Chapter 1. Introduction
Anonymization, sometimes also called de-identification, is a critical piece of the healthcare puzzle: it permits the sharing of data for secondary purposes. The objective of this book is to walk you through practical methods to produce anonymized data sets in a variety of contexts. This isn’t, however, a book of equations—you can find those in the references we provide. We hope to have a conversation, of sorts, to help you understand some of the problems with anonymization and their solutions.
Because the techniques used to achieve anonymization can’t be separated from their context—the exact data you’re working with, the people you’re sharing it with, and the goals of analysis—this is partly a book of case studies. We include many examples to illustrate the anonymization methods we describe. Each case study was selected to highlight a specific technique, or to explain how to deal with a certain type of data set. They’re based on our experiences anonymizing hundreds of data sets, and they’re intended to provide you with a broad coverage of the area.
We make no attempt to review all methods that have been invented or proposed in the literature. We focus on methods that have been used extensively in practice, where we have evidence that they work well and have become accepted as reasonable things to do. We also focus on methods that we’ve used because, quite frankly, we know them well. And we try to have a bit of fun at the same time, with plays on words and funny names, just to lighten the mood (à la O’Reilly).
To Anonymize or Not to Anonymize
We take it for granted that the sharing of health data for the purposes of data analysis and research can have many benefits. The question is how to do so in a way that protects individual privacy, but still ensures that the data is of sufficient quality that the analytics are useful and meaningful. Here we mean proper anonymization that is defensible: anonymization that meets current standards and can therefore be presented to legal authorities as evidence that you have taken your responsibility toward patients seriously.
Anonymization is relevant when health data is used for secondary purposes. Secondary purposes are generally understood to be purposes that are not related to providing patient care. Therefore, things such as research, public health, certification or accreditation, and marketing would be considered secondary purposes.
Consent, or Anonymization?
Most privacy laws around the world are consent-based—if patients give their consent or authorization, the data can then be used for the purposes they authorize. If the data is anonymized, however, then no consent is required. In general, anonymized data is no longer considered personal health information and it falls outside of privacy laws. Note that we use the term “personal health information” to describe the broad universe of identifiable health information across the world, regardless of regulatory regime.
It might seem obvious to just get consent to begin with. But when patients go to a hospital or a clinic for medical care, asking them for a broad consent for all possible future secondary uses of their personal data when they register would generally be viewed as coercive, because it wouldn’t really be informed consent. These concerns could be mitigated by having a coordinator discuss this with each patient and answer their questions, allowing patients to take consent forms home and think about it, or informing the community through advertisements in the media. But this could be an expensive exercise to do properly, and would still raise ethical concerns if the permissions sought were very open-ended.
Furthermore, in some jurisdictions (like the EU) personal information must be “collected for specified, explicit and legitimate purposes and not further processed in a way incompatible with those purposes,” according to the Data Protection Directive 95/46/EC. This has been interpreted to mean that the purpose of the data processing must be specified somewhat precisely, and that further processing must not be incompatible with the purposes for which personal data were originally collected.[1] This raises a question about the legitimacy of broad consent.
When you consider large existing databases, if you want to get consent after the fact, you run into other practical problems. It could be the cost of contacting hundreds of thousands, or even millions, of individuals. Or trying to reach them years after their health care encounter, when many may have relocated, some may have died, and some may not want to be reminded about an unpleasant or traumatic experience. There’s also evidence that consenters and nonconsenters differ on important characteristics, resulting in potentially biased data sets.[2]
Consent isn’t always required to share personal information, of course. A law or regulation could mandate the sharing of personal health information with law enforcement under certain conditions without consent (e.g., the reporting of gunshot wounds) or the reporting of cases of certain infectious diseases without consent (e.g., tuberculosis or HIV).
Sometimes medical staff have fairly broad discretionary authority to share information with public health departments. But not all health care providers are willing to share their patients’ personal health information, and many decide not to when it’s up to them to decide.[3] So it shouldn’t be taken for granted that data custodians would be readily willing to share personal health information, even if they were permitted, and even if it were for the common good.
Anonymization allows for the sharing of health information when it’s not mandated or practical to obtain consent, and when the sharing is discretionary and the data custodian doesn’t want to share that data.
