Even if you have petabyes of data, you still need to know how to ask the right questions to apply it.
âYou know,â said a good friend of mine last week, âthereâs really no such thing as big data.â
I sighed a bit inside. In the past few years, cloud computing critics have said similar things: that clouds are nothing new, that theyâre just mainframes, that theyâre just painting old technologies with a cloud brush to help sales. Iâm wary of this sort of techno-Luddism. But this person is sharp, and not usually prone to verbal linkbait, so I dug deeper.
Heâs a ridiculously heavy traveler, racking up hundreds of thousands of miles in the air each year. Heâs the kind of flier airlines dream of: loyal, well-heeled, and prone to last-minute, business-class trips. Heâs is exactly the kind of person an airline needs to court aggressively, one who represents a disproportionally large amount of revenues. Heâs an outlier of the best kind. Heâd been a top-ranked passenger with United Airlines for nearly a decade, using their Mileage Plus program for everything from hotels to car rentals.
And then his company was acquired.
The acquiring firm had a contractual relationship with American Airlines, a competitor of United with a completely separate loyalty program. My friendâs air travel on United and its partner airlines dropped to nearly nothing.
He continued to book hotels in Shanghai, rent cars in Barcelona, and buy meals in Tahiti, and every one of those transactions was tied to his loyalty program with United. So the airline knew he was travelingâjust not with them.
Astonishingly, nobody ever called him to inquire about why heâd stopped flying with them. As a result, heâs far less loyal than he was. But more importantly, United has lost a huge opportunity to try to win over a large companyâs business, with a passionate and motivated inside advocate.
And this was his point about big data: that given how much traditional companies put it to work, it might as well not exist. Companies have countless ways they might use the treasure troves of data they have on us. Yet all of this data lies buried, sitting in silos. It seldom sees the light of day.
When a company does put data to use, itâs usually a disruptive startup. Zappos and customer service. Amazon and retailing. Craigslist and classified ads. Zillow and house purchases. LinkedIn and recruiting. eBay and payments. Ryanair and air travel. One by one, industry incumbents are withering under the harsh light of data.
Large companies with entrenched business models tend to cling to their buggy-whips. They have a hard time breaking their own business models, as Clay Christensen so clearly stated in âThe Innovatorâs Dilemma,â but itâs too easy to point the finger at simple complacency.
Early-stage companies have a second advantage over more established ones: they can ask for forgiveness instead of permission. Because they have less to lose, they can make risky bets. In the early days of PayPal, the company could skirt regulations more easily than Visa or Mastercard, because it had far less to fear if it was shut down. This helped it gain marketshare while established credit-card companies were busy with paperwork.
The real problem is one of asking the right questions.
At a big data conference run by The Economist this spring, one of the speakers made a great point: Archimedes had taken baths before.
(Quick historical recap: In an almost certainly apocryphal tale, Hiero of Syracuse had asked Archimedes to devise a way of measuring density, an indicator of purity, in irregularly shaped objects like gold crowns. Archimedes realized that the level of water in a bath changed as he climbed in, making it an indicator of volume. Eureka!)
The speakerâs point was this: it was the question that prompted Archimedesâ realization.
Small, agile startups disrupt entire industries because they look at traditional problems with a new perspective. Theyâre fearless, because they have less to lose. But big, entrenched incumbents should still be able to compete, because they have massive amounts of data about their customers, their products, their employees, and their competitors. They fail because often they just donât know how to ask the right questions.
In a recent study, McKinsey found that by 2018, the U.S. will face a shortage of 1.5 million managers who are fluent in data-based decision making. Itâs a lesson not lost on leading business schools: several of them are introducing business courses in analytics.
Ultimately, this is what my friendâs airline example underscores. It takes an employee, deciding that the loss of high-value customers is important, to run a query of all their data and find him, and then turn that into a business advantage. Without the right questions, there really is no such thing as big dataâand today, itâs the upstarts that are asking all the good questions.
When it comes to big data, you either use it or lose.
