Chapter 4. Processing Transactions and Analytics in a Single Database
The thought of running transactions and analytics in a single database is not completely new, but until recently, limitations in technology and legacy infrastructure have stalled adoption. Now, innovations in database architecture and in-memory computing have made running transactions and analytics in a single database a reality.
Requirements for Converged Processing
Converging transactions and analytics in a single database requires technology advances that traditional database management systems and NoSQL databases are not capable of supporting. To enable converged processing, the following features must be met.
In-Memory Storage
Storing data in memory allows reads and writes to occur orders of magnitude faster than on disk. This is especially valuable for running concurrent transactional and analytical workloads, as it alleviates bottlenecks caused by disk contention. In-memory operation is necessary for converged processing as no purely disk-based system will be able to deliver the input/output (I/O) required with any reasonable amount of hardware.
Access to Real-Time and Historical Data
In addition to speed, converged processing requires the ability to compare real-time data to statistical models and aggregations of historical data. To do so, a database must be designed to facilitate two kinds of workloads: (1) high-throughput operational and (2) fast analytical queries. With two powerful storage engines, real-time and historical data can be converged into one database platform and made available through a single interface.
Compiled Query Execution Plans
Without disk I/O, queries execute so quickly that dynamic SQL interpretation can become a bottleneck. This can be addressed by taking SQL statements and generating a compiled query execution plan. Compiled query plans are core to sustaining performance advantages for converged workloads. To tackle this, some databases will use a caching layer on top of their RDBMS. Although sufficient for immutable datasets, this approach runs into cache invalidation issues against a rapidly changing dataset, and ultimately results in little, if any, performance benefit. Executing a query directly in memory is a better approach, as it maintains query performance, even when data is frequently updated (Figure 4-1).
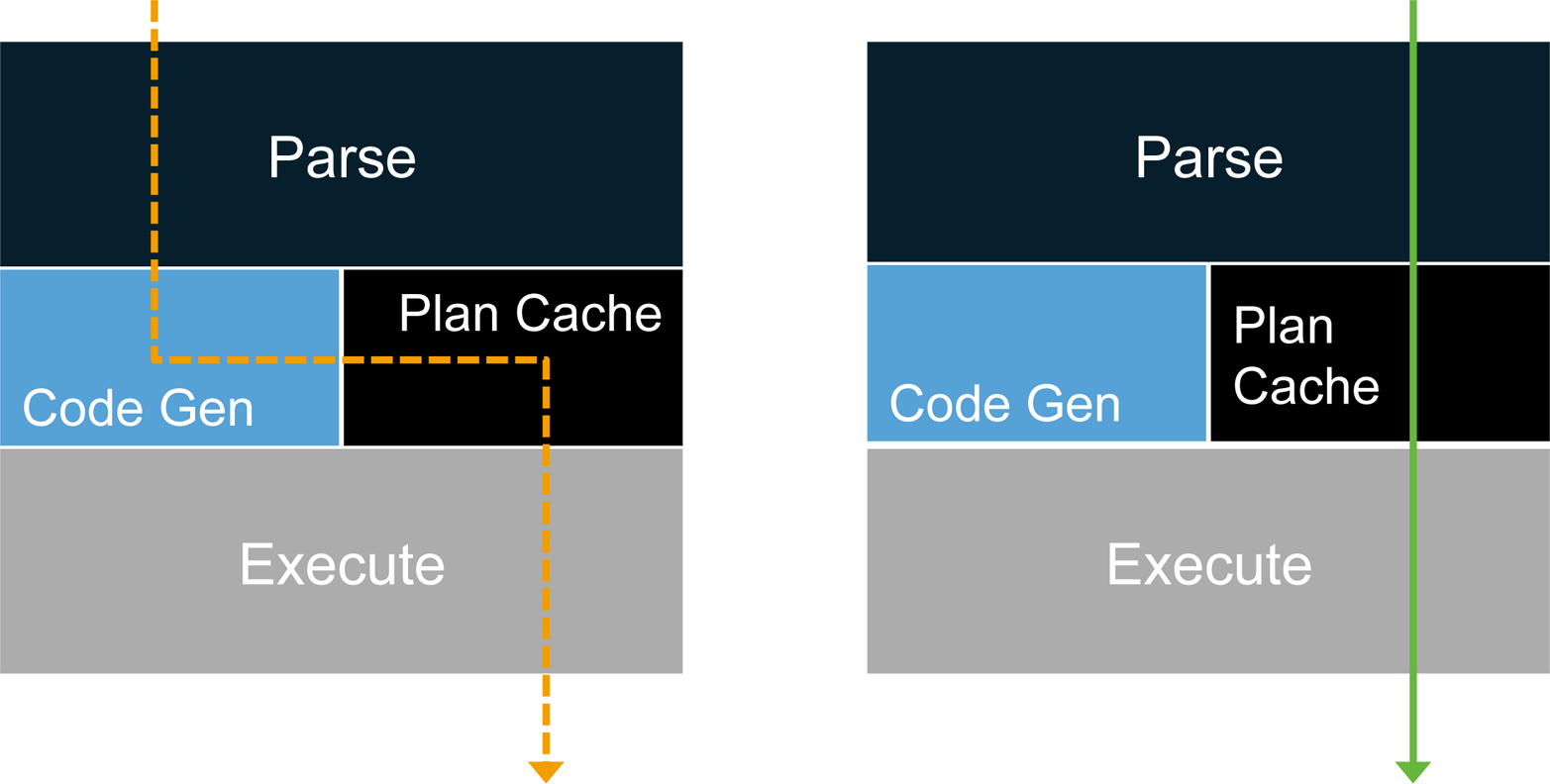
Figure 4-1. Compiled query execution plans
Granular Concurrency Control
Reaching the throughput necessary to run transactions and analytics in a single database can be achieved with lock-free data structures and multiversion concurrency control (MVCC). This allows the database to avoid locking on both reads and writes, enabling data to be accessed simultaneously. MVCC is especially critical during heavy write workloads such as loading streaming data, where incoming data is continuous and constantly changing (Figure 4-2).

Figure 4-2. Lock-free data structures
Fault Tolerance and ACID Compliance
Fault tolerance and ACID compliance are prerequisites for any converged data processing systems, as operational data stores cannot lose data. To ensure data is never lost, a database should include redundancy in the cluster and cross-datacenter replication for disaster recovery. Writing database logs and complete snapshots to disk can also be used to ensure data integrity.
Benefits of Converged Processing
Many organizations are turning to in-memory computing for the ability to run transactions and analytics in a single database of record. For data-centric organizations, this optimized way of processing data results in new sources of revenue and a simplified computing structure that reduces costs and administrative overhead.