Penny Pinching
There’s actually quite a compelling financial case that can be made for anonymization. The costs from breach notification can be quite high, estimated at $200 per affected individual.[4] For large databases, this adds up to quite a lot of money. However, if the data was anonymized, no breach notification is needed. In this case, anonymization allows you to avoid the costs of a breach response. A recent return-on-investment analysis showed that the expected returns from the anonymization of health data are quite significant, considering just the cost avoidance of breach notification.[5]
Note
Many jurisdictions have data breach notification laws. This means that whenever there’s a data breach involving personal (health) information—such as a lost USB stick, a stolen laptop, or a database being hacked into—there’s a need to notify the affected individuals, the media, the attorneys general, or regulators. For example, in the U.S. there are extensive and expensive breach reporting requirements under the Health Insurance Portability and Accountability Act (HIPAA), and 47 states plus D.C. have additional requirements (a handful even require notice if only heatlh data was involved, with no mention of financially relevant information).
Some data custodians make their data recipients subcontractors (these are called Business Associates in the US under HIPAA, and Agents in Ontario under its health privacy law). As subcontractors, these data recipients are permitted to get personal health information under certain circumstances and subject to strict contractual requirements. The subcontractor agreements can make the subcontractor liable for all costs associated with a breach, effectively shifting some of the financial risk to the subcontractors. But even assuming that the subcontractor has a realistic financial capacity to take on such a risk, the data custodian may still suffer indirect costs due to reputational damage and lost business if there is a breach.
Poor anonymization or lack of anonymization can also be costly if individuals are re-identified or re-anonymized (i.e., the reversal of de-identification or anonymization). You may recall the story of AOL, when the company made the search queries of more than half a million of its users publicly available to facilitate research. Soon afterward, New York Times reporters were able to re-identify an individual from her search queries. A class action lawsuit was launched and recently settled, with five million dollars going to the class members and one million to the lawyers.[6] Therefore, it’s important to have effective and defensible anonymization techniques if data is going to be shared for secondary purposes.
Regulators are also starting to look at anonymization practices during their audits and investigations. In some jurisdictions, such as under HIPAA in the US, the regulator can impose penalties. Recent HIPAA audit findings have identified weaknesses in anonymization practices, so this is clearly one of the factors that they’ll be looking at.[7]
People Are Private
We know from surveys of the general public and of patients (adults and youth) that a large percentage of people admit to adopting privacy-protective behaviors because they’re concerned about how and for what reasons their health information might be used and disclosed. Privacy-protective behaviors include things like deliberately omitting information from personal or family medical history, self-treating or self-medicating instead of seeking care at a provider, lying to the doctor, paying cash to avoid having a claims record, seeing multiple providers so no individual provider has a complete record, and asking the doctor not to record certain pieces of information.
Youth are mostly concerned about information leaking to their parents, but some are also concerned about future employability. Adults are concerned about insurability and employability, as well as social stigma and the financial and psychological impact of decisions that can be made with their data.
Let’s consider a concrete example. Imagine a public health department that gets an Access to Information (or Freedom of Information) request from a newspaper for a database of anonymous test results for a sexually transmitted disease. The newspaper subsequently re-identifies the Mayor of Gotham in that database and writes a story about it. In the future, it’s likely that very few people will get tested for that disease, and possibly other sexually transmitted diseases, because they don’t trust that the information will stay private. From a public health perspective that’s a terrible outcome—the disease is now more likely to be transmitted among more people, and progress to a symptomatic or more severe stage before treatment begins.
The privacy-preserving behaviors we’ve mentioned are potentially detrimental to patients’ health because it makes it harder for the patients to receive the best possible care. It also corrupts the data, because such tactics are the way patients can exercise control over their personal health information. If many patients corrupt their data in subtle ways, then the resultant analytics may not be meaningful because information is missing or incorrect, or the cohorts are incomplete.
Maintaining the public’s and patients’ trust that their health information is being shared and anonymized responsibly is clearly important.
The Two Pillars of Anonymization
The terminology in this space isn’t always clear, and often the same terms are used to mean different, and sometimes conflicting, things.[8] Therefore it’s important at the outset to be clear about what we’re talking about.
