Let us understand the agent's learning process based on the dynamic programming model in a deterministic environment depicted in the following diagram. Let us imagine an agent that is learning to play music on a simple keyboard:
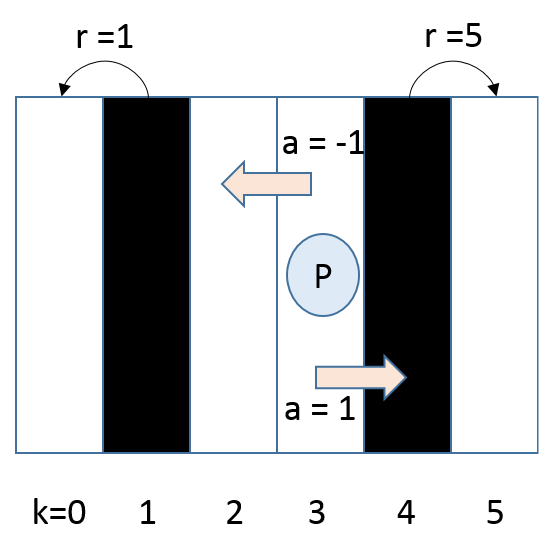
In this diagram, P represents the keyboard playing agent and K {0,1,2,3,4,5} represents the keys numbered from 0 to 5. In this simple setup, the agent can move forward and backward represented by A{-1,1}. Movement to the right side is denoted by a = 1 and left side by a = -1. Assume that the agent gets a reward for playing a specific note and in this case, ...

