The RNN can be trained by unrolling the recurring unit in time into a series of feed-forward networks:
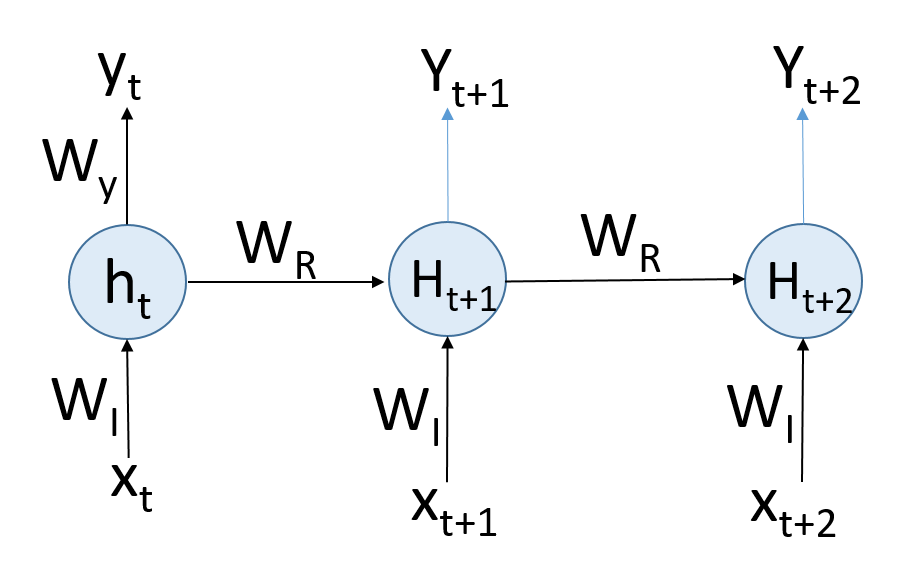
Figure 4.19: Unrolling the recurring unit into a series of feed-forward networks
The leftmost unit is the activity of the network in time, t, which is a typical feed-forward network with xt as input at time, t. This is multiplied by the weight matrix, WI. With the application of the activation function, we get the output, yt, at time, t. This output is fed as input to the next unit along with the contextual and time input for the next unit in time, t+1. If you notice, there is a fundamental difference in the feed-forward ...

