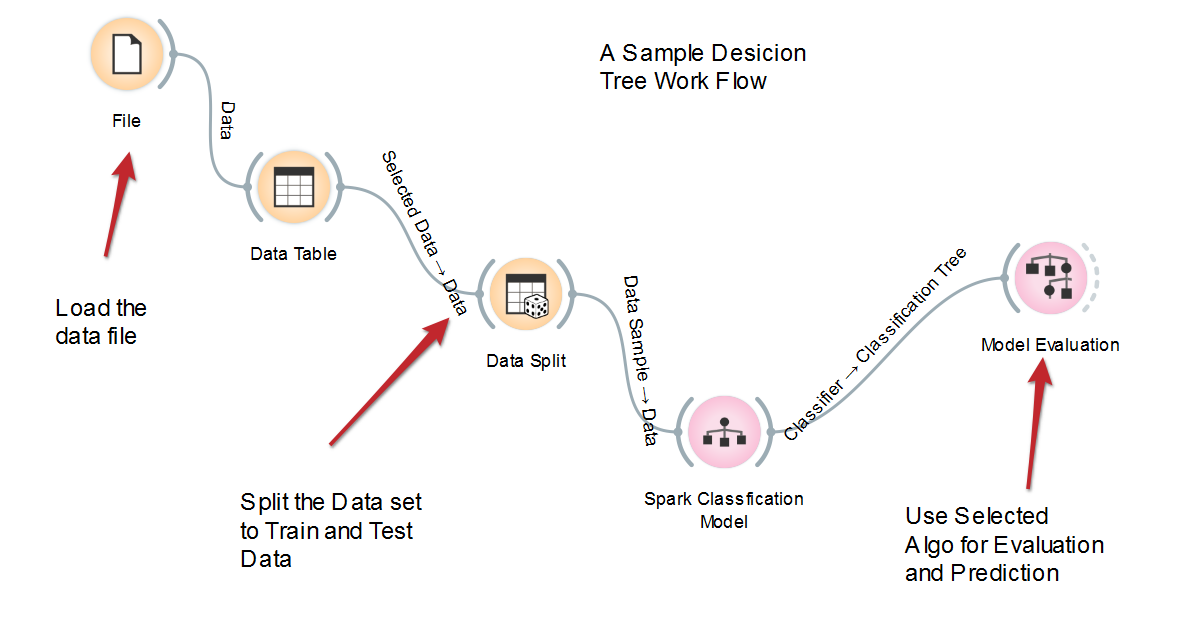
To visualize it better, we included a sample decision tree work flow in Spark which will read the data into Spark first. In our case, we create the RDD from the file. We then split the dataset into training data and test data using a random sampling function.
After the dataset is split, we use the training dataset to train the model, followed by test data to test the accuracy of the model. A good model should have a meaningful accuracy value (close to 1). The following figure depicts the workflow:
A sample tree was generated based on the Wisconsin Breast Cancer dataset. The red spot represents malignant cases, and the blue ...

