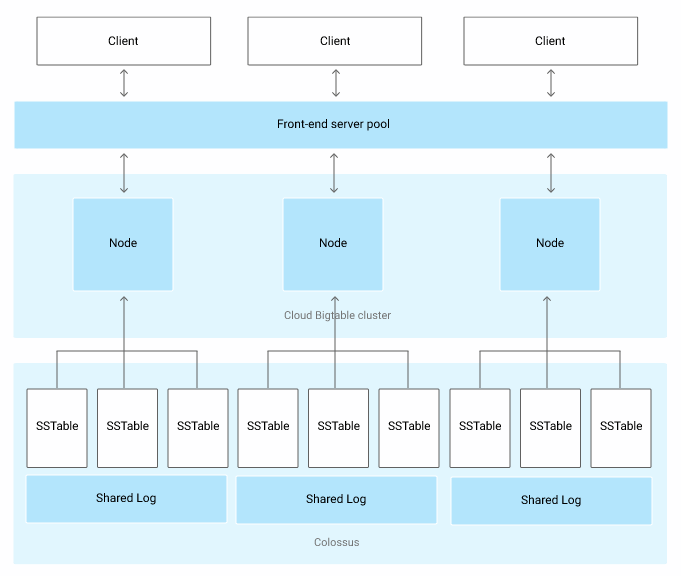
Now we will be studying the Cloud BigTable architecture. When we make a request, all the requests will go through a frontend server before they are sent to a cloud bigtable node.
These nodes are then organized into a Cloud Bigtable Cluster. This Cloud Bigtable Cluster belongs to the Cloud Bigtable instance, which is a container for the cluster. Every node in the cluster handles a subset of requests to the cluster made by the client.
If you are willing to utilize the maximum throughput of the cluster and a number of simultaneous requests, then adding nodes is a good option:
Just like we have Apache HBase sharded ...

