Chapter 1. Primitive Data
1.0. Introduction
Clojure is a fantastic language for tackling hard problems. Its simple tools let us software developers build up layer upon layer of abstractions until we’ve tackled some of the world’s most difficult problems with ease. Like chemistry, every great Clojure program boils down to simple atoms—these are our primitives.
Standing on the shoulders of the Java giants from days of yore, Clojure leverages a fantastic array of battle-hardened types present in the Java Virtual Machine (JVM):[1] strings, numeric types, dates, Universally Unique Identifiers (UUIDs)—you name it, Clojure has it all. This chapter dives into the primitives of Clojure and how to accomplish common tasks.
Strings
Almost every programming language knows how to work with and deal in strings. Clojure is no exception, and despite a few differences, Clojure provides the same general capabilities as most other languages. Here are a few key differences we think you should know about.
First, Clojure strings are backed by Java’s UTF-16 strings. You don’t need to add comments to files to indicate string encoding or worry about losing characters in translation. Your Clojure programs are ready to communicate in the world beyond A–Z.
Second, unlike languages like Perl or Ruby that have extensive string
libraries, Clojure has a rather Spartan built-in string
manipulation library. This may seem odd at first, but Clojure prefers
simple and composable tools; all of the plethora of collection-modifying functions in Clojure are perfectly capable of accepting
strings—they’re collections too! For this reason, Clojure’s string
library is unexpectedly small. You’ll find that small set of very
string-specific functions in the clojure.string namespace.
Clojure also embraces its host platform (the JVM) and does not
duplicate functionality already adequately performed by Java’s
java.lang.String class. Using Java interop in Clojure is not a
failure—the language is designed to make it straightforward, and
using the built-in string methods is usually just as easy as invoking
a Clojure function.
We suggest you “require as” the clojure.string namespace when you
need it. Blindly :use-ing a namespace is always annoying,[2] and often results in
collisions/confusion. Prefixing everything with clojure.string is
kind of odd, so we prefer to alias it to str or s:
(require'[clojure.string:asstr])(str/blank?"");; -> true
Numeric Types
The veneer between Clojure and Java is a little thicker over the numeric types. This isn’t necessarily a bad thing, though. While Java’s numeric types can be extremely fast or arbitrarily precise, numerics overall don’t have the prettiest set of interfaces to work with. Clojure unifies the various numeric types of Java into one coherent package, with clear escape hatches at every turn.
The recipes on numeric types in this chapter will show you how to work with these hatches, showing you how to be as fast or precise or expressive as you desire.
Dates
Dates and times have a long and varied history in the Java
ecosystem. Do you want a Date, Time, DateTime, or Calendar?
Who knows. And why are these APIs all so wonky? The recipes in this
chapter should hopefully illuminate how and when to use the
appropriate built-in types and when to look to an external library
when built-ins aren’t sufficient (or are just too darned difficult to
use).
1.1. Changing the Capitalization of a String
Solution
Use clojure.string/capitalize to capitalize the first character in a string:
(clojure.string/capitalize"this is a proper sentence.");; -> "This is a proper sentence."
When you need to change the case of all characters in a string, use
clojure.string/lower-case or clojure.string/upper-case:
(clojure.string/upper-case"loud noises!");; -> "LOUD NOISES!"(clojure.string/lower-case"COLUMN_HEADER_ONE");; -> "column_header_one"
Discussion
Capitalization functions only affect letters. While the functions
capitalize, lower-case, and upper-case may modify letters,
characters like punctuation marks or digits will remain
untouched:
(clojure.string/lower-case"!&$#@#%^[]");; -> "!&$#@#%^[]"
Clojure uses UTF-16 for all strings, and as such its definition of what a letter is is liberal enough to include accented characters. Take the phrase “Hurry up, computer!” which includes the letter e with both acute (é) and circumflex (ê) accents when translated to French. Since these special characters are considered letters, it is possible for capitalization functions to change case appropriately:
(clojure.string/upper-case"Dépêchez-vous, l'ordinateur!");; -> "DÉPÊCHEZ-VOUS, L'ORDINATEUR!"
See Also
-
The
clojure.stringnamespace API documentation -
The
java.lang.StringAPI documentation
1.2. Cleaning Up Whitespace in a String
Solution
Use the clojure.string/trim function to remove all of the whitespace
at the beginning and end of a string:
(clojure.string/trim" \tBacon ipsum dolor sit.\n");; -> "Bacon ipsum dolor sit."
To manage whitespace inside a string, you need to get more creative. Use
clojure.string/replace to fix whitespace inside a string:
;; Collapse whitespace into a single space(clojure.string/replace"Who\t\nput all this\fwhitespace here?"#"\s+"" ");; -> "Who put all this whitespace here?";; Replace Windows-style line endings with Unix-style newlines(clojure.string/replace"Line 1\r\nLine 2""\r\n""\n");; -> "Line 1\nLine 2"
Discussion
What constitutes whitespace in Clojure? The answer depends on the
function: some are more liberal than others, but you can safely assume
that a space ( ), tab (\t), newline (\n), carriage return (\r), line
feed (\f), and vertical tab (\x0B) will be treated as whitespace.
This set of characters is the set matched by \s in Java’s regular
expression implementation.
Unlike Ruby and other languages that include string manipulation
functions in the core namespace, Clojure excludes its clojure.string
namespace from clojure.core, making it unavailable for naked use. A
common technique is to require clojure.string as a shorthand like
str or string to make code more terse:
(require'[clojure.string:asstr])(str/replace"Look Ma, no hands""hands""long namespace prefixes");; -> "Look Ma, no long namespace prefixes"
You might not always want to remove whitespace from both ends of a
string. For cases where you want to remove whitespace from just the left-
or righthand side of a string, use clojure.string/triml or
clojure.string/trimr, respectively:
(clojure.string/triml" Column Header\t");; -> "Column Header\t"(clojure.string/trimr"\t\t* Second-level bullet.\n");; -> "\t\t* Second-level bullet."
1.3. Building a String from Parts
Solution
Use the str function to concatenate strings and/or values:
(str"John"" ""Doe");; -> "John Doe";; str also works with vars, or any other values(deffirst-name"John")(deflast-name"Doe")(defage42)(strlast-name", "first-name" - age: "age);; -> "Doe, John - age: 42"
Use apply with str to concatenate a collection of values into a
single string:
;; To collapse a sequence of characters back into a string(apply str"ROT13: "[\W\h\y\v\h\f\\P\n\r\f\n\e]);; -> "ROT13: Whyvhf Pnrfne";; Or, to reconstitute a file from lines (if they already have newlines...)(deflines["#! /bin/bash\n","du -a ./ | sort -n -r\n"])(apply strlines);; -> "#! /bin/bash\ndu -a ./ | sort -n -r\n"
Discussion
Clojure’s str is like a good Unix tool: it has one job, and it does it
well. When provided with one or more arguments, str invokes Java’s
.toString() method on its argument, tacking each result onto
the next. When provided nil or invoked without arguments, str will
return the identity value for strings, the empty string.
When it comes to string concatenation, Clojure takes a fairly hands-off
approach. There is nothing string-specific about (apply str ...). It
is merely the higher-order function apply being used to emulate
calling str with a variable number of arguments.
This apply:
(apply str["a""b""c"])
is functionally equivalent to:
(str"a""b""c")
Since Clojure injects little opinion into joining strings, you’re free
to inject your own with the plethora of manipulating functions
Clojure provides. For example, take constructing a comma-separated value (CSV) from a header and
a number of rows. This example is particularly well suited for apply,
as you can prefix the header without having to insert it onto the front
of your rows collection:
;; Constructing a CSV from a header string and vector of rows(defheader"first_name,last_name,employee_number\n")(defrows["luke,vanderhart,1","ryan,neufeld,2"])(apply strheader(interpose"\n"rows));; -> "first_name,last_name,employee_number\nluke,vanderhart,1\nryan,neufeld,2"
apply and interpose can be a lot of ceremony when you’re not doing
anything too fancy. It is often easier to use the clojure.string/join
function for simple string joins. The join function takes a collection
and an optional separator. With a separator, join returns a string
with each item of the collection separated by the provided separator.
Without, it returns each item squashed together, similar to what
(apply str coll) would return:
(deffood-items["milk""butter""flour""eggs"])(clojure.string/join", "food-items);; -> "milk, butter, flour, eggs"(clojure.string/join[1234]);; -> "1234"
See Also
- Recipe 1.6, “Formatting Strings”
-
The
clojure.stringnamespace API documentation -
The
java.lang.StringAPI documentation
1.4. Treating a String as a Sequence of Characters
Solution
Use seq on a string to expose the sequence of characters representing it:
(seq"Hello, world!");; -> (\H \e \l \l \o \, \space \w \o \r \l \d \!)
You don’t need to call seq every time you want to get at a string’s
characters, though. Any function taking a sequence will naturally
coerce a string into a sequence of characters:
;; Count the occurrences of each character in a string.(frequencies(clojure.string/lower-case"An adult all about A's"));; -> {\space 4, \a 5, \b 1, \d 1, \' 1, \l 3, \n 1, \o 1, \s 1, \t 2, \u 2};; Is every letter in a string capitalized?(defnyelling?[s](every?#(or(not(Character/isLetter%))(Character/isUpperCase%))s))(yelling?"LOUD NOISES!");; -> true(yelling?"Take a DEEP breath.");; -> false
Discussion
In computer science, “string” means “sequence of characters,”
and Clojure treats strings exactly as such. Because Clojure strings
are sequences under the covers, you may substitute a string anywhere a
collection is expected. When you do so, the string will be interpreted
as a collection of characters. There’s nothing special about (seq
string). The seq function is merely returning a seq of the
collection of characters that make up the string.
More often than not, after you’ve done some work on the characters
within a string, you’ll want to transform that collection back into a
string. Use apply with str on a collection of characters to
collapse them into a string:
(apply str[\H\e\l\l\o\,\space\w\o\r\l\d\!]);; -> "Hello, world!"
1.5. Converting Between Characters and Integers
Problem
You need to convert characters to their respective Unicode code points (as integer values), or vice versa.