This is what weâre hoping to explore at Strata JumpSsart in New York next month. Rather than taking a vertical look at a particular industry, weâre looking at the basics of business administration through a big data lens. Weâll be looking at apply big data to HR, strategic planning, risk management, competitive analysis, supply chain management, and so on. In a world flooded by too much data and too many answers, tomorrowâs business leaders need to learn how to ask the right questions.
Low costs and cloud tools are empowering new data startups.
This is a written follow-up to a talk presented at a recent Strata online event.
A new breed of startup is emerging, built to take advantage of the rising tides of data across a variety of verticals and the maturing ecosystem of tools for its large-scale analysis.
These are data startups, and they are the sumo wrestlers on the startup stage. The weight of data is a source of their competitive advantage. But like their sumo mentors, size alone is not enough. The most successful of data startups must be fast (with data), big (with analytics), and focused (with services).
The question of why this style of startup is arising today, versus a decade ago, owes to a confluence of forces that I call the Attack of the Exponentials. In short, over the past five decades, the cost of storage, CPU, and bandwidth has been exponentially dropping, while network access has exponentially increased. In 1980, a terabyte of disk storage cost $14 million dollars. Today, itâs at $30 and dropping. Classes of data that were previously economically unviable to store and mine, such as machine-generated log files, now represent prospects for profit.
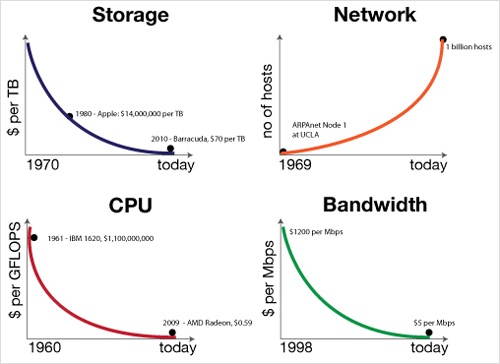
At the same time, these technological forces are not symmetric: CPU and storage costs have fallen faster than that of network and disk IO. Thus data is heavy; it gravitates toward centers of storage and compute power in proportion to its mass. Migration to the cloud is the manifest destiny for big data, and the cloud is the launching pad for data startups.
As the foundational layer in the big data stack, the cloud provides the scalable persistence and compute power needed to manufacture data products.
At the middle layer of the big data stack is analytics, where features are extracted from data, and fed into classification and prediction algorithms.
Finally, at the top of the stack are services and applications. This is the level at which consumers experience a data product, whether it be a music recommendation or a traffic route prediction.
Letâs take each of layers and discuss the competitive axes at each.
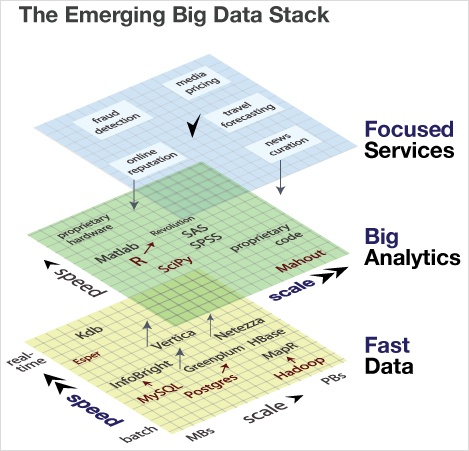
The competitive axes and representative technologies on the Big Data stack are illustrated here. At the bottom tier of data, free tools are shown in red (MySQL, Postgres, Hadoop), and we see how their commercial adaptations (InfoBright, Greenplum, MapR) compete principally along the axis of speed; offering faster processing and query times. Several of these players are pushing up towards the second tier of the data stack, analytics. At this layer, the primary competitive axis is scale: few offerings can address terabyte-scale data sets, and those that do are typically proprietary. Finally, at the top layer of the big data stack lies the services that touch consumers and businesses. Here, focus within a specific sector, combined with depth that reaches downward into the analytics tier, is the defining competitive advantage.
At the base of the big data stack â where data is stored, processed, and queried â the dominant axis of competition was once scale. But as cheaper commodity disks and Hadoop have effectively addressed scalable persistence and processing, the focus of competition has shifted toward speed. The demand for faster disks has led to an explosion in interest in solid-state disk firms, such as Fusion-IO, which went public recently. And several startups, most notably MapR, are promising faster versions of Hadoop.
