Chapter 5. Spark
Background
Apache Spark is an open source cluster computing framework originally developed at UC Berkeley in the AMPLab. Spark is a fast and flexible alternative to both stream and batch processing systems like Storm and MapReduce, and can be integrated as a part of batch processing, stream processing, machine learning, and more. A recent survey of 2,100 developers revealed that 82% would choose Spark to replace MapReduce.
Characteristics of Spark
Spark is a versatile distributed data processing engine, providing a rich language for data scientists to explore data. It comes with an ever-growing suite of libraries for analytics and stream processing.
Spark Core consists of a programming interface and a distributed execution environment. On top of this core platform, the Spark developer community has built several libraries including Spark Streaming, MLlib (for machine learning), Spark SQL, and GraphX (for graph analytics) (Figure 5-1). As of version 1.3, Spark SQL was repackaged as the DataFrame API. Beyond acting as a SQL server, the DataFrame API is meant to provide a general purpose library for manipulating structured data.
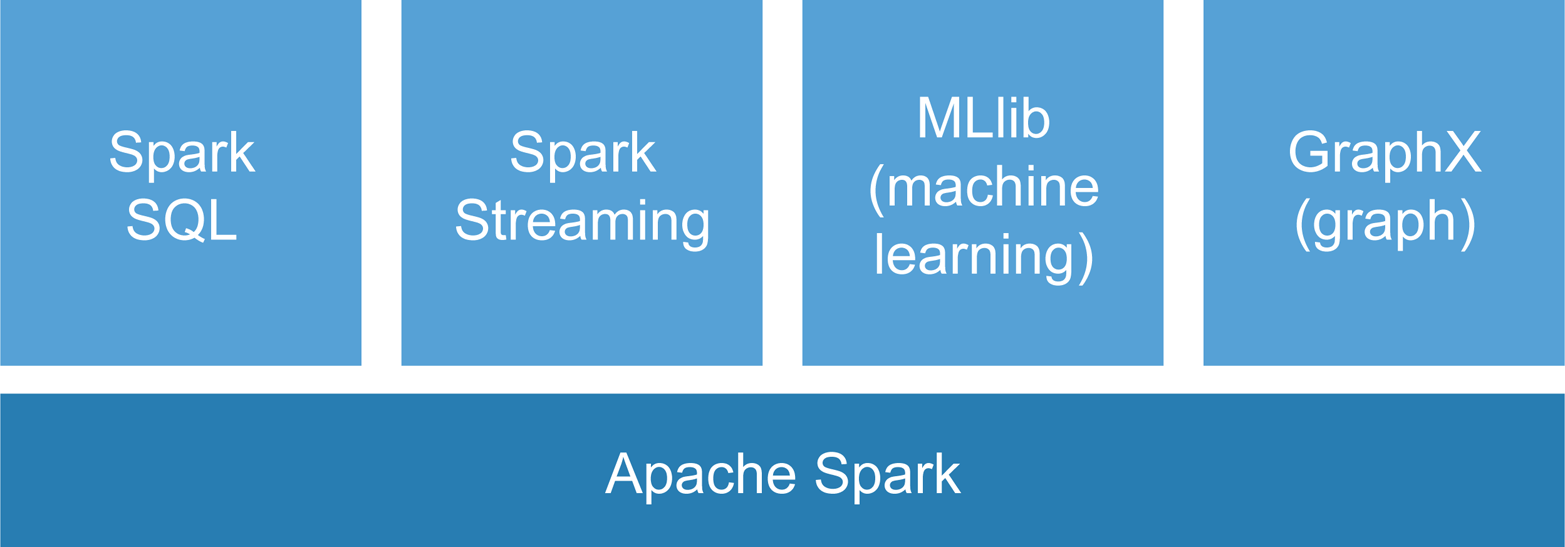
Figure 5-1. Spark data processing framework
The Spark execution engine keeps data in memory and has the ability to schedule jobs distributed over many nodes. Integrating Spark with other in-memory systems, like an in-memory database, ...
Get Building Real-Time Data Pipelines now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