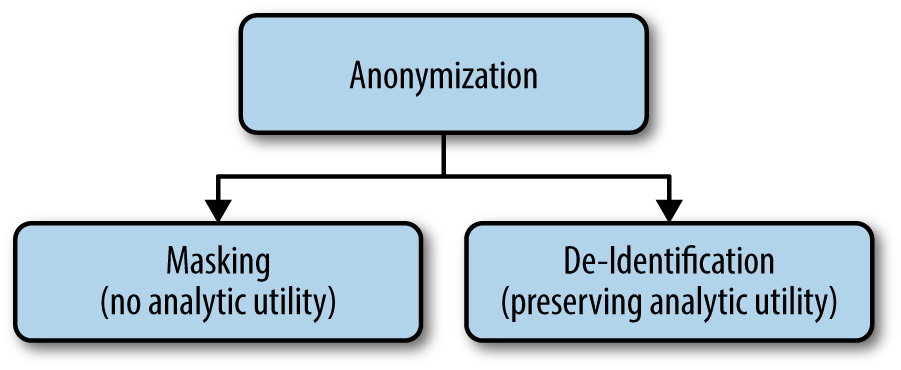
We’ll use anonymization as an overarching term to refer to everything that we do to protect the identities of individuals in a data set. ISO Technical Specification ISO/TS 25237 (Health informatics—Pseudonymization) provides a good generally accepted definition to use. We then define the two pillars—masking and de-identification—as you can see in Figure 1-1. These are the definitions we use to distinguish between two very different approaches to anonymization.
- Anonymization
- A process that removes the association between the identifying data and the data subject (ISO/TS 25237). This is achieved through masking and de-identification.
- Masking
- Reducing the risk of identifying a data subject to a very small level by applying a set of data transformation techniques without any concern for the analytic utility of the data.
- De-identification
- Reducing the risk of identifying a data subject to a very small level by applying a set of data transformation techniques such that the resulting data retains very high analytic utility.
Note
Masking and de-identification deal with different fields in a data set, so some fields will be masked and some fields will be de-identified. Masking involves protecting things like names and Social Security numbers (SSNs), which are called direct identifiers. De-identification involves protecting fields covering things like demographics and individuals’ socioeconomic information, like age, home and work ZIP codes, income, number of children, and race, which are called indirect identifiers.
Masking tends to distort the data significantly so that no analytics can be performed on it. This isn’t usually a problem because you normally don’t want to perform analytics on the fields that are masked anyway. De-identification involves minimally distorting the data so that meaningful analytics can still be performed on it, while still being able to make credible claims about protecting privacy. Therefore, de-identification involves maintaining a balance between data utility and privacy.
Masking Standards
The only standard that addresses an important element of data masking is ISO Technical Specification 25237. This focuses on the different ways that pseudonyms can be created (e.g., reversible versus irreversible). It doesn’t go over specific techniques to use, but we’ll illustrate some of these in this book (specifically in Chapter 11).
Another obvious data masking technique is suppression: removing a whole field. This is appropriate in some contexts. For example, if a health data set is being disclosed to a researcher who doesn’t need to contact the patients for follow-up questions, there’s no need for any names or SSNs. In that case, all of these fields will be removed from the data set. On the other hand, if a data set is being prepared to test a software application, we can’t just remove fields because the application needs to have data that matches its database schema. In that case, the names and SSNs are retained but are randomized.
Masking is often interpreted to mean randomization, which involves replacing actual values with random values selected from a large database.[4] You could use a database of first and last names, for example, to randomize those fields. You can also generate random SSNs to replace the original ones. While it may seem easy, if not done well, randomization can still leak personal information or can be easily reversed. For example, do not generate a single random number and then add the same number to all SSNs in the data set to “randomize” them.
De-Identification Standards
In general, three approaches to the de-identification of health data have emerged over the last few decades: lists, heuristics, and a risk-based methodology.