Enabling New Sources of Revenue
Many databases promise to speed up applications and analytics. However, there is a fundamental difference between simply speeding up existing business infrastructure and actually opening up new channels of revenue. True “real-time analytics” does not simply mean faster response times, but analytics that capture the value of data before it reaches a specified time threshold, usually some fraction of a second.
An example of this can be illustrated in financial services, where investors must be able to respond to market volatility in an instant. Any delay is money out of their pockets. Taking a single-database approach makes it possible for these organizations to respond to fluctuating market conditions as they happen, providing more value to investors.
Reducing Administrative and Development Overhead
By converging transactions and analytics, data no longer needs to move from an operational database to a siloed data warehouse or data mart to run analytics. This gives data analysts and administrators more time to concentrate efforts on business strategy, as ETL often takes hours, and in some cases longer, to complete.
Simplifying Infrastructure
By serving as a database of record and analytical warehouse, a hybrid database can significantly simplify an organization’s data processing infrastructure by functioning as the source of day-to-day operational workloads.
There are many advantages to maintaining a simple computing infrastructure:
- Increased uptime
- A simple infrastructure has fewer potential points of failure, resulting in fewer component failures and easier problem diagnosis.
- Reduced latency
- There is no way to avoid latency when transferring data between data stores. Data transfer necessitates ETL, which is time consuming and introduces opportunities for error. The simplified computing structure of a converged processing database foregoes the entire ETL process.
- Synchronization
- With a hybrid database architecture, drill-down from analytic aggregates always points to the most recent application data. Contrast that to traditional database architectures where analytical and transactional data is siloed. This requires a cumbersome synchronization process and an increased likelihood that the “analytics copy” of data will be stale, providing a false representation of data.
- Copies of data
- In a converged processing system, the need to create multiple copies of the same data is eliminated, or at the very least reduced. Compared to traditional data processing systems, where copies of data must be managed and monitored for consistency, a single system architecture reduces inaccuracies and timing differences associated with data duplication.
- Faster development cycles
- Developers work faster when they can build on fewer, more versatile tools. Different data stores likely have different query languages, forcing developers to spend hours familiarizing themselves with the separate systems. When they also have different storage formats, developers must spend time writing ETL tools, connectors, and synchronization mechanisms.
Conclusion
Many innovative organizations are already proving that access to real-time analytics, and the ability to power applications with real-time data, brings a substantial competitive advantage to the table. For businesses to support emerging trends like the Internet of Things and the high expectations of users, they will have to operate in real time. To do so, they will turn to converged data processing, as it offers the ability to forego ETL and simplify database architecture.
Get Building Real-Time Data Pipelines now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