Solution
Use the int function to convert a character to its integer value:
(int\a);; -> 97(int\ø);; -> 248(int\α); Greek letter alpha;; -> 945(int\u03B1); Greek letter alpha (by code point);; -> 945(map int"Hello, world!");; -> (72 101 108 108 111 44 32 119 111 114 108 100 33)
Use the char function to return a character corresponding to the
code point specified by the integer:
(char97);; -> \a(char125);; -> \}(char945);; -> \α(reduce#(str%1(char%2))""[115101991141011163210910111511597103101115]);; -> "secret messages"
Discussion
Clojure inherits the JVM’s robust Unicode support. All strings are UTF-16 strings, and all characters are Unicode characters. Conveniently, the first 256 Unicode code points are identical to ASCII, which makes standard ASCII text easy to work with. However, Clojure (like Java) does not actually privilege ASCII in any way; the 1:1 correspondence between characters and integers indicating code points continues all the way up through the Unicode space.
For example, the expression (map char (range 0x0410 0x042F)) prints
out all the Cyrillic capital letters, which happen to lie on that
range on the Unicode spectrum:
(\А\Б\В\Г\Д\Е\Ж\З\И\Й\К\Л\М\Н\О\П\Р\С\Т\У\Ф\Х\Ц\Ч\Ш\Щ\Ъ\Ы\Ь\Э\Ю)
The char and int functions are useful primarily for coercing a
number into an instance of either java.lang.Integer or
java.lang.Character. Both Integers and Characters are,
ultimately, encoded as numbers, although Characters support
additional text-related methods and cannot be used in mathematic
expressions without first being converted to a true numeric type.
See Also
- Unicode Explained, by Jukka K. Korpela (O’Reilly), for truly comprehensive coverage of how Unicode and internationalization works
- Recipe 1.4, “Treating a String as a Sequence of Characters”, for details on working with the characters that constitute a string
- Recipe 1.15, “Parsing Numbers”
1.6. Formatting Strings
Solution
The quickest method for formatting values into a string is the str function:
(defme{:first-name"Ryan",:favorite-language"Clojure"})(str"My name is "(:first-nameme)", and I really like to program in "(:favorite-languageme));; -> "My name is Ryan, and I really like to program in Clojure"(apply str(interpose" "[12.000(/31)(/49)]));; -> "1 2.0 3 4/9"
With str, however, values are inserted blindly, appearing in their
default .toString() appearance. Not only that, but it can sometimes be
difficult to look at a str form and interpret what the intended
output is.
For greater control over how values are printed, use the format function:
;; Produce a filename with a zero-padded sortable index(defnfilename[namei](format"%03d-%s"iname));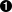
(filename"my-awesome-file.txt"42);; -> "042-my-awesome-file.txt";; Create a table using justification(defntableify[row](applyformat"%-20s | %-20s | %-20s"row));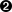
(defheader["First Name","Last Name","Employee ID"])(defemployees[["Ryan","Neufeld",2]["Luke","Vanderhart",1]])(->>(concat[header]employees)(maptableify)(mapvprintln));; *out*;; First Name | Last Name | Employee ID;; Ryan | Neufeld | 2;; Luke | Vanderhart | 1
-
The
0flag indicates to pad a digit (d) with zeros (three, in this case).-
The
-flag indicates to left justify the string (s), giving it a total minimum width of 20 characters.
Discussion
When it comes to inserting values into a string, you have two very
different options. You can use str, which is great for a quick
fix but lacks control over how values are presented. Or you can
use format, which exposes fine-grained control over how values are
displayed but requires knowledge of C and Java-style formatting
strings. Ultimately, you should use only as much tooling/complexity
as is necessary for the task at hand: stick to str when the default
formatting for a value will suffice, and use format when you need
more control over how values display.
1.7. Searching a String by Pattern
Solution
To check for the presence of a pattern inside a string, invoke
re-find with a desired pattern and the string to test. Express the
desired pattern using a regular expression literal (like "foo" or
"\d+"):
;; Any contiguous groups of numbers(re-find#"\d+""I've just finished reading Fahrenheit 451");; -> "451"(re-find#"Bees""Beads aren't cheap.");; -> nil
Discussion
re-find is quite handy for quickly testing a string for the presence
of a pattern. It takes a regular expression pattern and a string, then
returns either the first match of that pattern or nil.
If your criterion is more stringent and you require that the entire
string match a pattern, use re-matches. Unlike re-find,
which matches any portion of a string, re-matches matches if and
only if the entire string matches the pattern:
;; In find, #"\w+" is any contiguous word characters(re-find#"\w+""my-param");; -> "my";; But in matches, #"\w+" means "all word characters"(re-matches#"\w+""my-param");; -> nil(re-matches#"\w+""justLetters");; -> "justLetters"
See Also
-
The
API
documentation for
java.lang.Pattern, which defines the exact regex syntax supported by Java (and Clojure’s regular expression literals) - Recipe 1.8, “Pulling Values Out of a String Using Regular Expressions”, for information on extracting values from a string using regular expressions
- Recipe 1.9, “Performing Find and Replace on Strings”
1.8. Pulling Values Out of a String Using Regular Expressions
Solution
Use re-seq with a regular expression pattern and a string to retrieve
a sequence of successive matches:
;; Extract simple words from a sentence(re-seq#"\w+""My Favorite Things");; -> ("My" "Favorite" "Things");; Extract simple 7-digit phone numbers(re-seq#"\d{3}-\d{4}""My phone number is 555-1234.");; -> ("555-1234")
Regular expressions with matching groups (parentheses) will return a vector for each total match:
;; Extract all of the Twitter usernames and hashtags in a tweet(defnmentions[tweet](re-seq#"(@|#)(\w+)"tweet))(mentions"So long, @earth, and thanks for all the #fish. #goodbyes");; -> (["@earth" "@" "earth"] ["#fish" "#" "fish"] ["#goodbyes" "#" "goodbyes"])
Discussion
Provided a simple pattern (one without matching groups), re-seq
will return a flat sequence of matches. Fully expressing the power of Clojure, this is a
lazy sequence. Calling re-seq on a gigantic string will not scan the
entire string right away; you’re free to consume those values
incrementally, or defer evaluation to some other constituent part of your
application further down the road.
When given a regular expression containing matching groups, re-seq will do
something a little different. Don’t worry, the resulting sequence is
still lazy—but instead of flat strings, its values will be vectors.
The first value of the vector will always be the whole match, grouped
or not; subsequent values will be the strings captured by matching
group parentheses. These captured values will appear in the order in which their
opening parentheses appeared, despite any nesting. Take a look at this
example:
;; Using re to capture and decompose a phone number and its title(defre-phone-number#"(\w+): \((\d{3})\) (\d{3}-\d{4})")(re-seqre-phone-number"Home: (919) 555-1234, Work: (191) 555-1234");; -> (["Home: (919) 555-1234" "Home" "919" "555-1234"];; ["Work: (191) 555-1234" "Work" "191" "555-1234"])
If all you’re looking for is a single match from a string, then use
re-find. It behaves almost identically to re-seq, but returns only
the first match as a singular value, instead of a sequence of match values.
Apart from re-seq, there is another way to iterate over the matches
in a string. You could do this by repeatedly calling re-find on a
re-matcher, but we don’t suggest this approach. Why? Because it
isn’t very idiomatic Clojure. Mutating a re-matcher object with
repeated calls to re-find is just wrong; it completely violates the
principle of pure functions. We highly suggest you prefer re-seq
over re-matcher and re-find unless you have a really good reason
not to.
See Also
- Recipe 1.7, “Searching a String by Pattern”, for testing a string for the presence of a pattern
- Recipe 1.9, “Performing Find and Replace on Strings”, for information on using regular expressions to find and replace portions of a string
-
The
API
documentation for
java.lang.Pattern, which defines the exact regex syntax supported by Java (and Clojure’s regular expression literals)
1.9. Performing Find and Replace on Strings
Solution
The versatile clojure.string/replace is the function you should
reach for when you need to selectively replace portions of a string.
For simple patterns, use replace with a normal string as its matcher:
(defabout-me"My favorite color is green!")(clojure.string/replaceabout-me"green""red");; -> "My favorite color is red!"(defnde-canadianize[s](clojure.string/replaces"ou""o"))(de-canadianize(str"Those Canadian neighbours have coloured behaviour"" when it comes to word endings"));; -> "Those Canadian neighbors have colored behavior when it comes to word;; endings"
Plain string replacement will only get you so far. When you need to
replace a pattern with some variability to it, you’ll need to reach for
the big guns: regular expressions. Use Clojure’s regular expression
literals (#"...") to specify a pattern as a regular expression:
(defnlinkify-comment"Add Markdown-style links for any GitHub issue numbers present in comment"[repocomment](clojure.string/replacecomment#"#(\d+)"(str"[#$1](https://github.com/"repo"/issues/$1)")))(linkify-comment"next/big-thing""As soon as we fix #42 and #1337 weshould be set to release!");; -> "As soon as we fix;; [#42](https://github.com/next/big-thing/issues/42) and;; [#1337](https://github.com/next/big-thing/issues/1337) we;; should be set to release!"
Discussion
As far as string functions go, replace is one of the more powerful and most complex ones. The majority of this complexity arises from the varying match and replacement types it can operate with.
When passed a string match, replace expects a string replacement. Any occurrences of match in the supplied string will be replaced directly with replacement.
When passed a character match (such as \c or \n), replace expects a character replacement. Like string/string, the character/character mode of replace replaces items directly.
When passed a regular expression for a match, replace gets much more interesting. One possible replacement for a regex match is a string, like in the linkify-comment example; this string interprets special character combinations like $1 or $2 as variables to be replaced by matching groups in the match. In the linkify-comment example, any contiguous digits (\d+) following a number sign (#) are captured in parentheses and are available as $1 in the replacement.
