
This is the Title of the Book, eMatter Edition
Copyright © 2012 O’Reilly & Associates, Inc. All rights reserved.
19
Chapter 2
CHAPTER 2
Biological Sequences
Sequence similarity is a powerful tool for discovering biological function. Just as the
ancient Greeks used comparative anatomy to understand the human body and lin-
guists used the Rosetta stone to decipher Egyptian hieroglyphs, today we can use
comparative sequence analysis to understand genomes, RNAs, and proteins. But why
are biological sequences similar to one another in the first place? The answer to this
question isn’t simple and requires an understanding of molecular and evolutionary
biology.
The Central Dogma of Molecular Biology
Most courses in molecular biology begin with the Central Dogma of Molecular Biol-
ogy, which describes the path by which information contained in DNA is converted
to protein molecules with specific functions. Stated simply, the Central Dogma is:
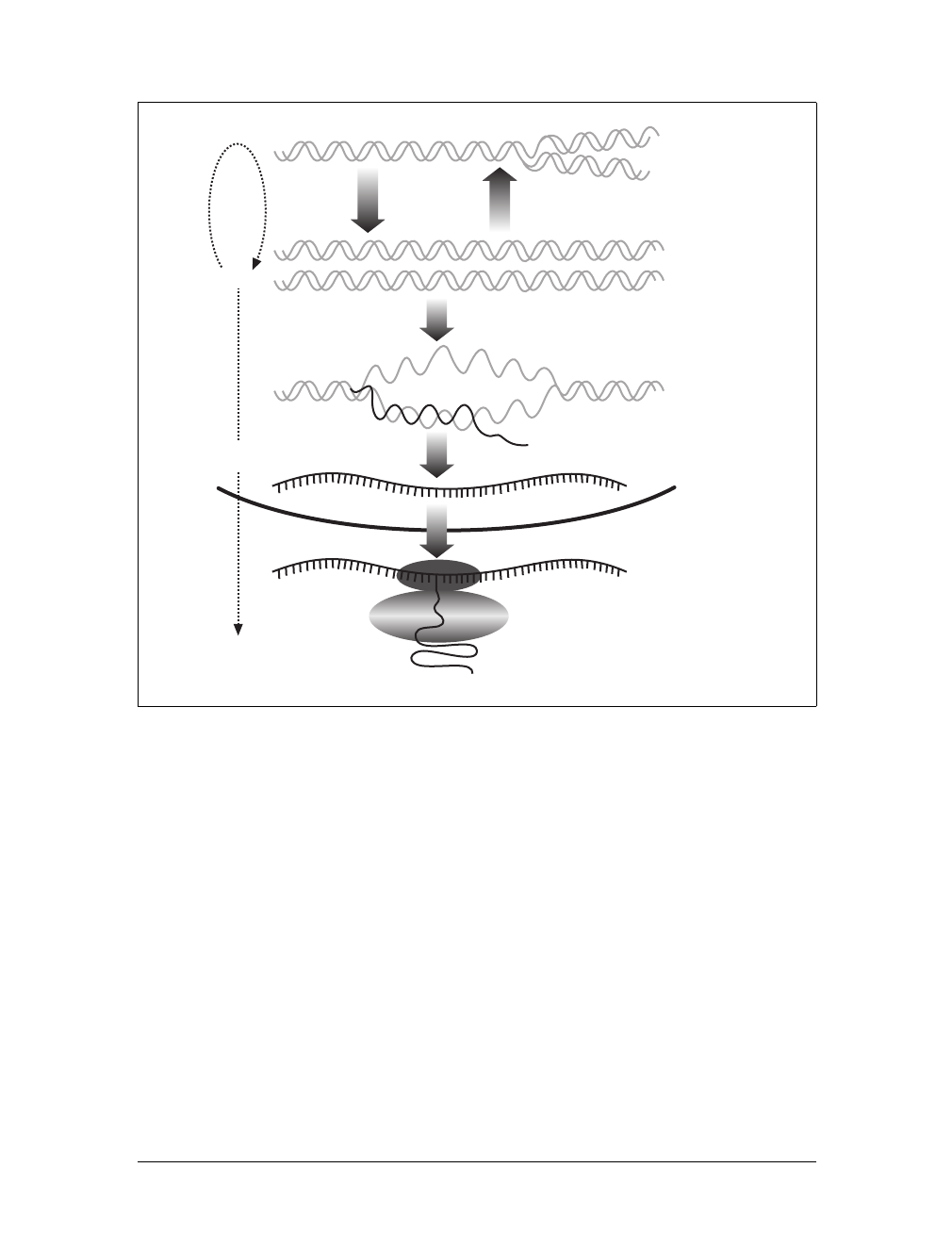
“from DNA to RNA to protein.” Figure 2-1 shows a more complete diagram of this
process and will be referenced throughout this section.
DNA
The hereditary material that carries the blueprint for an organism from one genera-
tion to the next is called deoxyribonucleic acid. It is much more commonly referred
to by its acronym, DNA. Every time cells divide, the DNA is duplicated in a process
called DNA replication. The entire DNA of an organism is called its genome, and
genomes are sometimes called “the book of life” (especially with respect to the
human genome). Reading and understanding the various books of life is one of the
most important quests of the genomic age. Modern medicine, agriculture, and indus-
try will increasingly depend on an intimate knowledge of genomes to develop indi-
vidualized medicines, select and modify the most desirable traits in plants and
animals, and understand the relationships among species.
This is the Title of the Book, eMatter Edition
Copyright © 2012 O’Reilly & Associates, Inc. All rights reserved.
20
|
Chapter 2: Biological Sequences
The language of DNA is complicated. Over the last 50 years, scientists have begun to
decipher it, but it is still largely a mystery. Although the language is elusive, the
alphabet is simple, consisting of just four nucleotides: adenine, cytosine, guanine,
and thymine. For simplicity in both speech and on the computer, they are usually
abbreviated as A, C, G, and T. DNA usually exists as a double-stranded molecule,
but we generally talk about just one strand at a time. Here’s an example of a DNA
sequence that is six nucleotides (nt) long:
GAATTC
DNA has polarity, like a battery, but its ends are referred to as 5-prime (5´) and 3-
prime (3´) rather than plus and minus. This nomenclature comes from the chemical
structure of DNA. While it isn’t necessary to understand the chemical structure, the
terminology is important. For example, when people say “the 5´ end of the gene,”
they mean the beginning of the gene. We usually display DNA sequence as we read
text, left to right, and the convention is that the left side is the 5´ end and the right
side is the 3´ end.
Figure 2-1. The Central Dogma of Molecular Biology: DNA to RNA to protein
DNA
Information
Replication
DNA duplicate
Information
Transcription
RNA sythesis
mRNA
Nucleus
Information
Cytoplasm
Nuclear envelope
Translation
Protein sythesis
Protein
RI bosome
Protein
DNA
RNA
Get BLAST now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