FusionIO and MapR represent another trend at the data layer: commercial technologies that challenge open source or commodity offerings on an efficiency basis, namely watts or CPU cycles consumed. With energy costs driving between one-third and one-half of data center operating costs, these efficiencies have a direct financial impact.
Finally, just as many large-scale, NoSQL data stores are moving from disk to SSD, others have observed that many traditional, relational databases will soon be entirely in memory. This is particularly true for applications that require repeated, fast access to a full set of data, such as building models from customer-product matrices. This brings us to the second tier of the big data stack, analytics.
At the second tier of the big data stack, analytics is the brains to cloud computingâs brawn. Here, however, the speed is less of a challenge; given an addressable data set in memory, most statistical algorithms can yield results in seconds. The challenge is scaling these out to address large datasets, and rewriting algorithms to operate in an online, distributed manner across many machines.
Because data is heavy, and algorithms are light, one key strategy is to push code deeper to where the data lives, to minimize network IO. This often requires a tight coupling between the data storage layer and the analytics, and algorithms often need to be re-written as user-defined functions (UDFs) in a language compatible with the data layer. Greenplum, leveraging its Postgres roots, supports UDFs written in both Java and R. Following Googleâs BigTable, HBase is introducing coprocessors in its 0.92 release, which allows Java code to be associated with data tablets, and minimize data transfer over the network. Netezza pushes even further into hardware, embedding an array of functions into FPGAs that are physically co-located with the disks of its storage appliances.
The field of whatâs alternatively called business or predictive analytics is nascent, and while a range of enabling tools and platforms exist (such as R, SPSS, and SAS), most of the algorithms developed are proprietary and vertical-specific. As the ecosystem matures, one may expect to see the rise of firms selling analytical services â such as recommendation engines â that interoperate across data platforms. But in the near-term, consultancies like Accenture and McKinsey, are positioning themselves to provide big analytics via billable hours.
Outside of consulting, firms with analytical strengths push upward, surfacing focused products or services to achieve success.
The top of the big data stack is where data products and services directly touch consumers and businesses. For data startups, these offerings more frequently take the form of a service, offered as an API rather than a bundle of bits.
BillGuard is a great example of a startup offering a focused data service. It monitors customersâ credit card statements for dubious charges, and even leverages the collective behavior of users to improve its fraud predictions.
Several startups are working on algorithms that can crack the content relevance nut, including Flipboard and News.me. Klout delivers a pure data service that uses social media activity to measure online influence. My company, Metamarkets, crunches server logs to provide pricing analytics for publishers.
For data startups, data processes and algorithms define their competitive advantage. Poor predictions â whether of fraud, relevance, influence, or price â will sink a data startup, no matter how well-designed their web UI or mobile application.
Focused data services arenât limited to startups: LinkedInâs People You May Know and FourSquareâs Explore feature enhance engagement of their companiesâ core products, but only when they correctly suggest people and places.
The axes of strategy in the big data stack show analytics to be squarely at the center. Data platform providers are pushing upwards into analytics to differentiate themselves, touting support for fast, distributed code execution close to the data. Traditional analytics players, such as SAS and SAP, are expanding their storage footprints and challenging the need for alternative data platforms as staging areas. Finally, data startups and many established firms are creating services whose success hinges directly on proprietary analytics algorithms.
The emergence of data startups highlights the democratizing consequences of a maturing big data stack. For the first time, companies can successfully build offerings without deep infrastructure know-how and focus at a higher level, developing analytics and services. By all indications, this is a democratic force that promises to unleash a wave of innovation in the coming decade.
Gnipâs Jud Valeski on data resellers, end-user responsibility, and the threat of black markets.
by Julie Steele
Jud Valeski (@jvaleski) is cofounder and CEO of Gnip, a social media data provider that aggregates feeds from sites like Twitter, Facebook, Flickr, delicious, and others into one API.