When passing a regex match, you can also provide a function for replacement instead of a string. In Clojure, the world is your oyster when you can pass a function as an argument. You can capture your replacement in a reusable (and testable) function, pass in different functions depending on the circumstances, or even pass a map that dictates replacements:
;; linkify-comment rewritten with linkification as a separate function(defnlinkify[repo[full-matchid]](str"["full-match"](https://github.com/"repo"/issues/"id")"))(defnlinkify-comment[repocomment](clojure.string/replacecomment#"#(\d+)"(partiallinkifyrepo)))
If you’ve not used regular expressions before, then you’re in for a treat. Regexes are a powerful tool for modifying strings with unbounded flexibility. As with any powerful new tool, it’s easy to overdo it. Because of their terse and compact syntax, it’s very easy to produce regexes that are both difficult to interpret and at a high risk of being incorrect. You should use regular expressions sparingly and only if you fully understand their syntax.
Jeffrey Friedl’s Mastering Regular Expressions, 3rd ed. (O’Reilly) is a fantastic book for learning and mastering regular expression syntax.
See Also
- Recipe 1.7, “Searching a String by Pattern”
-
clojure.string/replace-first, a function that operates nearly identically toclojure.string/replacebut only replaces the first occurrence ofmatch -
The
API
documentation for
java.lang.Pattern, which defines the exact regex syntax supported by Java (and Clojure’s regular-expression literals)
1.10. Splitting a String into Parts
Solution
Use clojure.string/split to tokenize a string into a vector of tokens. split takes two arguments, a string to tokenize and a regular expression to split on:
(clojure.string/split"HEADER1,HEADER2,HEADER3"#",");; -> ["HEADER1" "HEADER2" "HEADER3"](clojure.string/split"Spaces Newlines\n\n"#"\s+");; -> ["Spaces" "Newlines"]
Discussion
In addition to just naively splitting on a regular expression, split
allows you to control how many (or how few) times to split the
provided string. You can control this with the optional limit
argument. The most obvious effect of limit is to limit the number of
values returned in the resulting collection. That said, limit
doesn’t always work like you would expect, and even the absence of
this argument carries a meaning.
Without limit, the split function will return every possible
delimitation but exclude any trailing empty matches:
;; Splitting on whitespace without an explicit limit performs an implicit trim(clojure.string/split"field1 field2 field3 "#"\s+");; -> ["field1" "field2" "field3"]
If you want absolutely every match, including trailing empty ones, then you can specify -1 as the limit:
;; In CSV parsing an empty match at the end of a line is still a meaningful one(clojure.string/split"ryan,neufeld,"#","-1);; -> ["ryan" "neufeld" ""]
Specifying some other positive number as a limit will cause split to return at maximum limit substrings:
(defdata-delimiters#"[ :-]");; No-limit split on any delimiter(clojure.string/split"2013-04-05 14:39"data-delimiters);; -> ["2013" "04" "05" "14" "39"];; Limit of 1 - functionally: return this string in a collection(clojure.string/split"2013-04-05 14:39"data-delimiters1);; -> ["2013-04-05 14:39"];; Limit of 2(clojure.string/split"2013-04-05 14:39"data-delimiters2);; -> ["2013" "04-05 14:39"];; Limit of 100(clojure.string/split"2013-04-05 14:39"data-delimiters100);; -> ["2013" "04" "05" "14" "39"]
See Also
1.11. Pluralizing Strings Based on a Quantity
Solution
When you need to perform Ruby on Rails–style pluralization, use Roman Scherer’s
inflections library.
To follow along with this recipe, start a REPL using lein-try:[3]
$ lein try inflectionsUse inflections.core/pluralize with a count to attempt to pluralize
that word if the count is not one:
(require'[inflections.core:asinf])(inf/pluralize1"monkey");; -> "1 monkey"(inf/pluralize12"monkey");; -> "12 monkeys"
If you have a special or nonstandard pluralization, you can provide
your own pluralization as an optional third argument to pluralize:
(inf/pluralize1"box""boxen");; -> "1 box"(inf/pluralize3"box""boxen");; -> "3 boxen"
Discussion
When it comes to user-facing text, inflection is key. Humanizing the
output of your programs or websites goes a long way to building a
trustworthy and professional image. Ruby on
Rails set the gold standard for friendly and humanized text with its
ActiveSupport::Inflections class. Inflections#pluralize is one
such inflection, but Inflections is chock-full of cutesy-sounding
methods ending in “ize” that change the inflection of strings.
inflections provides nearly all of these capabilities in a Clojure context.
Two interesting functions in the inflections library are plural and
singular. These functions work a bit like the upper-case and
lower-case of pluralization; plural transforms words into their
plural form, and singular coerces words to their singular form. These
transformations are based on a number of rules in
inflections.plural.
You can add your own rules for pluralization with inflections.core/plural!:
(inf/plural"box");; -> "boxes";; Words ending in 'ox' pluralize with 'en' (and not 'es')(inf/plural!#"(ox)(?i)$""$1en")(inf/plural"box");; -> "boxen";; plural is also the basis for pluralize...(inf/pluralize2"box");; -> "2 boxen"
The library also has support for inflections like camelize,
parameterize, and ordinalize:
;; Convert "snake_case" to "CamelCase"(inf/camelize"my_object");; -> "MyObject";; Clean strings for usage as URL parameters(inf/parameterize"My most favorite URL!");; -> "my-most-favorite-url";; Turn numbers into ordinal numbers(inf/ordinalize42);; -> "42nd"
See Also
-
The
inflections-cljGitHub repository for the most up-to-date listing of inflections available
1.12. Converting Between Strings, Symbols, and Keywords
Problem
You have a string, a symbol, or a keyword and you’d like to convert it into a different one of these string-like data types.
Solution
To convert from a string to a symbol, use the symbol function:
(symbol"valid?");; -> valid?
To convert from a symbol to a string, use str:
(str'valid?);; -> "valid?"
When you have a keyword and want a string, you can use name, or str if you
want the leading colon:
(name:triumph);; -> "triumph";; Or, to include the leading colon:(str:triumph);; -> ":triumph"
To convert from a symbol or string to a keyword, use keyword:
(keyword"fantastic");; -> :fantastic(keyword'fantastic);; -> :fantastic
You’ll need an intermediate step, through name, to go from keyword to symbol:
(symbol(name:wonderful));; -> wonderful
Discussion
The primary conversion functions here are str, keyword, and symbol—each
named for the data type it returns. One of these, symbol, is a bit more
strict in terms of the input it allows: it must take a string, which is why you
need the extra step in the keyword-to-symbol conversion.
There is another class of differences among these types: namely, that keywords
and symbols may be namespaced, signified by a slash (/) in the middle. For these
kinds of keywords and symbols, the name function may or may not be
sufficient to convert to a string, depending on your use case:
;; If you only want the name part of a keyword(name:user/valid?);; -> "valid?";; If you only want the namespace(namespace:user/valid?);; -> "user"
Very often, you actually want both parts. You could collect them separately
and concatenate the strings with a / in the middle, but there’s an easier
way. Java has a rich set of performant methods for dealing with immutable
strings. You can take the leading-colon string and lop off the first
character with java.lang.String.substring(int):
(str:user/valid?);; -> ":user/valid?"(.substring(str:user/valid?)1);; -> "user/valid?"
See the java.lang.String API documentation for more string methods.
You can convert namespaced symbols to keywords just as easily as their non-namespaced counterparts, but again, converting in the other direction (keyword to symbol) takes an extra step:
(keyword'produce/onions);; -> :produce/onions(symbol(.substring(str:produce/onions)1));; -> produce/onions
And finally, both the keyword and symbol functions have two-argument versions
that allow you to pass in the namespace and name separately. Sometimes this is
nicer—for example, when you already have one or both of the values bound in a
def, let, or other binding:
(defshopping-area"bakery")(keywordshopping-area"bagels");; -> :bakery/bagels(symbolshopping-area"cakes");; -> bakery/cakes
These three string-like data types are all great for different situations, and
how to choose among them is another topic. But it’s quite common to need to
convert among them, so keyword, symbol, str, namespace, and name are
handy to have in your tool belt.
1.13. Maintaining Accuracy with Extremely Large/Small Numbers
Problem
You need to work precisely with numbers, especially those that are
very large or very small, without the imprecision implied by using
floating-point representations such as double values.
Solution
First, know that Clojure supports exponents as literal numbers, allowing you to succinctly express large/small numbers:
;; Avogadro's number6.0221413e23;; -> 6.0221413E23;; 1 Angstrom in meters1e-10;; -> 1.0E-10
Integer values passing the upper bound of a size-bounded type (like long) will raise an integer overflow error.
Use the “quote” versions of numeric operations like - or * to allow promotion to Big types:
(*99999999999999999999);; ArithmeticException integer overflow clojure.lang.Numbers.throwIntOverflow(*'99999999999999999999);; -> 99950009999000049999N
Discussion
Clojure has a number of numeric types: integer and long, double, and
BigInteger and BigDecimal. The bounded types (int, long, and
double) all seamlessly transition as needed while inside the total
bounds of those types. Exceeding those bounds causes one of two things
to happen. For integers, an integer overflow error is raised. For
floating-point numbers, the result will become Infinity. With
integers, you can avoid this error by using quote versions of +,
-, *, and /. These operations support arbitrary precision and
will promote integers to BigInteger if necessary.
Floating-point values are a little more tricky. The quote versions
of numeric operations won’t help here; you’ll need to infect your
operations with the BigDecimal type. In Clojure, the BigInteger
and BigDecimal types are what you would call “contagious.” Once a
“big” number is introduced to an operation, it infects all of the
follow-on results. You could do something like multiplying a number
by a BigDecimal 1, but it’s much easier to use the bigdec or
bigint functions to promote a value manually:
(*2Double/MAX_VALUE);; -> Double/POSITIVE_INFINITY(*2(bigdecDouble/MAX_VALUE));; -> 3.5953862697246314E+308M
Contagion doesn’t only occur with Big types; it also pops up in the
integer-to–floating-point boundary. Floating-point numbers are
contagious to integers. Arithmetic involving any floating-point
values will always return a floating-point value.