Lists
A good example of this approach is the Safe Harbor standard in the HIPAA Privacy Rule. Safe Harbor specifies 18 data elements that need to be removed or generalized (i.e., reducing the precision of the data elements). If you do that to data, that data is considered de-identified according to HIPAA. The Safe Harbor standard was intended to be a simple “cookie cutter” approach that can be applied by any kind of entity covered by HIPAA (a “Covered Entity,” or CE). Its application doesn’t require much sophistication or knowledge of de-identification methods. However, you need to be cautious about the “actual knowledge” requirement that is also part of Safe Harbor (see the discussion in the sidebar that follows).
The lists approach has been quite influential globally. We know that it has been incorporated into guidelines used by research, government, and commercial organizations in Canada. At the time of writing, the European Medicines Agency was considering such an approach as a minimal standard to de-identify clinical trials data so that it can be shared more broadly.[9]
Warning
This “list” approach to de-identification has been significantly criticized because it doesn’t provide real assurances that there’s a low risk of re-identification.[5] It’s quite easy to create a data set that meets the Safe Harbor requirements and still have a significantly high risk of re-identification.
Heuristics
The second approach uses “heuristics,” which are essentially rules of thumb that have developed over the years and are used by data custodians to de-identify their data before release. Sometimes these rules of thumb are copied from other organizations that are believed to have some expertise in de-identification. These tend to be more complicated than simple lists and have conditions and exceptions. We’ve seen all kinds of heuristics, such as never releasing dates of birth, but allowing the release of treatment or visit dates. But there are all kinds of exceptions for certain types of data, such as for rare diseases or certain rural communities with small populations.
While at an abstract level they may make sense, heuristics aren’t usually backed up by defensible evidence or metrics. This makes them unsuitable for data custodians that want to manage their re-identification risk in data releases. And the last thing you want is to find yourself justifying evidence-light rules of thumb to a regulator or judge.
Risk-based methodology
This third approach, which is consistent with contemporary standards from regulators and governments, is the approach we present in this book. It’s consistent with the “expert determination method” (also known as the “statistical method”) in the HIPAA Privacy Rule, as well as recent guidance documents and codes of practice:
- “Guidance Regarding Methods for De-Identification of Protected Health Information in Accordance with the Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule,” by the US Department of Health and Human Services
- “Anonymisation: Managing Data Protection Risk Code of Practice,” by the UK Information Commissioner’s Office
- “‘Best Practice’ Guidelines for Managing the Disclosure of De-Identified Health Information,” by the Canadian Institute for Health Information in collaboration with Canada Health Infoway
- “Statistical Policy Working Paper 22, Report on Statistical Disclosure Limitation Methodology,” by the US Federal Committee on Statistical Methodology
We’ve distilled the key items from these four standards into twelve characteristics that a de-identification methodology needs.[5] Arguably, then, if a methodology meets these twelve criteria, it should be consistent with contemporary standards and guidelines from regulators.
De-identification consists of changes to the data itself, and controls that can be put in place to manage risk. Conceptually, think of de-identification as consisting of dials that can be adjusted to ensure that the risk of re-identification is acceptable. In the next few chapters we’ll be discussing these dials in more depth.
Anonymization in the Wild
You’ve probably read this far because you’re interested in introducing anonymization within your organization, or helping your clients implement anonymization. If that’s the case, there are a number of factors that you need to consider about the deployment of anonymization methods.
Organizational Readiness
The successful deployment of anonymization within an organization—whether it’s one providing care, a research organization, or a commercial one—requires that organization to be ready. A key indicator of readiness is that the stakeholders believe that they actually need to anonymize their data. Stakeholders include privacy, compliance officer and legal staff in the organization, the individuals responsible for the line of business, and the IT department.
For example, if the organization is a hospital, the line of business may be the pharmacy department that is planning to share its data with researchers. If they don’t believe or are not convinced that the data they share needs to be anonymized, or if they’ve grown comfortable with less mature forms of anonymization, it will be difficult to implement proper anonymization within that organization.
