Archiving to HDFS
When people speak of Hadoop, they usually refer to storing lots of data for a long time, usually in HDFS, so more interesting data science or machine learning can be done later. Let's extend our use case by splitting the data flow at the collector to store an extra copy in HDFS for later use.
So, back in Amazon AWS, I start a fourth server to run Hadoop. If you plan on doing all your work in Hadoop, you'll probably want to write this data to S3, but for this example, let's stick with HDFS. Now our server diagram looks like this:
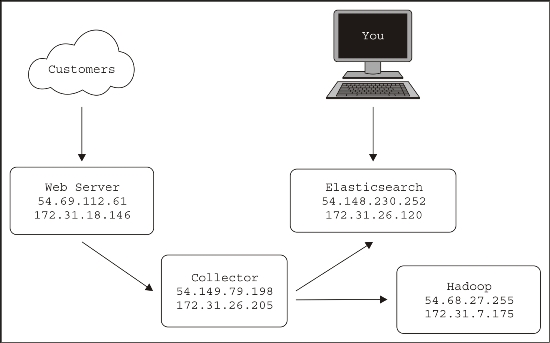
I used Cloudera's one-line installation instructions to speed up the setup. It's instructions can be found ...
Get Apache Flume: Distributed Log Collection for Hadoop - Second Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

