, quartiles, etc.; see Chapter 5) and be willing to learn more.
- Detail-oriented and methodical
-
If these numbers, reports, and analyses are flowing up to senior management to make a major business decision, they had better be correct. The analysts must be of a “measure twice, cut once” ilk.
- Appropriately skeptical
-
Great analysts cultivate a good “spidey sense” of when something seems wrong in the raw or aggregated data or the analysis itself. First, they will proactively think through the range of values that would make sense. Second, they will proactively question the validity of the data and double-check the source data and the calculations when a metric is higher or lower than expected.
- Confident
-
Analysts not only need confidence to present their findings to groups of (senior) colleagues, but if the findings are surprising or expose gross inefficiencies, their data and analysis may be brought into question. They have to have confidence in their work to stand by it.
- Curious
-
Part of an analyst’s role is seek actionable insights and so they need to be curious to always be developing hypotheses or questioning potentially interesting aspects of the data.
- Good communicators and storytellers
-
An analyst’s work is worthless if it is not conveyed well to decision makers and business owners who can act upon the recommendations. They have to tell a compelling, coherent story around the data and the findings. Thus, they must have sharp written, verbal, and data-visualization skills. (More on this in Chapter 7.)
- Patient
-
There is a lot that is outside an analyst’s direct control. That includes the accuracy or availability of the raw data source, missing data, changing requirements, or hidden biases in the data revealed only late in an analysis that may mean they have to scrap or redo their analyses. Analysts need patience.
- Data lovers
-
In the same way that many computer programmers just love to code and the domain is almost irrelevant, some people just love data as a resource, a way to make sense of their world and make an impact. They just love to dig in. Hire those people.
- Life-learners
-
This isn’t specific to analysts, but those who love to learn, the ones who are always reading the latest articles and textbooks and taking classes to develop their knowledge and skills, will do well.
- Pragmatic and business-savvy
-
You have to focus on the right questions. It can be all to easy to get sucked down a rabbit hole and spend too much time digging into a sub-1% edge case that has no real impact to the business. Like good editors, they have to keep the bigger picture in mind and know when to kill a story and move onto something else that is a better use of time.
I asked Daniel Tunkelang, head of search quality at LinkedIn, what he seeks when hiring analysts:
I look for three things in data analysts/scientists. First, they need to be smart, creative problem solvers who not only have analytical skills but also know how and when to apply them. Second, they have to be implementers and show that they have both the ability and passion to build solutions using the appropriate tools. Third, they have to have enough product sense, whether it comes from instinct or experience, to navigate in the problem space they’ll be working in and ask the right questions.
Ken Rudin, head of analytics at Facebook, says:
You can use science and technology and statistics to figure out what the answers are but it is still an art to figure out what the right questions are...It is no longer sufficient to hire people who have a Ph.D. in statistics. You also need to make sure that the people that you have have “business savvy.” Business savvy, I believe is becoming one of the most critical assets, one of the most critical skills, for any analyst to have.
How do you figure out if a potential analyst that you are looking at has business savvy? When you interview them, don’t focus just on how do we calculate this metric. Give them a case study, a business case study from your own business, and ask them, “in this scenario, what are the metrics you think would be important to look at?” That’s how you can get at that.
Just One More Tool
In terms of practical skills, it goes without saying that the majority of analysts around the world use Microsoft’s Word, Excel, and PowerPoint as their major workhorses. They are very powerful tools. It is surprising, however, how a few additional tools can make a big difference in terms of productivity.
Tip
This section is meant as a challenge to two primary audiences. If you are an analyst, challenge yourself to learn just one more tool or utility in the next month or quarter. If you are a manager of analysts, get them to challenge themselves in this manner. Check in and find out how much of an impact that has had. You will be surprised.
Here are a few areas to consider.
Exploratory Data Analysis and Statistical Modeling
R is an increasingly popular environment for statistical computing and it has exceptional data-visualization libraries (such as ggplot2). For instance, you can read in a CSV and visualize the relationship among all possible pairs of variables in just two commands:
data<-read.csv(filename.csv);pairs(data)
Figure 4-3 shows the output of those commands. In the second panel of the top row, we can see the relationship between sepal width (x-axis) versus sepal length (y-axis) of iris flowers.

Figure 4-3. This is the output of the command pairs(iris) in R. Iris is a well-known dataset, collected by Edgar Anderson but made famous by the statistician R. A. Fisher, consisting of measurements of 50 samples of three iris flower species. The correlations among the variables and the differences among the three species is obvious when you are able to view the relationships holistically like this.