See Also
- Recipe 1.14, “Working with Rational Numbers”, for information on maintaining accuracy when using rational numbers
1.14. Working with Rational Numbers
Solution
When manipulating integers (or other rationals), you can expect to maintain precision, including recurring fractions like 1/3 (0.333…):
(/13);; -> 1/3(type(/13));; -> clojure.lang.Ratio(*3(/13));; -> 1N
Use rationalize on doubles to coerce them to rationals to avoid losing precision:
(+(/13)0.3);; -> 0.6333333333333333(rationalize0.3);; -> 3/10(+(/13)(rationalize0.3));; -> 19/30
Discussion
Clojure does its best to help you retain accuracy when working with
numbers, especially integers. When dividing integers, Clojure maintains
accuracy by expressing the quotient as an accurate ratio
of integers instead of a lossy double. This accuracy isn’t without a
cost, though; operations on rational numbers are much slower than
operations on simpler types. As is discussed in
Recipe 1.13, “Maintaining Accuracy with Extremely Large/Small Numbers”, accuracy is always a
trade-off for performance, and is something you need to consider given
the problem at hand.
When operating on both doubles and rationals at the same time, care is
advised; on account of the way type contagion works in Clojure,
performing an operation over both types will cause the rational number
to be coerced to a double. This transition isn’t necessarily inaccurate
for a single operation, but the change in type introduces the
possibility for inaccuracy to creep in.
To maintain accuracy when working with doubles, use the rationalize
function. This function returns the rational value of any number. Calling rationalize on any values that might possibly be doubles will allow you to maintain absolute accuracy (at the cost of performance).
1.15. Parsing Numbers
Solution
For “normal”-sized large or precise numbers, use Integer/parseInt or
Double/parseDouble to parse them:
(Integer/parseInt"-42");; -> -42(Double/parseDouble"3.14");; -> 3.14
Discussion
What is a “normal”-sized number? For Integer/parseInt, normal is anything below
Integer/MAX_VALUE (2147483647); and for Double/parseDouble, it’s anything below
Double/MAX_VALUE (around 1.79 × 10^308).functions
When the numbers you are parsing are either abnormally large or
abnormally precise, you’ll need to parse them with BigInteger
or BigDecimal to avoid losing precision. The versatile bigint and
bigdec functions can coerce strings (or any other numerical types, for
that matter) into infinite-precision containers:
(bigdec"3.141592653589793238462643383279502884197");; -> 3.141592653589793238462643383279502884197M(bigint"122333444455555666666777777788888888999999999");; -> 122333444455555666666777777788888888999999999N
See Also
-
The API documentation for
Integer/parseIntandDouble/parseDouble
1.16. Truncating and Rounding Numbers
Solution
If the integer portion of a number is all you are concerned with, use
int to coerce the number to an integer. Of course, this completely
discards any decimal places without performing any rounding:
(int2.0001);; -> 2(int2.999999999);; -> 2
If you still value some level of precision, then rounding is probably
what you’re after. You can use Math/round to perform simple
rounding:
(Math/round2.0001);; -> 2(Math/round2.999);; -> 3;; This is equivalent to:(int(+2.990.5));; -> 3
If you want to perform an unbalanced rounding, such as unconditionally
“rounding up” or “rounding down,” then you should use Math/ceil or
Math/floor, respectively:
(Math/ceil2.0001);; -> 3.0(Math/floor2.999);; -> 2.0
You’ll notice these functions return decimal numbers. Wrap calls to
ceil or floor in int to return an integer.
Discussion
One of the simplest ways to “round” numbers is truncation. int will
do this for you, coercing floating-point numbers to integers by simply
chopping off any trailing decimal places. This isn’t necessarily
mathematically correct, but it is certainly convenient if it is
accurate enough for the problem at hand.
Math/round is the next step up in rounding technology. As with many
other primitive manipulation functions in Clojure, the language prefers
not to reinvent the wheel. Math/round is a Java function that
rounds by adding 1/2 to a number before dropping decimal places
similarly to int.
For more advanced rounding, such as controlling the number of decimal
places or complex rounding modes, you may need to resort to using the
with-precision function. You likely already know BigDecimal
numbers are backed by Java classes, but you might not have known that
Java exposes a number of knobs for tweaking BigDecimal calculations;
with-precision exposes these knobs.
with-precision is a macro that accepts a BigDecimal precision
mode and any number of expressions, executing those expressions in a
BigDecimal context tuned to that precision. So what does precision
look like? Well, it’s a little strange. The most basic precision is
simply a positive integer “scale” value. This value specifies the
number of decimal places to work with. More complex precisions involve a
:rounding value, specified as a key/value pair like :rounding FLOOR (this is a macro
of course, so why not?). When not specified, the default rounding mode
is HALF_UP, but any of the values CEILING, FLOOR, HALF_UP,
HALF_DOWN, HALF_EVEN, UP, DOWN, or UNNECESSARY are allowed (see the
RoundingMode documentation
for more detailed descriptions of each mode):
(with-precision3(/7M9));; -> 0.778M(with-precision1(/7M9));; -> 0.8M(with-precision1:roundingFLOOR(/7M9));; -> 0.7M
One notable “gotcha” with with-precision is that it only changes the
behavior of BigDecimal arithmetic, leaving regular arithmetic
unchanged. You’ll have to introduce BigDecimal values into
your expressions with literal values (3M), or by means of the
bigdec function:
(with-precision3(/13));; -> 1/3(with-precision3(/(bigdec1)3));; -> 0.333M
See Also
-
Recipe 1.13, “Maintaining Accuracy with Extremely Large/Small Numbers”, for more information
on
BigDecimal, specifically type contagion - Recipe 1.17, “Performing Fuzzy Comparison”
1.17. Performing Fuzzy Comparison
Problem
You need to test for equality with some tolerance for minute differences. This is especially a problem when comparing floating-point numbers, which are susceptible to “drift” through repeated operations.
Solution
Clojure has no built-in functions for fault-tolerant equality, or “fuzzy
comparison,” as it is often called. It’s trivial to implement your own
fuzzy= function:
(defnfuzzy=[tolerancexy](let[diff(Math/abs(-xy))](<difftolerance)))(fuzzy=0.011010.000000000001);; -> true(fuzzy=0.011010.1);; -> false
Discussion
fuzzy= works like most other fuzzy comparison algorithms do: first
it finds the absolute difference between the two operands; and second,
it tests whether that difference falls beneath the given tolerance.
Of course, there’s nothing dictating that the tolerance needs to be
some minute fractional number. If you were comparing large numbers and
wanted to ignore variations under a thousand, you could set the
tolerance to 1000.
Even with fuzzy=, you still need to take care when comparing
floating-point values, especially for values differing by numbers
very close to your tolerance. At differences bordering the supplied
tolerance, you may find the results a bit strange:
(-0.220.23);; -> -0.010000000000000009(-0.230.24);; -> -0.009999999999999981
As odd as this is, this isn’t unexpected. The IEEE 754 specification
for floating-point values is a purposefully limited format, a trade-off
between accuracy and performance. If absolute precision is what you’re
after, then you should be using BigDecimal or BigInt. See
Recipe 1.13, “Maintaining Accuracy with Extremely Large/Small Numbers”, for more information on those
two types.
The fuzzy= function, as written, has a number of interesting side
effects. First and foremost, having tolerance as the first
argument makes it use partial to produce partially applied equals
functions tuned to a specific tolerance:
(defequal-within-ten?(partialfuzzy=10))(equal-within-ten?100109);; -> true(equal-within-ten?100110);; -> false
What if you wanted to sort using fuzzy comparison? The sort function
takes as an optional argument a predicate or comparator. Let’s write a
function fuzzy-comparator that returns a comparator with a given tolerance:
(defnfuzzy-comparator[tolerance](fn[xy](if(fuzzy=tolerancexy);0(comparexy))));(sort(fuzzy-comparator10)[10011150109]);; -> (11 10 9 100 150) ; 100 and 150 have moved, but not 11, 10, and 9
-
If the two values being compared are within
toleranceof each other, return0to indicate they are equal.-
Otherwise, fall back to normal
compare.
See Also
1.18. Performing Trigonometry
Solution
All of the trigonometric functions are accessible via
java.lang.Math,
which is available as Math. Use them like you would any other
namespaced function:
;; Calculating sin(a + b). The formula for this is;; sin(a + b) = sin a * cos b + sin b cos a(defnsin-plus[ab](+(*(Math/sina)(Math/cosb))(*(Math/sinb)(Math/cosa))))(sin-plus0.10.3);; -> 0.38941834230865047
Trigonometric functions operate on values measured in radians. If you
have values measured in degrees, such as latitude or longitude, then
you’ll need to convert them to radians first. Use Math/toRadians to
convert degrees to radians:
;; Calculating the distance in kilometers between two points on Earth(defearth-radius6371.009)(defndegrees->radians[point](mapv#(Math/toRadians%)point))(defndistance-between"Calculate the distance in km between two points on Earth. Eachpoint is a pair of degrees latitude and longitude, in that order."([p1p2](distance-betweenp1p2earth-radius))([p1p2radius](let[[lat1long1](degrees->radiansp1)[lat2long2](degrees->radiansp2)](*radius(Math/acos(+(*(Math/sinlat1)(Math/sinlat2))(*(Math/coslat1)(Math/coslat2)(Math/cos(-long1long2)))))))))(distance-between[49.2000-98.1000][35.9939,-78.8989]);; -> 2139.42827188432
Discussion
It may be surprising to some that Clojure doesn’t have its own internal
math namespace, but why reinvent the wheel? Despite its tainted
reputation, Java can perform, especially when it comes to math.
Clojure’s Java interop forms and typing sugar make doing math using
java.lang.Math almost pleasant.
java.lang.Math isn’t only for trigonometry. It also contains a
number of functions useful for dealing with exponentiation, logarithms,
and roots. A full list of methods is available in the
java.lang.Math
javadoc.
See Also
- Recipe 8.5, “Alleviating Performance Problems with Type Hinting”, for tips on improving performance
1.19. Inputting and Outputting Integers with Different Bases
Problem
You need to enter numbers into a Clojure REPL or code in a different base (such as hexadecimal or binary).