Jud will be speaking at Strata next week on a panel titled âWhatâs Mine is Yours: the Ethics of Big Data Ownership.â
If youâre attending Strata, you can also find out more about growing business of data marketplaces at a âData Marketplacesâ panel with Ian White of Urban Mapping, Peter Marney of Thomson Reuters, Moe Khosravy of Microsoft, and Dennis Yang of Infochimps.
My interview with Jud follows.
Why is social media data important? What can we do with it or learn from it?
Jud Valeski: Social media today is the first time a reasonably large population has communicated digitally in relative public. The ability to programmatically analyze collective conversation has never really existed. Being able to analyze the collective human consciousness has been the dream of researchers and analysts since day one.
The data itself is important because it can be analyzed to assist in disaster detection and relief. It can be analyzed for profit in an industry that has always struggled to pinpoint how and where to spend money. It can be analyzed to determine financial market viability (stock trading, for example). It can be analyzed to understand community sentiment, which has political ramifications; we all want our voices heard in order to shape public policy.
What are some of the most common or surprising queries run through Gnip?
Jud Valeski: We donât look at the queries our customers use. One pattern we have seen, however, is that there are some people who try to use the software to siphon as much data as possible out of a given publisher. âMore data, more data, more data.â We hear that all the time. But how our customers configure the Gnip software is up to them.
With Gnip, customers can choose the data sources they want not just by site but also by category within the site. Can you tell me more about the options for Twitter, which include Decahose, Halfhose, and Spritzer?
Jud Valeski: We tend to categorize social media sources into three buckets: Volume, Coverage, or Both. Volume streams provide a consumer with a sampled rate of volume (Decahose is 10%, for example, while a full firehose is 100% of some serviceâs activities). Statisticians and analysts like the Volume stuff.
Coverage streams exist to provide full coverage of a certain set of things (e.g., keywords, or the User Mention Stream for Twitter). Advertisers like Coverage streams because their interests are very targeted. There are some products that fall into both categories, but Volume and Coverage tend to describe the overall view.
For Twitter in particular, we use their algorithm as described on their dev pages, adjusted for each particular volume rate desired.
Gnip is currently the only licensed reseller of the full Twitter firehose. Are there other partnerships coming up?
Jud Valeski: âCurrentlyâ is the operative word here. While weâre enjoying the implied exclusivity of the current conditions, we fully expect Twitter to grow its VAR tier to ensure a more competitive marketplace.
From my perspective, Twitter enabling VARs allows them to focus on what is near and dear to their hearts â developer use cases, promoted Tweets, end users, and the display ecosystem â while enabling firms focused on the data-delivery business to distribute underlying data for non-display use. Gnip provides stream enrichments for all of the data that flows through our software. Those enrichments include format and protocol normalization, as well as stream augmentation features such as global URL unwinding. Those value-adds make social media API integration and data leverage much easier than doing a bunch of one-off integrations yourself.
Weâre certainly working on other partnerships of this level of significance, but we have nothing to announce at this time.
What do you wish more people understood about data markets and/or the way large datasets can be used?
Jud Valeski: First, data is not free, and thereâs always someone out there that wants to buy it. As an end-user, educate yourself with how the content you create using someone elseâs service could ultimately be used by the service-provider.
Second, black markets are a real problem, and just because âeveryone else is doing itâ doesnât mean itâs okay. As an example, botnet-like distributed IP address polling infrastructure is commonly used to extract more data from a publisherâs service than their API usage terms allow. While perhaps fun to build and run (sometimes), these approaches clearly result in aggregated pools of publisher data that the publisher never intended to promote. Once collected, the aggregated pools of data are sold to data-hungry analytics firms. This results in end-user frustration, in that the content they produced was used in a manner that flagrantly violated the terms under which they signed up. These databases are frequently called out as infringing on privacy.
Everyone loves a good Robin Hood story, and thatâs how Iâd characterize the overall state of data collection today.
How has real-time data changed the field of customer relationship management (CRM)?
Jud Valeski: CRM firms have a new level of awareness. They no longer rely exclusively on dated user studies. A customer service rep may know about your social life through their dashboard the moment you are connected to them over the phone.