Sometimes stakeholders in the line of business believe that if a data set does not include full names and SSNs, there’s no need to do anything else to anonymize it. But as we’ll see throughout this book, other pieces of information in a database can reveal the identities of patients even if their names and SSNs are removed, and certainly that’s how privacy laws and regulations view the question. Remember that the majority of publicly known successful re-identification attacks were performed on data sets that just had the names, addresses, and SSNs removed.[13]
Also, sometimes these stakeholders are not convinced that they’re sharing data for secondary purposes. If data is being shared for the purpose of providing care, patient consent is implied and there’s no need to anonymize the data (and actually, anonymizing data in the context of providing care would be a bad idea). Some stakeholders may argue that sharing health data for quality improvement, public health, and analytics around billing are not secondary purposes. Some researchers have also argued that research isn’t a secondary purpose. While there may be some merit to their arguments in general, this isn’t usually how standards, guidelines, laws, and regulations are written or interpreted.
The IT department is also an important stakeholder because its members will often be responsible for deploying any technology related to anonymization. Believing that anonymization only involves removing or randomizing names in a database (i.e., data masking), IT departments sometimes assign someone to write a few scripts over a couple of days to solve the data sharing problem. As you will see in the remainder of this book, it’s just not that simple. Doing anonymization properly is a legal or regulatory requirement, and not getting it right may have significant financial implications for the organization. The IT department needs to be aligned with that view.
Sometimes the organizations most ready for the deployment of proper anonymization are those that have had a recent data breach—although that isn’t a recommended method to reach a state of readiness!
Making It Practical
A number of things are required to make anonymization usable in practice. We’ve found the following points to be quite important, because while theoretical anonymization methods may be elegant, if they don’t meet the test of practicality their broad translation into the real world will be challenging:
- The most obvious criterion is that the anonymization methods must have been used in practice. Data custodians are always reassured by knowledge that someone else has tried the methods that they’re employing, and that they worked.
- Data users need to be comfortable with the data produced by the anonymization methods being applied. For example, if anonymization distorts the data in ways that are not clear, makes the data analysis more complicated, or limits the type of analysis that the data users can do, they’ll resist using anonymized data.
- The anonymization methods must also be understandable by data users. Especially in cases where care or business decisions are going to be made based on the data analysis, having a clear understanding of the anonymization is important. This also affects whether the data users accept the data.
- Anonymization methods that have been scrutinized by peers and regulators are more likely to be adopted. This means that transparency in the exact anonymization methods being used, their justifications, and assumptions made, helps with their adoption within organizations.[14]
- Needless to say, anonymization methods must be consistent with laws and regulations. Methods that would require changes in the law or paradigm shifts in how private information is perceived will not be adopted by data users because they’re simply too risky.
- Data custodians want to automate anonymization so that they don’t have to bring in external experts to manually anonymize every single data set they need to share. Analytics is becoming an important driver for business, patient care, and patient safety in many organizations, so using an inefficient process for getting the anonymized data quickly becomes a bottleneck.
Making It Automated
The techniques for anonymizing health data are quite sophisticated, and involve various forms of metrics and optimization algorithms. This means that some form of automation is needed to apply anonymization in practice. This is true of both small and large data sets.
Automation means that it’s possible for individuals who are not statisticians or data analysts to anonymize data sets. We still need the data scientists with expertise in anonymization to develop and improve the anonymization algorithms. But once designed, implemented, and automated, these methods should be accessible to a broader and less specialized audience. Let’s call them anonymization professionals.
Anonymization professionals need to have an understanding of the methods that are being automated, and they need to perform two things: (a) data preparation, and (b) risk assessment. Both of these are described in the remainig chapters. The basic setup is shown in Figure 1-2.