Solution
Specify the base or radix of a literal number by prefixing it with
the radix number (e.g., 2, 16, etc.) and the letter r. Any base from
2 to 36 is valid (there are, of course, 10 digits and 26 letters available):
2r101010;; -> 423r1120;; -> 4216r2A;; -> 4236rABUNCH;; -> 624567473
To output integers, use the Java method Integer/toString:
(Integer/toString132);; -> "1101"(Integer/toString4216);; -> "2a"(Integer/toString3536);; -> "z"
Discussion
Unlike the
ordering of most Clojure functions, this method takes an integer
first and the optional base second, making it hard to partially
apply without wrapping it in another function. You can write a small
wrapper around Integer/toString to accomplish this:
(defnto-base[radixn](Integer/toStringnradix))(defbase-two(partialto-base2))(base-two9001);; -> "10001100101001"
See Also
-
Recipe 1.6, “Formatting Strings”, for information on
format(theoandxspecifiers print integers in octal and hexadecimal, respectively) - Recipe 1.15, “Parsing Numbers”
1.20. Calculating Statistics on Collections of Numbers
Problem
You need to calculate simple statistics like mean, median, mode, and standard deviation on a collection of numbers.
Solution
Find the mean (average) of a collection by dividing its total by the count of the collection:
(defnmean[coll](let[sum(apply +coll)count(countcoll)](if(pos?count)(/sumcount)0)))(mean[1234]);; -> 5/2(mean[11.67.410]);; -> 5.0(mean[]);; -> 0
Find the median (middle value) of a collection by sorting its values and getting its middle value. There are, of course, special considerations for collections of even length. In these cases, the median is considering the mean of the two middle values:
(defnmedian[coll](let[sorted(sortcoll)cnt(countsorted)halfway(int(/cnt2))](if(odd?cnt)(nthsortedhalfway);(let[bottom(dechalfway)bottom-val(nthsortedbottom)top-val(nthsortedhalfway)](mean[bottom-valtop-val])))));(median[52413]);; -> 3(median[7023]);; -> 5/2 ; The average of 2 and 3.
-
In the case that
collhas an odd number of items, simply retrieve that item withnth.-
When
collhas an even number of items, find the index for the other central value (bottom), and take the mean of the top and bottom values.
Find the mode (most frequently occurring value) of a collection by
using frequencies to tally occurrences. Then massage that tally to
retrieve the discrete list of modes:
(defnmode[coll](let[freqs(frequenciescoll)occurrences(group-bysecondfreqs)modes(last(sortoccurrences))modes(->>modessecond(mapfirst))]modes))(mode[:alan:bob:alan:greg]);; -> (:alan)(mode[:smith:carpenter:doe:smith:doe]);; -> (:smith :doe)
Standard deviation
Find the sample standard deviation by completing the following steps:
-
For each value in the collection, subtract the
meanfrom the value and multiply that result by itself. - Then, sum up all those values.
- Divide the result by the number of values minus one.
Finally, take the square root of the previous result:
(defnstandard-deviation[coll](let[avg(meancoll)squares(for[xcoll](let[x-avg(-xavg)](*x-avgx-avg)))total(countcoll)](->(/(apply +squares)(-total1))(Math/sqrt))))(standard-deviation[452957454]);; -> 2.0(standard-deviation[45544226]);; -> 1.4142135623730951
Discussion
Both mean and median are fairly easy to reproduce in Clojure, but
mode requires a bit more effort. mode is a little different than
mean or median in that it generally only makes sense for
nonnumeric data. Calculating the modes of a collection is a little
more involved and ultimately requires a good deal of processing
compared to its numeric cousins.
Here is a breakdown of how mode works:
(defnmode[coll](let[freqs(frequenciescoll);occurrences(group-bysecondfreqs);modes(last(sortoccurrences));
modes(->>modes;
second(mapfirst))]modes))
-
frequenciesreturns a map that tallies the number of times each value incolloccurs. This would be something like{:a 1 :b 2}.-
group-bywithsecondinverts thefreqsmap, turning keys into values and merging duplicates into groups. This would turn{:a 1 :b 1}into{1 [[:a 1] [:b 1]]}.-
The list of occurrences is now sortable. The last pair in the sorted list will be the modes, or most frequently occurring values.
-
The final step is processing the raw mode pairs into discrete values. Taking
secondturns[2 [[:alan 2]]]into[[:alan 2]], and(map first)turns that into(:alan).
The standard deviation measures how much, on average, the individual values in a
population deviate from the mean: the higher the standard deviation is, the
farther away the individual values will be (on average).
standard-deviation is a bit more mathematical than mean, median, and
mode. Follow along the execution of this function step by step:
(defnstandard-deviation[coll](let[avg(meancoll);squares(for[xcoll];(let[x-avg(-xavg)](*x-avgx-avg)))total(countcoll)](->(/(apply +squares);(-total1))(Math/sqrt))))
-
Calculate the mean of the collection.
-
For each value, calculate the square of the difference between the value and the mean.
-
Finally, calculate the sample standard deviation by taking the square root of the sum of squares over population size minus one.
Note
If you have the complete population, you can compute the population
standard deviation by dividing by total instead of (- total 1).
See Also
- The Wikipedia article on standard deviation for more information on standard deviation and what it can be used for
1.21. Performing Bitwise Operations
Solution
Bitwise operations aren’t quite as commonly used in high-level
languages (like Clojure) as they are in systems languages like C or
C++, but the techniques learned in those systems languages can still
be useful. Clojure exposes a number of bitwise operations in its core
namespace, all prefixed with bit-. One place bitwise operations really shine is in compressing a large
number of binary flags into a single value:
;; Modeling a subset of Unix filesystem flags in a single integer(deffs-flags[:owner-read:owner-write:group-read:group-write:global-read:global-write]);; Fold flags into a map of flag->bit(defbitmap(zipmapfs-flags(map(partial bit-shift-left1)(range))));; -> {:owner-read 1, :owner-write 2, :group-read 4, ...}(defnpermissions-int[&flags](reduce bit-or0(mapbitmapflags)))(defowner-only(permissions-int:owner-read:owner-write))(Integer/toBinaryStringowner-only);; -> "11"(defread-only(permissions-int:owner-read:group-read:global-read))(Integer/toBinaryStringread-only);; -> "10101"(defnable-to?[permissionsflag](not=0(bit-andpermissions(bitmapflag))))(able-to?read-only:global-read);; -> true(able-to?read-only:global-write);; -> false
Discussion
Clojure provides a full complement of bitwise operations in its core
library. This includes the logic operations and and or, their negations, and shifts, to name a few.
When working with bitwise operations, it can often be necessary to view
the binary representation of an integer. Java’s
Integer/toBinaryString can conveniently print out a binary
representation of a number.
Interestingly enough, core also includes a bit-set and a bit-test.
These two operations set or test an individual bit position in an
integer. Instead of working in multiples of two, as is necessary for
operations like bit-and, you can operate by the index of the flag
you’re interested in. This drastically simplifies the preceding example:
;; Modeling a subset of Unix filesystem flags in a single integer(deffs-flags[:owner-read:owner-write:group-read:group-write:global-read:global-write])(defbitmap(zipmapfs-flags(map#(.indexOffs-flags%)fs-flags)))(defno-permissions0)(defowner-read(bit-setno-permissions(:owner-readbitmap)))(Integer/toBinaryStringowner-read);; -> "1";; Granting global permissions...(defanything(reduce#(bit-set%1(bitmap%2))no-permissionsfs-flags))(Integer/toBinaryStringanything);; -> "111111"
1.22. Generating Random Numbers
Solution
Clojure makes available a number of pseudorandom number generating functions for your disposal.
For generating random floating-point numbers from 0.0 up to (but not including) 1.0, use rand:
(rand);; -> 0.0249306187447903(rand);; -> 0.9242089829055088
For generating random integers, use rand-int:
;; Emulating a six-sided die(defnroll-d6[](inc(rand-int6)))(roll-d6);; -> 1(roll-d6);; -> 3
Discussion
In addition to generating a number from 0.0 to 1.0, rand also
accepts an optional argument that specifies the exclusive maximum
value. For example, (rand 5) would return a floating-point number
ranging from 0.0 (inclusive) to 5.0 (exclusive).
(rand-int 5), on the other hand, would return a random integer between 0
(inclusive) and 5 (exclusive). At first blush, rand-int might seem like an
ideal way to select a random element from a vector or list. This is a lot of
ceremony, though. Use rand-nth instead to get a random element from any
sequential collection (i.e., the collection responds to nth):
(rand-nth[123]);; -> 1(rand-nth'(:a:b:c));; -> :c
This won’t work for sets or hash maps, however. If you want to retrieve
a random element from a nonsequential collection like a set, use
seq to transform that collection into a sequence before calling
rand-nth on it:
(rand-nth(seq#{:heads:tails}));; -> :heads
If you’re trying to randomly sort a collection, use shuffle to
receive a random permutation of your collection:
(shuffle[123456]);; -> [3 1 4 5 2 6]
See Also
-
The
API
documentation for
java.util.Random - Recipe 10.3, “Thoroughly Testing by Randomizing Inputs”
1.23. Working with Currency
Solution
Use the Money library for representing, manipulating, and storing values in monetary units.
To follow along with this recipe, add [clojurewerkz/money "1.4.0"]
to your project’s dependencies, or start a REPL using lein-try:
$ lein try clojurewerkz/moneyThe clojurewerkz.money.amounts namespace contains functions for
creating, modifying, and comparing units of currency:
(require'[clojurewerkz.money.amounts:asma])(require'[clojurewerkz.money.currencies:asmc]);; $2.00 in USD(deftwo(ma/amount-ofmc/USD2))two;; -> #<Money USD 2.00>(ma/plustwotwo);; -> #<Money USD 4.00>(ma/minustwotwo);; -> #<Money USD 0.00>(ma/<two(ma/amount-ofmc/USD2.01));; -> true(ma/total[twotwotwotwo]);; -> #<Money USD 8.00>
Discussion
Working with currency is serious business. Never trust built-in numerical types with handling currency, especially floating-point values. These types are simply not meant to capture and manipulate currency with the semantics and precision required. In particular, floating-point values of the IEEE 754 standard carry a certain imprecision by design:
(-0.230.24);; -> -0.009999999999999981
You should always use a library custom-tailored for dealing with money. The Money library wraps the trusted and battle-tested Java library Joda-Money. Money provides a large amount of functionality beyond arithmetic, including rounding and currency conversion:
(ma/round(ma/amount-ofmc/USD3.14)0:down);; -> #<Money USD 3.00>(ma/convert-to(ma/amount-ofmc/CAD152.34)mc/USD1.01696:down);; -> #<Money USD 154.92>
The round function takes four arguments. The first three are an amount of currency, a
scale factor, and a rounding mode. The scaling factor is a somewhat
peculiar argument. It might be familiar to you if you’ve ever done
scaling with BigDecimal, which shares identical factors. A scale of
-1 scales to the tens place, 0 scales to the ones place, and so on and
so forth. Further details can be found in the javadoc for the
rounded
method of Joda-Money’s Money class. The final argument is
a rounding mode, of which there are quite a few. :ceiling and :floor round toward positive or
negative infinity. :up and :down round toward or away from zero.