I ultimately see the power of understanding collective consciousness in responding to customer service issues. We havenât even scratched the surface here. Imagine if Company X reached out to you directly every time you had a problem with their product or service. Proactivity can pay huge dividends. Companies havenât tapped even 10% of the potential here, and part of that is because theyâre not spending enough money in the area yet.
Today, âsocialâ is a checkbox that CRM tools attempt to check off just to keep the boss happy. Tomorrow, social data and metaphors will define the tools outright.
Have you learned anything as a social media user yourself from working on Gnip? Is there anything social media users should be more aware of?
Jud Valeski: Read the terms of service for social media services youâre using before you complain about privacy policies or how and where your data is being used. Unless you are on a private network, your data is treated as public for all to use, see, sell, or buy. Donât kid yourself. Of course, this brings us all the way back around to black markets. Black markets â and publishersâ generally lackadaisical response to them â cloud these waters.
If you canât make it to Strata, you can learn more about the architectural challenges of distributing social and location data across the web in real time, and how Gnip has evolved to address those challenges, in Judâs contribution to âBeautiful Data.â
Datasets as albums? Entities as singles? How an iTunes for data might work.
As we move toward a data economy, can we take the digital content model and apply it to data acquisition and sales? Thatâs a suggestion that Gil Elbaz (@gilelbaz), CEO and co-founder of the data platform Factual made in passing at his recent talk at Web 2.0 Expo.
Elbaz spoke about some of the hurdles that startups face with big data â not just the question of storage, but the question of access. But as he addressed the emerging data economy, Elbaz said we will likely see novel access methods and new marketplaces for data. Startups will be able to build value-added services on top of big data, rather than having to worry about gathering and storing the data themselves. âAn iTunes for data,â is how he described it.
So what would it mean to apply the iTunes model to data sales and distribution? I asked Elbaz to expand on his thoughts.
What problems does an iTunes model for data solve?
Gil Elbaz: One key framework that will catalyze data sharing, licensing and consumption will be an open data marketplace. It is a place where data can be programmatically searched, licensed, accessed, and integrated directly into a consumer application. One might call it the âeBay of dataâ or the âiTunes of data.â iTunes might be the better metaphor because itâs not just the content that is valuable, but also the convenience of the distribution channel and the ability to pay for only what you will consume.
How would an iTunes model for data address licensing and ownership?
Gil Elbaz: In the case of iTunes, in a single click I purchase a track, download it, establish licensing rights on my iPhone and up to four other authorized devices, and itâs immediately integrated into my daily life. Similarly, the deepest value will come for a marketplace that, with a single click, allows a developer to license data and have it automatically integrated into their particular application development stack. That might mean having the data instantly accessible via API, automatically replicated to a MySQL server on EC2, synchronized at Database.com, or copied to Google App Engine.
An iTunes for data could be priced from a single record/entity to a complete dataset. And it could be licensed for single use, caching allowed for 24 hours, or perpetual rights for a specific application.
What needs to happen for us to move away from âbuying the whole albumâ to buying the data equivalent of a single?
Gil Elbaz: The marketplace will eventually facilitate competitive bidding, which will bring the price down for developers. iTunes is based on a fairly simple set-pricing model. But, in a world of multiple data vendors with commodity data, only truly unique data will command a premium price. And, of course, weâll need great search technology to find the right data or data API based on the developerâs codified requirements: specified data schema, data quality bar, licensing needs, and the bid price.
Another dimension that is relevant to Factualâs current model: data as a currency. Some of our most interesting partnerships are based on an open exchange of information. Partners access our data and also contribute back streams of edits and other bulk data into our ecosystem. We highly value the contributions our partners make. âCurrencyâ is a medium of exchange and a basis for accessing other scarce resources. In a world where not everyone is yet actively looking to license data, unique data is increasingly an important medium of exchange.
This interview was edited and condensed.
The trade in data is only in its infancy
by Edd Dumbill
If I talk about data marketplaces, you probably think of large resellers like Bloomberg or Thomson Reuters. Or startups like InfoChimps. What you probably donât think of is that we as consumers trade in data.