As such, it can be invaluable for rapid exploratory data analysis. (The nonopen SAS and SPSS are popular and powerful, too.) There are about 6,700 packages for all sorts of data types, models, domains, and visualizations, and it is free and open source.3 If you already know R, then learn a new R package and broaden your skill set.
Database Queries
While Excel can be incredibly powerful, it does have scaling issues: at a certain size of data and number of VLOOKUPS, it can bring your computer to its knees. It is for this reason that SQL is a valuable tool in any analyst’s toolkit. SQL is a transferable skill; and while there are some small differences in the language among databases (such as MySQL, PostgreSQL, and Access), it is pretty much standardized, so once you know SQL you can switch among different relational databases easily. You can then query data in a scalable manner (crunch millions of rows), can share queries with colleagues (sharing small text queries and not huge chunks of raw data), and you have a process that is repeatable (you can rerun analyses easily).
There are many books and offline and online courses to help you get started in SQL. One free online course that I would recommend is W3Schools’ SQL Tutorial because you can run queries in the browser itself. Another approach to getting started is to install a database on your local machine. Installing and configuring mainstream databases, such as MySQL and PostgreSQL, can be tricky to install. Thus, I would highly recommend starting out with SQLite4—a lot of applications on your smartphone are using SQLite to store application data. This is free, almost trivial to install, saves your data to a single transportable file, and will get you up and running writing SQL queries in minutes.
In case you are worried that this is an old technology that will soon be superseded by a shiny new approach, in the O’Reilly 2014 Data Science Salary Survey, King and Magoulas remark “SQL was the most commonly used tool...Even with the rapid influx of new data technology, there is no sign that SQL is going away.”
File Inspection and Manipulation
If the analytics team must work with large or many raw datafiles, then someone—it doesn’t have to be everyone because analytics is a team sport—should pick up some simple Unix command-line skills for file filtering and manipulation. Alternatively, a scripting language, such as Python, will provide those tools and much more.
See Chapter 5 for a fuller discussion.
Which tool or utility to learn depends on your current skill set and its weak spot(s). However, everyone has a weak spot. Take up the challenge.
If you need further incentive, O’Reilly’s 2013 Data Science Salary Survey from attendees from two large Strata conferences in 2012 and 2013 found the following:
Salaries positively correlated with the number of tools used by respondents. The average respondent selected 10 tools and had a median income of $100k; those using 15 or more tools had a median salary of $130k.
This was more clearly and starkly presented in their 2014 survey (Figure 4-4).
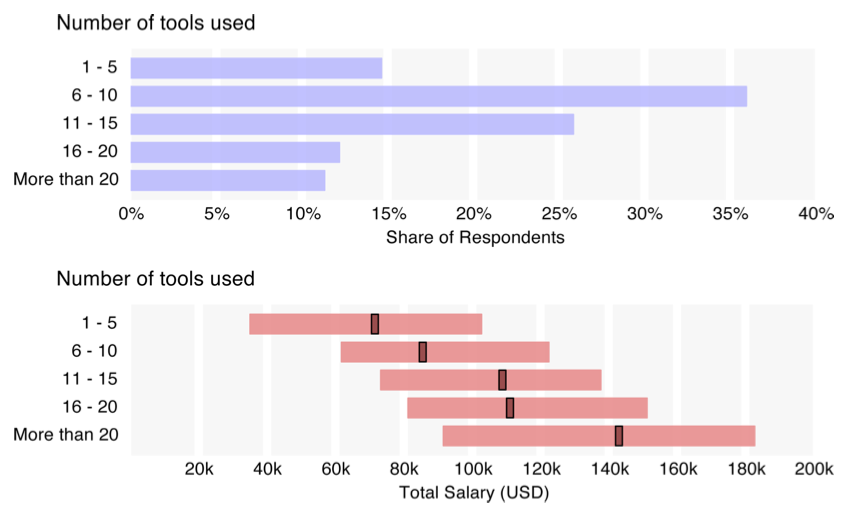
Figure 4-4. The relationship between number of different tools versus data science salary. This is Figure 1-13 of the 2014 O’Reilly Data Science Salary Survey.
In 2013, they further concluded:
It seems very likely that knowing how to use tools such as R, Python, Hadoop frameworks, D3, and scalable machine learning tools qualifies an analyst for more highly paid positions—more so than knowing SQL, Excel, and RDB [relational database] platforms. We can also deduce that the more tools an analyst knows, the better: if you are thinking of learning a tool from the Hadoop cluster, it’s better to learn several.
Finally, the 2014 survey shows about a $15,000 bump for coding versus noncoding analysts. If you are a noncoding analyst, do yourself a favor and learn to code!
Analytics-org Structure
Having considered the types of analyst roles and skills, I now consider how they are organized in the context of the larger organization.