Finally :half-up, :half-down, and :half-even round toward the
nearest neighbor, preferring up, down, or the most even neighbor.
clojurewerkz.money.amounts/convert-to is a much less complicated
function. convert-to takes an amount of currency, a target currency, a
conversion factor, and a rounding mode. Money doesn’t provide its own
conversion factor, since conversion rates change so often, so you’ll need to seek out a reputable source for them. Unfortunately, we can’t
help you with this one.
Money also provides support for a number of different persistence and serialization mediums, including Cheshire for converting to/from JSON and Monger for persisting currency values to MongoDB.
1.24. Generating Unique IDs
Solution
Use Java’s java.util.UUID/randomUUID to generate a universally
unique ID (UUID):
(java.util.UUID/randomUUID);; -> #uuid "5358e6e3-7f81-40f0-84e5-750e29e6ee05"(java.util.UUID/randomUUID);; -> #uuid "a6f92a6f-f736-468f-9e26-f392852825f4"
Discussion
Oftentimes when building systems, you want to assign unique IDs to objects and records. IDs are usually simple integers that monotonically increase with time. This isn’t without its problems, though.
You can’t mingle IDs of objects from different origins; and worse, they reveal information about the amount and input volume of your data.
This is where UUIDs come in. UUIDs, or universally unique identifiers, are 128-bit random numbers almost certainly unique across the entire universe. A bold claim, of course—see RFC 4122 for more detailed information on UUIDs, how they’re generated, and the math behind them.
You may have noticed Clojure prints UUIDs with a #uuid in front of
them. This is a reader literal tag. It acts as a shortcut for the
Clojure reader to read and initialize UUID objects. Reader literals
are a lot like string or number literals like "Hi" or 42, but they
can capture more complex data types.
This makes it possible for formats like edn (extensible data notation) to communicate in a common lingo about things like UUIDs without resorting to string interning and accompanying custom parsing logic.
See Also
- Recipe 1.21, “Performing Bitwise Operations”
-
Recipe 1.26, “Representing Dates as Literals”, for information on
#inst, another example of a reader literal, for dates -
The
java.util.UUIDAPI documentation
1.25. Obtaining the Current Date and Time
Solution
Use Java’s java.util.Date constructor to create a Date instance
representing the present time and date:
(defnnow[](java.util.Date.))(now);; -> #inst "2013-04-06T14:33:45.740-00:00";; A few seconds later...(now);; -> #inst "2013-04-06T14:33:51.234-00:00"
If you’re more interested in the current Unix timestamp, use
System/currentTimeMillis:
(System/currentTimeMillis);; -> 1365260110635(System/currentTimeMillis);; -> 1365260157013
Discussion
It doesn’t make much sense for Clojure to reimplement or wrap the
JVM’s backing time and date functionality. As such, the norm is to use
Clojure’s Java interop forms to instantiate a Date object
representing “now.”
#inst "2013-04-06T14:33:51.234-00:00" doesn’t look very much like
Java, does it? That’s because Clojure’s “instant” reader literal
uses java.util.Date as its backing implementation. You can learn
more about the #inst reader literal in Recipe 1.26, “Representing Dates as Literals”.
Using System/currentTimeMillis can be useful for performing a
one-off benchmark, but given the high-quality tools out there that do
this already, currentTimeMillis is of limited utility; you may want
to try Hugo Duncan’s
Criterium library if
benchmarking is what you’re after. Additionally, you shouldn’t try to
use currentTimeMillis as some sort of unique value—UUIDs do
a much better job of this.
If you decide you would rather use
clj-time to work with dates, it
provides the function clj-time.core/now to get the current DateTime:
(require'[clj-time.core:astimec])(timec/now);; -> #<DateTime 2013-04-06T14:35:15.453Z>
Use clj-time.local/local-now to retrieve a DateTime instance for
the present scoped to your machine’s local time zone:
(require'[clj-time.local:astimel])(timel/local-now);; -> #<DateTime 2013-04-06T09:35:20.141-05:00>
See Also
- Recipe 1.24, “Generating Unique IDs”, to learn how to generate universally unique IDs
-
Recipe 1.26, “Representing Dates as Literals”, for more information on the
#instreader literal
1.26. Representing Dates as Literals
Solution
Use Clojure’s #inst literals in source to represent fixed points in
time:
(defryans-birthday#inst"1987-02-18T18:00:00.000-00:00")(printlnryans-birthday);; *out*;; #inst "1987-02-18T18:00:00.000-00:00"
When communicating with other Clojure processes (or anything else that
speaks edn), use clojure.edn/read
to reify instant literal strings into Date objects:
;; A faux communication channel that "receives" edn strings(require'clojure.edn)(import'[java.ioPushbackReaderStringReader])(defnremote-server-receive-date[](->"#inst \"1987-02-18T18:00:00.000-00:00\""(StringReader.)(PushbackReader.)))(clojure.edn/read(remote-server-receive-date));; -> #inst "1987-02-18T18:00:00.000-00:00"
In the preceding example, remote-server-receive-date emulates a
communication channel upon which you may receive edn data.
Discussion
Since Clojure 1.4, instants in time have been represented via
the #inst reader literal. This means dates are no longer represented
by code that must be evaluated, but instead have a textual representation that is both
consistent and serializable. This standard allows any process capable
of communicating in extensible data notation to speak
clearly about instants of time. See the
edn
implementations list for a list of languages that speak edn; the list
includes Clojure, Ruby, and JavaScript so far, with many more
implementations in the works.
It’s also possible to vary how the reader evaluates #inst literals
by changing the binding of *data-readers*. By varying the binding of
*data-readers*, it is possible to read #inst literals as
java.util.Calendar or java.sql.Timestamp, if you so desire:
(definstant"#inst \"1987-02-18T18:00:00.000-00:00\"")(binding[*data-readers*{'instclojure.instant/read-instant-calendar}](class(read-stringinstant)));; -> java.util.GregorianCalendar(binding[*data-readers*{'instclojure.instant/read-instant-timestamp}](class(read-stringinstant)));; -> java.sql.Timestamp
See Also
- Recipe 1.24, “Generating Unique IDs”, for another example of a reader literal included with Clojure
1.27. Parsing Dates and Times Using clj-time
Solution
Working directly with Java’s date and time classes is like pulling
teeth. We suggest using
clj-time, a Clojure wrapper
over the excellent Joda-Time library.
Before starting, add [clj-time "0.6.0"] to your project’s
dependencies or start a REPL using lein-try:
$ lein try clj-timeUse clj-time.format/formatter to create custom date/time
representations capable of parsing candidate strings. Use the
clj-time.format/parse function with those formatters to parse
strings into DateTime objects:
(require'[clj-time.format:astf]);; To parse dates like "02/18/87"(defgovernment-forms-date(tf/formatter"MM/dd/yy"))(tf/parsegovernment-forms-date"02/18/87");; -> #<DateTime 1987-02-18T00:00:00.000Z>(defwonky-format(tf/formatter"HH:mm:ss:SS' on 'yyyy-MM-dd"));; -> #'user/wonky-format(tf/parsewonky-format"16:13:49:06 on 2013-04-06");; -> #<DateTime 2013-04-06T16:13:49.060Z>
Discussion
The formatter function is a powerful little function that
takes a date/time format string and returns an object capable of
parsing date/time strings in that format. This format string can
include any number of symbols representing portions of a time or date.
Some example symbols include year (“yy” or “yyyy”), day (“dd”), or even
a literal string like "on". The full list of these symbols is
available in the Joda-Time
DateTimeFormat
javadoc.
More often than not, the dates and times you’re parsing may be strange,
but not so strange that no one has seen them before. For this, clj-time
includes a large number of built-in formatters. Use
clj-time.format/show-formatters to print out a list of built-in
formats and a sample date/time in each format. Once you’ve picked a
suitable format, use clj-time.format/formatters with its keyword to
receive the appropriate DateTimeFormatter.
By default, formatter always parses strings into DateTime objects
with a UTC time zone. formatter optionally takes a time zone as its
second argument. You can use clj-time.core/time-zone-for-offset or
clj-time.core/time-zone-for-id to receive a DateTimeZone object to
pass to formatter.
See Also
- Recipe 1.28, “Formatting Dates Using clj-time”, for information on how to use formatters to unparse strings
- The official API documentation for Java’s simple date formatter
1.28. Formatting Dates Using clj-time
Solution
While it is possible to format Java date–like instances (Date,
Calendar, and Timestamp) with clojure.core/format, you should
use clj-time to format dates.
Before starting, add [clj-time "0.6.0"] to your project’s
dependencies or start a REPL using lein-try:
$ lein try clj-timeTo output a date/time as a string, use clj-time.format/unparse with a
DateTimeFormatter. There are a number of built-in formatters available via
clj-time.format/formatters, or you can build your own with
clj-time.format/formatter:
(require'[clj-time.format:astf])(require'[clj-time.core:ast])(tf/unparse(tf/formatters:date)(t/now));; -> "2013-04-06"(defmy-format(tf/formatter"MMM d, yyyy 'at' hh:mm"))(tf/unparsemy-format(t/now));; -> "Apr 6, 2013 at 04:54"
Discussion
It is certainly possible to format pure Java dates and times; however, in our
experience, it isn’t worth the hassle—the syntax is ugly, and the workflow is verbose. clj-time and its backing library Joda-Time have a track
record for making it easy to work with dates and times on the JVM.