Since the advent of computers in enterprises, our interaction with business has caused us to leave a data imprint. In return for this data, we might get lower prices or some other service. The web has only accelerated this, primarily through advertising, and big data technologies are adding further fuel to this change.
When I use Facebook Iâm trading my data for their service. Iâve entered into this commerce perhaps unwittingly, but using the same mechanism humankind has known throughout our history: trading something of mine for something of theirs.
So letâs guard our privacy by all means, but recognize this is a bargain and a marketplace we enter into. Consumers will grow more sophisticated about the nature of this trade, and adopt tools to manage the data they give up.
Is this all one-way traffic? Business is certainly ahead of the consumer in the data management game, but thereâs a race for control on both sides. To continue the currency analogy, browsers have had âwalletsâ for a while, so we can keep our data in one place.
The maturity of the data currency will be signalled by personal data bank accounts, that give us the consumer control and traceability. The Locker project is a first step towards this goal, giving users a way to get their data back from disparate sites, but is one of many future models.
Who runs data banks themselves will be another point of control in the struggle for data ownership.
Big data as a discipline or a conference topic is still in its formative years.
by Tyler Bell
The crowd at the Strata Conference could be divided into two broad contingents:
Those attending to learn more about data, having recently discovered its potential.
Long-time data enthusiasts watching with mixed emotions as their interest is legitimized, experiencing a feeling not unlike when a band that youâve been following for years suddenly becomes popular.

A data-oriented event like this, outside a specific vertical, could not have drawn a large crowd with this level of interest, even two years ago. Until recently, data was mainly an artifact of business processes. It now takes center stage; organizationally, data has left the IT department and become the responsibility of the product team.
Of course âdata,â in its abstract sense, has not changed. But our ability to obtain, manipulate, and comprehend data certainly has. Today, data merits top billing due to a number of confluent factors, not least its increased accessibility via on-demand platforms and tools. Server logs are the new cash-for-gold: act now to realize the neglected riches within your upper drive bay.
But the idea of âbig dataâ as a discipline, as a conference subject, or as a business, remains in its formative years and has yet to be satisfactorily defined. This immaturity is perhaps best illustrated by the array of language employed to define big dataâs merits and its associated challenges. Commentators are employing very distinct wording to make the ill-defined idea of âbig dataâ more familiar; their metaphors fall cleanly into three categories:
Natural resources (âthe new oil,â âgoldrushâ and of course âdata miningâ): Highlights the singular value inherent in data, tempered by the effort required to realize its potential.
Natural disasters (âdata tornado,â âdata deluge,â data tidal waveâ): Frames data as a problem of near-biblical scale, with subtle undertones of assured disaster if proper and timely preparations are not considered.
Industrial devices (âdata exhaust,â âfirehose,â âIndustrial Revolutionâ): A convenient grab-bag of terminologies that usually portrays data as a mechanism created and controlled by us, but one that will prove harmful if used incorrectly.
If Strataâs Birds-of-a-Feather conference sessions are anything to go by, the idea of âbig dataâ requires the definition and scope these metaphors attempt to provide. Over lunch you could have met with like-minded delegates to discuss big data analysis, cloud computing, Wikipedia, peer-to-peer collaboration, real-time location sharing, visualization, data philanthropy, Hadoop (natchâ), data mining competitions, dev ops, data tools (but ânot trivial visualizationsâ), Cassandra, NLP, GPU computing, or health care data. There are two takeaways here: the first is that we are still figuring out what big data is and how to think about it; the second is that any alternative is probably an improvement on âbig data.â
Strata is about âmaking data workâ â the tenor of the conference was less of a âhow-toâ guide, and more about defining the problem and shaping the discussion. Big data is a massive opportunity; we are searching for its identity and the language to define it.
Opera Solutionsâ Arnab Gupta says human plus machine always trumps human vs machine.
by Julie Steele
Arnab Gupta is the CEO of Opera Solutions, an international company offering big data analytics services. I had the chance to chat with him recently about the massive task of managing big data and how humans and machines intersect. Our interview follows.
Tell me a bit about your approach to big data analytics.
Arnab Gupta: Our company is a science-oriented company, and the core belief is that behavior â human or otherwise â can be mathematically expressed. Yes, people make irrational value judgments, but they are driven by common motivation factors, and the math expresses that.
