The ReLu function is mathematically and graphically represented as follows:
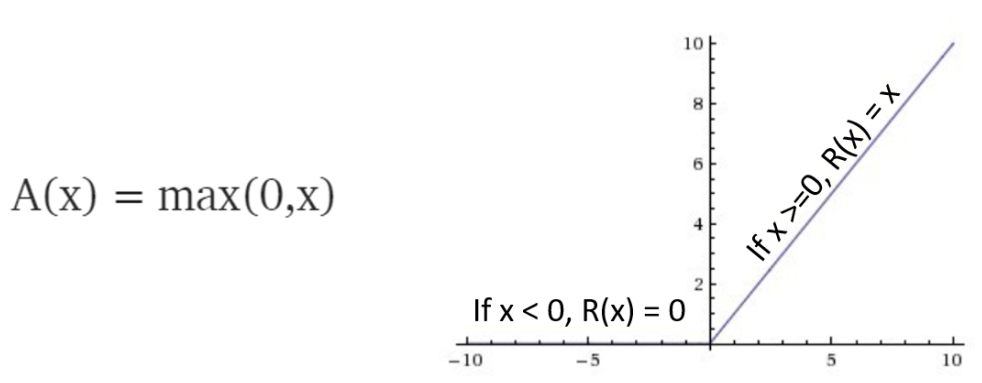
Figure 4.9 ReLu function
The mathematical form of this activation function is very simple compared to the sigmoid or tanh functions and it looks like a linear function. However, this is a nonlinear function that is computationally simple and efficient, hence it is deployed in deep neural networks (the neural networks with multiple hidden layers). This activation function eliminates the vanishing gradient problem. The limitation of using ReLu is that we can only use it for the hidden layers. The output layer needs to use different functions for regression and classification ...