The formatter function is quite the gem. Not only does it produce a
“format” capable of printing or unparseing a date, but it is also
capable of parsing strings back into dates. In other words,
DateTimeFormatter is capable of round-tripping from string to Date
and back again. Much of how formatter and formatters work is
covered in Recipe 1.27, “Parsing Dates and Times Using clj-time”.
One format symbol used less frequently in parsing is the textual
day of the week (i.e., “Tuesday” or “Tue”). Use "E" in your format
string to output the abbreviated day of the week, and "EEEE" for the
full-length day of the week:
(defabbr-day(tf/formatter"E"))(deffull-day(tf/formatter"EEEE"))(tf/unparseabbr-day(t/now));; -> "Mon"(tf/unparsefull-day(t/now));; -> "Monday"
If you need to format native Java date/time instances, you can use the
functions in the clj-time.coerce namespace to coerce any number of
Java date/time instances into Joda-Time instances:
(require'[clj-time.coerce:astc])(tc/from-date(java.util.Date.));; -> #<DateTime 2013-04-06T17:03:16.872Z>
Similarly, you can use clj-time.coerce to coerce instances from
Joda-Time instances into other formats:
(tc/to-date(t/now));; -> #inst "2013-04-06T17:03:57.239-00:00"(tc/to-long(t/now));; -> 1365267761585
See Also
-
The
clj-timeproject page on GitHub -
Recipe 1.27, “Parsing Dates and Times Using clj-time”, for more detailed
information on
formatterandformatters - The official API documentation for Java’s simple date formatter
1.29. Comparing Dates
Solution
You can compare Java Dates using the compare function:
(defnnow[](java.util.Date.))(defone-second-ago(now))(Thread/sleep1000);; Now is greater than (1) one second ago.(compare(now)one-second-ago);; -> 1;; One second ago is less than (-1) now.(compareone-second-ago(now));; -> -1;; "Equal" manifests as 0.(compareone-second-agoone-second-ago);; -> 0
Discussion
Why not just compare dates using Clojure’s built-in comparison
operators (<=, >, etc.)? The problem with these operators is that
they utilize clojure.lang.Numbers and attempt to coerce their
arguments to numerical types.
Since regular comparison won’t work, it’s necessary to use the
compare function. The compare function takes two arguments and
returns a number indicating that the first argument was either
less than (-1), equal to (0), or greater than (+1) the second argument.
Clojure’s sort functions use compare under the hood, so no extra
work is required to sort a collection of dates:
(defoccurrences[#inst"2013-04-06T17:40:57.688-00:00"#inst"2002-12-25T00:40:57.688-00:00"#inst"2025-12-25T11:23:31.123-00:00"])(sortoccurrences);; -> (#inst "2002-12-25T00:40:57.688-00:00";; #inst "2013-04-06T17:40:57.688-00:00";; #inst "2025-12-25T11:23:31.123-00:00")
If you’ve been doing more complex work with dates and times and have
Joda-Time objects in hand, then all of this still applies. If you wish
to compare Joda-Time objects to Java time objects, however, you will
have to coerce them to one uniform type using the functions in clj-time.coerce.
1.30. Calculating the Length of a Time Interval
Solution
Since Java date and time classes have poor support for time zones and
leap years, use the clj-time
library for calculating the length of a time interval.
Before starting, add [clj-time "0.6.0"] to your project’s
dependencies or start a REPL using lein-try:
$ lein try clj-timeUse interval along with the numerous in-<unit> helper functions in
the clj-time.core namespace to calculate the difference between
times:
(require'[clj-time.core:ast]);; The first step is to capture two dates as an interval(defsince-april-first(t/interval(t/date-time20130401)(t/now)));; dt is the interval between April Fools Day, 2013 and todaysince-april-first;; -> #<Interval 2013-04-01T00:00:00.000Z/2013-04-06T20:06:30.507Z>(t/in-dayssince-april-first);; -> 5;; Years since the Moon landing(t/in-years(t/interval(t/date-time19690720)(t/now)));; -> 43;; Days from Feb. 28 to March 1 in 2012 (a leap year)(t/in-days(t/interval(t/date-time20120228)(t/date-time20120301)));; -> 2;; And in a non-leap year(t/in-days(t/interval(t/date-time20130228)(t/date-time20130301)));; -> 1
Discussion
Calculating the length of an interval is one of the more
complex operations you can perform with times. Time on Earth is
a complex beast, complicated by constructs like leap time and time
zones; clj-time is the only
library we’re aware of that is capable of wrangling this complexity.
The clj-time.core/interval function takes two dates and returns a
representation of that discrete interval of time. From there, the
clj-time.core namespace includes a myriad of in-<unit> functions
that can present that time interval in different units. These helpers
run the gamut in scale from in-msecs to in-years, covering nearly
every scale useful for nonspecialized applications.
One area clj-time lacks support is for leap seconds. Joda-Time’s
official FAQ explains why
the feature is missing. We’re not aware of any
Clojure library that can reason about time at this granularity. If this
concerns you, then you’re likely one of few people even capable of
doing it right. Good luck to you.
1.31. Generating Ranges of Dates and Times
Solution
This problem has no easy solution in Java, nor does it have one in
Clojure—third-party libraries included. It is possible to use
clj-time to get close, though.
By composing clj-time’s Interval and periodic-seq functionality,
you can create a function time-range that mimics range’s
capabilities, but for DateTimes:
(require'[clj-time.core:astime])(require'[clj-time.periodic:astime-period])(defntime-range"Return a lazy sequence of DateTimes from start to end, incrementedby 'step' units of time."[startendstep](let[inf-range(time-period/periodic-seqstartstep)below-end?(fn[t](time/within?(time/intervalstartend)t))](take-whilebelow-end?inf-range)))
This is how you can use the time-range function:
(defmonths-of-the-year(time-range(time/date-time201201)(time/date-time201301)(time/months1)));; months-of-the-year is an unrealized lazy sequence(realized?months-of-the-year);; -> false(countmonths-of-the-year);; -> 12;; now realized(realized?months-of-the-year);; -> true
Discussion
While there is no ready-made, out-of-the-box time-range solution in
Clojure, it is trivial to construct such a function with purely lazy
semantics. The basis for our lazy time-range function is an infinite sequence of values
with a fixed starting time:
(defntime-range"Return a lazy sequence of DateTimes from start to end, incrementedby 'step' units of time."[startendstep](let[inf-range(time-period/periodic-seqstartstep);below-end?(fn[t](time/within?(time/intervalstartend);t))](take-whilebelow-end?inf-range)));
-
Acquire a lazy infinite sequence.
-
Create a predicate to terminate the sequence.
-
Modify the infinite sequence to terminate when
below-end?fails (lazily, of course).
Invoking periodic-seq with start and step returns an infinite lazy
sequence of values beginning at start, each subsequent value one step
later than the last.
Having a lazy infinite sequence is one thing, but we need a lazy way to
stop acquiring values when end is reached.
The below-end? function
created in let uses clj-time.core/interval to construct an interval from
start to end and clj-time.core/within? to test if a time t falls within
that interval. This function is passed as the predicate to take-while, which
will lazily consume values until below-end? fails.
All together, time-range returns a lazy
sequence of DateTime objects that stretches from a start time to an end time,
stepped appropriately by the provided step value.
Imagine trying to build something similar in a language without first-class laziness.
See Also
1.32. Generating Ranges of Dates and Times Using Native Java Types
Problem
You would like to generate a lazy sequence of dates (or times) beginning with a specific date and time. Further, unlike in Recipe 1.31, “Generating Ranges of Dates and Times”, you would like to do this using only built-in types.
Solution
You can use Java’s java.util.GregorianCalendar class coupled with
Clojure’s repeatedly function to generate a lazy sequence of Gregorian
calendar dates. You can then use java.text.SimpleDateFormat to format the
dates, with a huge variety of output formats available.
This example creates an infinite lazy sequence of Gregorian calendar
dates,[4] beginning
on January 1, 1970 and each spanning a single day. The core take and
drop functions are then used to select the last two days of
February (be careful not to evaluate the infinite sequence itself in
the REPL):
(defdaily-from-epoch(let[start-date(java.util.GregorianCalendar.19700000)](repeatedly(fn[](.addstart-datejava.util.Calendar/DAY_OF_YEAR1)(.clonestart-date)))))(take2(drop57daily-from-epoch));; -> (#inst "1970-02-27T00:00:00.000-07:00";; #inst "1970-02-28T00:00:00.000-07:00")
Discussion
Clojure has no date type of its own; by default, it relies on its
ability to easily interoperate with Java (but see the clj-time library
for alternatives to Java’s date, time, and calendar classes).
This solution is based on the core repeatedly function, which creates a lazy
sequence by repeatedly calling the argument function it is given and returning
a sequence of the function’s results. Because you do not provide the optional,
limiting argument to repeatedly, the result sequences produced are
infinite. Consequently, in the REPL environment, you must be careful to evaluate
your result sequences in contexts (such as take and drop) that
limit the values produced.
Since the function given to repeatedly is a function of no arguments, it is
presumed to achieve its goals by side effects (making it an impure function).
Here, the impurity occurs as the argument function creates a Gregorian calendar
date and repeatedly increments it by a single java.util.Calendar day
unit. For each call of the function, it returns a copy of the Gregorian calendar
object (to avoid mysterious and unintended side effects, it is advisable to
avoid returning the mutated object directly).