I look at the so-called âbig data phenomenonâ as the instantiation of human experience. Previously, we could not quantitatively measure human experience, because the data wasnât being captured. But Twitter recently announced that they now serve 350 billion tweets a day. What we say and what we do has a physical manifestation now. Once there is a physical manifestation of a phenomenon, then it can be mathematically expressed. And if you can express it, then you can shape business ideas around it, whether thatâs in government or health care or business.
How do you handle rapidly increasing amounts of data?
Arnab Gupta: Itâs an impossible battle when you think about it. The amount of data is going to grow exponentially every day, ever week, every year, so capturing it all canât be done. In the economic ecosystem there is extraordinary waste. Companies spend vast amounts of money, and the ratio of investment to insight is growing, with much more investment for similar levels of insight. This method just mathematically cannot work.
So, we donât look for data, we look for signal. What weâve said is that the shortcut is a priori identifying the signals to know where the fish are swimming, instead of trying to dam the water to find out which fish are in it. We focus on the flow, not a static data capture.
What role does visualization play in the search for signal?
Arnab Gupta: Visualization is essential. People dumb it down sometimes by calling it âUIâ and âdashboards,â and they donât apply science to the question of how people perceive. We need understanding that feeds into the left brain through the right brain via visual metaphor. At Opera Solutions, we are increasingly trying to figure out the ways in which the mind understands and transforms the visualization of algorithms and data into insights.
If understanding is a priority, then which do you prefer: a black-box model with better predictability, or a transparent model that may be less accurate?
Arnab Gupta: People bifurcate, and think in terms of black-box machines vs. the human mind. But the question is whether you can use machine learning to feed human insight. The power lies in expressing the black box and making it transparent. You do this by stress testing it. For example, if you were looking at a model for mortgage defaults, you would say, âWhat happens if home prices went down by X percent, or interest rates go up by X percent?â You make your own heuristics, so that when you make a bet you understand exactly how the machine is informing your bet.
Humans can do analysis very well, but the machine does it consistently well; it doesnât make mistakes. What the machine lacks is the ability to consider orthogonal factors, and the creativity to consider what could be. The human mind fills in those gaps and enhances the power of the machineâs solution.
So you advocate a partnership between the model and the data scientist?
Arnab Gupta: We often create false dichotomies for ourselves, but the truth is itâs never been man vs. machine; it has always been man plus machine. Increasingly, I think itâs an article of faith that the machine beats the human in most large-scale problems, even chess. But though the predictive power of machines may be better on a large-scale basis, if the human mind is trained to use it powerfully, the possibilities are limitless. In the recent Jeopardy showdown with IBMâs Watson, I would have had a three-way competition with Watson, a Jeopardy champion, and a combination of the two. Then you would have seen where the future lies.
Does this mean we need to change our approach to education, and train people to use machines differently?
Arnab Gupta: Absolutely. If you look back in time between now and the 1850s, everything in the world has changed except the classroom. But I think we are dealing with a phase-shift occurring. Like most things, the inertia of power is very hard to shift. Change can take a long time and there will be a lot of debris in the process.
One major hurdle is that the language of machine-plus-human interaction has not yet begun to be developed. Itâs partly a silent language, with data visualization as a significant key. The trouble is that language is so powerful that the left brain easily starts dominating, but really almost all of our critical inputs come from non-verbal signals. We have no way of creating a new form of language to describe these things yet. We are at the beginning of trying to develop this.
Another open question is: Whatâs the skill set and the capabilities necessary for this? At Opera we have focused on the ability to teach machines how to learn. We have 150-160 people working in that area, which is probably the largest private concentration in that area outside IBM and Google. One of the reasons we are hiring all these scientists is to try to innovate at the level of core competencies and the science of comprehension.
The business outcome of that is simply practical. At the end of the day, much of what we do is prosaic; it makes money or it doesnât make money. Itâs a business. But the philosophical fountain from which we drink needs to be a deep one.
Get Big Data Now: Current Perspectives from O'Reilly Radar now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