First, let’s consider the two common extremes.
Centralized
There is a central analytics team to which all analysts report. There are many advantages. First, the team can standardize skills, training, and tooling, and they can share resources and reduce software license costs. Second, they can more easily promote the use of analytics and advanced analytics within the organization. Third, analysts can communicate easily, learn from or mentor each other, and feel that they are part of a like-minded team. Fourth, there is, or can be, the perception of greater objectivity as their success or rewards are unlikely to be aligned with the success of the projects that they are analyzing. Finally, they can help promote master data sources as single sources of truth. On the downside, they can be somewhat removed from the business owners and their goals, they tend to be very reactive to requests for work5,6 they can be more bureaucratic. As Piyanka Jain notes, “everything needs to get into the pipeline, and get prioritized, and get resources allocated against it.”7
Decentralized
A decentralized analytical organization embeds the analysts in individual teams. Those analysts report to those teams and share their goals. In other words, they live the goals, reports, and metrics of those teams. The downside is that they can be somewhat removed from other analysts. There is the potential for redundancy of effort, divergence of tools, skills, metric definitions, and implementation. There can also be a lack of communication and sharing among analysts from different teams. The decentralized model is the most common, accounting for 42% of respondents in one survey, a factor that Davenport et al. (p. 108) consider reflects “analytics immaturity.” They do not explicitly clarify or defend that position, but my interpretation is that it is difficult to excel at some of the higher levels analytics, such as an operations research department working on hard optimization or predictive problems, without some more centralized coordination, expertise, and oversight.
There are many pros and cons of these two structures (summarized in Table 4-2). Being part of a larger, centralized analyst organization, analysts have more local support, mentorship, and a clearer career path. However, in a decentralized structure, the line of business manager has dedicated resources and presumably a faster turnaround time.
| Pro | Centralized | Decentralized |
|---|---|---|
| Clear career path | ✓ | |
| Direct, full-time access | ✓ | |
| Faster turnaround time | ✓ | |
| Greater redundancy of domain knowledge | ✓ | |
| Standardized toolset and training | ✓ | |
| Standardized metrics: numbers that agree | ✓ | |
| Less bureaucracy | ✓ | |
| (Perceived) objectivity | ✓ | |
| Greater domain knowledge | ? | ? |
Sixty-three percent more transformed organizations than aspirational organizations (think back to Chapter 1) “use a centralized enterprise unit as the primary source of analytics.” As before, there are confounding variables at play—in particular, company size and total number of analysts—because transformed organizations are also more likely to be using analytics in the business units, too.8
One should expect that analysts in the decentralized organization would build up greater domain knowledge, such as deeply understanding the voice of the customer data, analytical processes, and metrics. Such concentration of knowledge may represent a risk, however, to the enterprise as a whole if those few individuals leave. (In a centralized organization, there will more likely be redundancy of domain knowledge as analysts switch among different lines of business.) This may mean that domain knowledge is actually less, on average, in a decentralized structure if those analysts are frequently leaving to be replaced by novices that require multiyear training from scratch.
Interestingly, Jeb Stone9 argues that in a centralized organization with a few standard technologies,
to increase value to the organization, an analyst should master these additional technologies, cross-train on these specific lines of business, and approach the level and quality of work already benchmarked by senior analysts. Without a career path, your analysts are highly incented to learn in-demand technology on your dime—whether or not your organization has a need for it—and then jump ship to an employer who will compensate them for that skill. Perhaps even more to the point: rock-star analysts will avoid employers with a decentralized Analytics function, because they know it’ll take them longer to come up to speed and that there is likely no performance incentive program specific to their accomplishments.
In an attempt to find a structure that draws as many pros and minimizes the cons, an intermediate form exists, called the hybrid model. This model, such as employed at Facebook, has a centralized analytics team, and thus you have the benefits of standardized training, tooling, and the like, but the analysts physically sit with the different business teams and moreover share those teams’ goals. Thus, you have the benefit of close alignment and analytical standards. The downside is that you introduce a situation in which analysts may be reporting to more than one manager, one from the business side and one from the analytics side. This introduces the very real potential of conflicting or confusing messages.
When you have a decentralized model, you need some way to bring the analysts together to develop common skills, to attend training on tooling, discuss data sources, metrics, analyses being worked upon, and so on. One approach, and one that we employ at Warby Parker, is to form an analysts’ guild, “an organized group of people who have joined together because they share the same job or interest.” It gets analysts from different teams, and in our case from different buildings, talking to each other, discussing issues, and doing show and tells. It also allows my data team to provide training on business intelligence tools and statistics.