The date values in the result sequence are of type
java.util.GregorianCalendar, but the print function of the REPL displays
them as an #inst reader literal. You can verify that the sequence elements
are Gregorian calendar objects by mapping the class (or type) function onto the
sequence:
(defend-of-feb(take2(drop57daily-from-epoch)))(map classend-of-feb);; -> (java.util.GregorianCalendar java.util.GregorianCalendar)
You can generalize the solution to a function that takes a starting year argument but defaults to some convenient year if the argument is not provided:
(defndaily-from-year[&[start-year]](let[start-date(java.util.GregorianCalendar.(orstart-year1970)0000)](repeatedly(fn[](.addstart-datejava.util.Calendar/DAY_OF_YEAR1)(.clonestart-date)))))(take3(daily-from-year1999));; -> (#inst "1999-01-01T00:00:00.000-07:00";; #inst "1999-01-02T00:00:00.000-07:00";; #inst "1999-01-03T00:00:00.000-07:00")(take2(daily-from-year));; -> (#inst "1970-01-01T00:00:00.000-07:00";; #inst "1970-01-02T00:00:00.000-07:00")
Using the java.text.SimpleDateFormat class, you can then format the dates in a
wide variety of different formats:
(defend-of-days(take3(drop353(daily-from-year2012))))(defcal-format(java.text.SimpleDateFormat."EEE M/d/yyyy"))(defiso8601-format(java.text.SimpleDateFormat."yyyy-MM-dd'T'HH:mm:ss'Z'"))(map#(.formatcal-format(.getTime%))end-of-days);; -> ("Wed 12/19/2012" "Thu 12/20/2012" "Fri 12/21/2012")(map#(.formatiso8601-format(.getTime%))end-of-days);; -> ("2012-12-19T00:00:00Z" "2012-12-20T00:00:00Z" "2012-12-21T00:00:00Z")
To put it all together, create a function that generates an infinite lazy sequence of formatted Gregorian date strings. For convenience, the function takes optional starting year and date format string arguments:
(defngregorian-day-seq"Return an infinite sequence of formatted Gregorian day stringsstarting on January 1st of the given year (default 1970)"[&[start-yeardate-format]](let[gd-format(java.text.SimpleDateFormat.(ordate-format"EEE M/d/yyyy"))start-date(java.util.GregorianCalendar.(orstart-year1970)0000)](repeatedly(fn[](.addstart-datejava.util.Calendar/DAY_OF_YEAR1)(.formatgd-format(.getTimestart-date))))))
To test the function, select the last Sunday of the year by finding all of the Sundays in a year:
(defy2k(take366(gregorian-day-seq2000)))(last(filter#(.startsWith%"Sun")y2k));; -> "Sun 12/31/2000"
See Also
-
Recipe 1.25, “Obtaining the Current Date and Time”, for information on using
java.util.Datefrom Clojure -
Recipe 1.26, “Representing Dates as Literals”, to learn about Clojure’s
#instreader literal for date/times -
Recipe 1.31, “Generating Ranges of Dates and Times”, for an alternative that utilizes
clj-time/Joda-Time
1.33. Retrieving Dates Relative to One Another
Problem
You need to calculate a time relative to some other time, à la
Ruby on Rails’ 2.days.from_now.
Solution
Because relative time is such a complex beast, we suggest using
clj-time for calculating
relative dates and times.
Before starting, add [clj-time "0.6.0"] to your project’s
dependencies or start a REPL using lein-try:
$ lein try clj-timeIf you’ve used the Ruby on Rails framework, then you’re likely
accustomed to statements like 1.day.from_now, 3.days.ago, or
some_date - 2.years. You’ll be pleased to know that clj-time exposes
similar functionality:
(require'[clj-time.core:ast]);; 1.day.from_now (it's April 6 at the time of this writing)(->1t/dayst/from-now);; -> #<DateTime 2013-04-07T20:36:52.012Z>;; 3.days.ago(->3t/dayst/ago);; -> #<DateTime 2013-04-03T20:37:06.844Z>
The clj-time.core functions from-now and ago are just syntactic sugar
over plus and minus:
;; 1.day.from_now(t/plus(t/now)(t/years1));; -> #<DateTime 2014-04-06T20:41:43.638Z>;; some_date - 2.years(defsome-date(t/date-time20531225))(t/minussome-date(t/years2));; -> #<DateTime 2051-12-25T00:00:00.000Z>
Discussion
Despite how difficult dates and times can sometimes be in Java,
clj-time manages to expose a joyful syntax for adding to and
subtracting from dates.
The functions plus, minus, from-now, and ago all take a period
of time and adjust a DateTime by that amount (be that time “now,” as
in from-now or ago, or some provided time).
clj-time.core
includes a number of useful period helpers ranging from millis to
years that produce a time period at a given scale.
Depending on your use case, it’s even possible to arrange operation, time period, and time in such a manner that they almost read like a sentence.
Take (-> 1 t/years t/from-now), for example. In this case,
the threading macro -> threads each value as an argument to the next,
producing (t/from-now (t/years 1)).
It’s up to you to arrange your function calls as you see fit, but know that it is quite possible to produce readable deep-nested calls like this.
1.34. Working with Time Zones
Solution
The JVM’s built-in time and date classes don’t work well with the notion
of time zones. For one, Date treats every value as UTC, and Calendar is
cumbersome to work with in Clojure (or Java, for that matter). Use
clj-time to properly deal with
time zones.
Before starting, add [clj-time "0.6.0"] to your project’s
dependencies or start a REPL using lein-try:
$ lein try clj-time(require'[clj-time.core:ast]);; My birth-time, in the correct time zone(defbday(t/from-time-zone(t/date-time2012021818)(t/time-zone-for-offset-6)))bday;; -> #<DateTime 2012-02-18T18:00:00.000-06:00>;; What time was it in Brisbane when I was born?(defaustralia-bday(t/to-time-zonebday(t/time-zone-for-id"Australia/Brisbane")))australia-bday;; -> #<DateTime 2012-02-19T10:00:00.000+10:00>;; Yet they are the same instant in time.(comparebdayaustralia-bday);; -> 0
Discussion
Unlike Java built-ins, clj-time knows a lot about time zones.
Joda-Time, the library clj-time
wraps, bundles the internationally recognized
tz database. This database
captures the IDs and time offsets for nearly every location on the
planet.
The tz database also captures information about daylight saving time.
For example, Los Angeles is UTC-08:00 in the winter and UTC-07:00
during the summer. This is accurately reflected when using clj-time:
(defla-tz(t/time-zone-for-id"America/Los_Angeles"));; LA is UTC-08:00 in winter(t/from-time-zone(t/date-time20120101)la-tz);; -> #<DateTime 2012-01-01T00:00:00.000-08:00>;; ... and UTC-07:00 in summer(t/from-time-zone(t/date-time20120601)la-tz);; -> #<DateTime 2012-06-01T00:00:00.000-07:00>
The clj-time.core/from-time-zone function takes any DateTime and
modifies its time zone to the desired time zone. This is useful
in cases where you receive a date, time, and time zone separately
and want to combine them into an accurate DateTime instance.
The clj-time.core/to-time-zone function has the same signature as
from-time-zone; it returns a DateTime for the exact same point in
time, but from the perspective of another time zone. This is useful
for presenting time and date information from disparate sources to a
user in her preferred time zone.
Sometimes you may only want to deal with machine-local time. The
clj-time.local namespace provides a number of functions to that end,
including local-now, for getting a time in the local time zone, and
to-local-date-time, which shifts the perspective of a time to the
local time zone.
1.35. Converting a Unix Timestamp to a Date
Solution
When dealing with data from outside systems, you’ll find that many systems express timestamps in Unix time format. You may encounter this when dealing with certain datastores, parsing out data from timestamps in log files, or working with any number of other systems that have to deal with dates and times across multiple different time zones and cultures.
Fortunately, with Clojure’s ability for nice interoperability with Java, you have an easy solution at hand:
(defnfrom-unix-time"Return a Java Date object from a Unix time representation expressedin whole seconds."[unix-time](java.util.Date.unix-time))
This is how you can use the from-unix-time function:
(from-unix-time1366127520000);; -> #inst "2013-04-16T15:52:00.000-00:00"
Discussion
To get a Java Date object from a Unix time object, all you need to
do is construct a new
java.util.Date
object using Clojure’s Java interop functionality.
If you are already using or wish to use the
clj-time library, you can use clj-time
to obtain a DateTime object from a Unix timestamp:
(require'[clj-time.coerce:astimec])(defndatetime-from-unix-time"Return a DateTime object from a Unix time representation expressedin whole seconds."[unix-time](timec/from-longunix-time))
And using the datetime-from-unix-time function, you can see you get a
DateTime object back with the correct time:
(datetime-from-unix-time1366127520000);; -> #<DateTime 2013-04-16T15:52:00.000Z>
You may not need to worry about dates and times being expressed as seconds very often, but when you do, isn’t it nice to know how easy it can be to get those timestamps into a date format used by the rest of the system?
1.36. Converting a Date to a Unix Timestamp
Solution
Many systems express timestamps in Unix time format, and when you have to interact with these systems, you have to give them date and time information in the format they desire.
Fortunately, with Clojure’s ability for nice interoperability with Java, you have an easy solution at hand:
(defnto-unix-time"Returns a Unix time representation expressed in whole secondsgiven a java.util.Date."[date](.getTimedate))
This is how you can use the to-unix-time function:
(defdate(read-string"#inst \"2013-04-16T15:52:00.000-00:00\""));; -> #'user/date(to-unix-timedate);; -> 1366127520000
Discussion
When you have a java.util.Date object, you can use the Java interop
provided by Clojure as an easy way to get the time represented as a Unix
time. Java’s Date objects have a method called getTime that returns the
date as a Unix time.
If you are already using or wish to use the
clj-time library, you can use clj-time
to obtain a Unix time–formatted DateTime object if you have a DateTime object:
(require'[clj-time.coerce:astimec])(defndatetime-to-unix-time"Returns a Unix time representation expressed in whole secondsgiven a DateTime."[datetime](timec/to-longdatetime))
And using the datetime-to-unix-time function, you can see you get a
Unix time format for a DateTime object:
(defdatetime(clj-time.core/date-time201304161552));; #'user/datetime(datetime-to-unix-timedatetime);; 1366127520000
Thanks to clj-time.coerce, all that is needed is to use the function
to-long to get a Joda-Time DateTime object into a Unix time format.
Your system may never need to interact with other systems that expect
timestamps expressed in Unix time, but if you are designing a system
that does, Clojure makes it very easy to express a Date or DateTime in
Unix time format.
[1] The JVM is where Java bytecode is executed. The Clojure compiler targets the JVM by emitting bytecode to be run there; thus, you have all of the native Java types at your disposal.
[2] By using use, you introduce numerous new symbols into your
project’s namespaces without leaving any clues as to where they came
from. This is often confusing and frustrating for maintainers of the
code base. We highly suggest you avoid use.
[3] If
you haven’t already installed lein-try, follow the instructions in
Our Golden Boy, lein-try.
Get Clojure Cookbook now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

