The drawbacks of k-means
k-means is one of the most popular clustering algorithms due to its relative ease of implementation and the fact that it can be made to scale well to very large datasets. In spite of its popularity, there are several drawbacks.
k-means is stochastic, and does not guarantee to find the global optimum solution for clustering. In fact, the algorithm can be very sensitive to outliers and noisy data: the quality of the final clustering can be highly dependent on the position of the initial cluster centroids. In other words, k-means will regularly discover a local rather than global minimum.
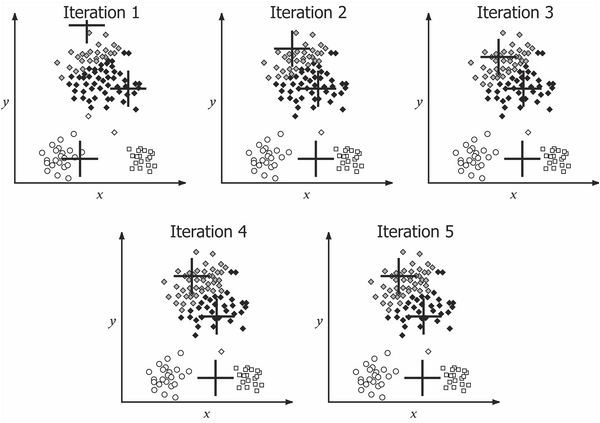
The preceding diagram illustrates how ...
Get Clojure for Data Science now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