A guild such as this makes it more matrix-like but does require buy-in from the managers or department heads to which those analysts report and/or from more senior management. Analysts need to be encouraged by their managers to break away from their work to attend and participate in the guild.
Other organizational structures10,11 more common in larger organizations, include:
- Consulting
-
In some organizations, the centralized model is modified such that analysts are hired out to departments with appropriate chargebacks, in a consultative structure. With poor executive leadership, there is the potential downside that the analysts follow the money or the most vocal executives and that they are not necessarily working on projects that would deliver the most value to the organization.
- Functional
-
A form of serial centralization in which a central group sits within one functional business unit, primarily serving that unit, but may provide some services to other parts of the organization. They may then migrate en masse to another business unit as the need arises.
- Center of excellence
-
This is similar to the hybrid structure but on a larger scale and houses a set of analytical experts, such as statisticians, in the central hub. Thus, you have analytics being performed both in the individual units and from central staff.
Table 4-3 summarizes the different organizational structures and lists some example organizations of each type. However, it should be stressed that these labels identify idealized structures, and in reality, there are very blurry lines among them, and many intermediate forms exist. For instance, Warby Parker is primarily a decentralized form with analysts reporting to line-of-business managers only, but there are some elements of a center of excellence model with a central data team hosting data scientists and providing some support in terms of advanced analytics (as well as business intelligence tooling, analyst training, and driving standards). That structure, however, is expected to change as the analytics organization matures.
| Organizational structure | Analysts report to or share goals with | Examples | |
|---|---|---|---|
| Central analyst org | Business owners | ||
| Centralized | ✓ | Mars, Expedia, One Kings Lane | |
| Decentralized | ✓ | PBS, Dallas Mavericks | |
| Hybrid/embedded | ✓ | ✓ | Facebook, Ford, Booz Allen Hamilton |
| Functional | ✓ | Fidelity | |
| Consulting | ✓ | eBay, United Airlines | |
| Center of excellence | ✓ | ✓ | Capital One, Bank of America |
There is no answer as to “What is the best structure?” It depends. It depends upon the organization size and industry. For instance, an analytical center of excellence form makes little sense when there are, say, five analysts. They are more prevalent in organizations with more than 25,000 staff. One form may make the most sense at one point, but as the company scales, it outgrows it and may need a re-org to a more appropriate form.
However, based on an Accenture survey and analysis of more than 700 analysts,12 Davenport et al. (p. 106) do claim:
We think the centralized and center of excellence models (or a federated model combining elements of both) offer the greatest potential benefit for organizations ready to take an enterprise approach to analytics. Analysts in a centralized or center of excellence model have significantly higher levels of engagement, job satisfaction, perceived organizational support and resources, and intention to stay than decentralized analysts or those who work in consulting units.13
In Chapter 11, we’ll discuss where these teams sit in the larger organizational structure and the C-suite executives that they roll up to. Before, that, however, let’s consider more closely what analysts do: analyze.
1 Conway, D., “The Data Science Venn Diagram,” September 30, 2010.
Anderson, C., “What is a data scientist?” December 3, 2012.
2 Stephen Few’s Now You See It (Analytics Press) has a good discussion of this topic, pp. 19–24.
3 Great open source tools for analytics can be found in Data Analysis with Open Source Tools by P. K. Janert (O’Reilly).
4 One introductory book is Using SQLite by J. A. Kreibich (O’Reilly).
5 “Ken Rudin ‘Big Impact from Big Data',” October 29, 2013, video clip, YouTube.
6 Davenport, T. H., and J. G. Harris. Analytics at Work. Boston: Harvard Business Press, 2007.
7 Jain, P., “To Centralize Analytics or Not, That is the Question,” Forbes, February 15, 2013.
8 LaValle, S., M. S. Hopkins, E. Lesser, R. Shockley, and N. Kruschwitz, “Analytics: the New Path to Value,” MIT Sloan Management Review 52, no. 2 (2010): Figure 9.
9 Stone, J., “Centralized vs Decentralized Analytics: All You Need To Know,” April 22, 2012.
10 Davenport, T. H., and J. G. Harris. Analytics at Work. Boston: Harvard Business Press, 2007.
11 Khalil, E., and K. Wood, “Aligning Data Science – Making Organizational Structures Work,” (Tysons Corner, VA: Booz Allen Hamilton, Inc., 2014).
12 Harris, J. G., E. Craig, and H. Egan, “How to Organize Your Analytical Talent,” (Dublin: Accenture Institute for High Performance, 2009).
13 Davenport, T. H., Harris, J. G., and Morison, R. Competing on Analytics. Boston: Harvard Business Press, 2010.
Get Creating a Data-Driven Organization now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