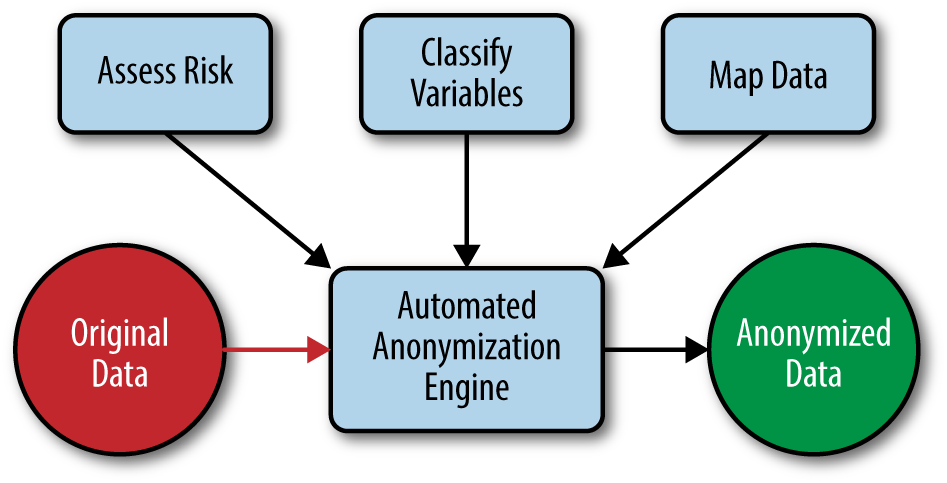
The risk assessment step comes down mostly to the completion of a series of checklists that will determine the context of the data release and the context of the re-identification risk. The anonymization professional needs to know the data, the data recipient, and the data custodian well in order to complete the checklist.
The variable classification step includes deciding which variables in the data will be disclosed, and allows an automated system to decide how best to anonymize each variable in the data set. The way each variable is anonymized can be calibrated to the type of variable (e.g., the way a date is anonymized is different from the way a ZIP code is anonymized).
Finally, the data mapping is a technical task that describes how the real data set is organized and the relationships among the tables (assuming a relational data model). For example, a data set may have a table describing the patient demographics and another table describing all of the patient visits. These two tables are linked by a patient ID. All of these details are characterized during the data mapping exercise.
Once these tasks are completed, which an anonymization professional is expected to be able to do, the actual anonymization of a data set can be automated using the techniques described in this book. Simplifying and automating the process in this way reduces the level of technical knowledge needed to anonymize data sets, therefore eliminating the shortage of anonymization professionals. This shortage has been a real obstacle to many data-based research and commercial opportunities.
Use Cases
Practical anonymization has been applied in a number of different situations. The techniques to use will of course depend on the specifics of the situation. Here we summarize some of the use cases:
- Research
- This use case is the simplest one, in that the data set can oten be completely defined up front and may not be refreshed or updated. An analyst working for the data custodian decides how to anonymize the data and then creates a file to give to the researcher.
- Open data
- There’s increasing pressure to make health data openly available on the Web. This may be data from projects funded through the public purse, clinical trials data, or other kinds of government data (so-called “open government” initiatives).
- Data warehouses
- Organizations are increasingly creating data warehouses that integrate data sets from multiple sources for the purpose of performing analytics. These sources can be internal to the organization (e.g., different units within the hospital), or external (e.g., data sets from commercial data brokers). Data needs to be anonymized before being pulled out of the data warehouses to perform analytics.
- Public health surveillance
- In this use case, health-related data is being continuously collected—from multiple geographically distributed locations—and sent to a centralized database. The sites need to anonymize their data before sending it to the central repository, and the anonymization should be applied consistently across all sites so that the data is meaningful when it is combined. Once the data is collected centrally, it’s analyzed and interpreted for things like disease surveillance, evaluating compliance to screening guidelines, and service planning.
- Medical devices
- Similar to public health surveillance, data from medical devices is collected from multiple sources. The devices themselves can be installed at the sites of health care providers across the country and can pull in data about the patients from electronic medical records. This data could include patient-specific information. Data here is flowing regularly and in many cases needs to be anonymized as it’s coming in.
- Alerts
- This use case is a bit different from the others because an alert needs to be sent close in time to when it was generated. Also, an alert may consist of a very small number of patient records. For example, an alert can be generated for a pharma company when a certain drug is dispensed to a patient. But the information in the alert needs to be de-identified before it can be transmitted. In this case individual (or a small number of) records need to be anonymized on the fly, rather than a full database.
- Software testing
- This use case often requires access to data to conduct functional and performance tests. Organizations developing applications that process health data need to get that data from production environments. The data from production environments must be anonymized before being sent to the testing group.
We’ll discuss many of these use cases in the book and show how they can be handled.
Stigmatizing Analytics
When health data is anonymized so that it can be used for the sake of analytics, the outcome of the analysis is a model or an algorithm. This model can be as simple as a tabular summary of the data, a relationship such as “all people with x have y”, a multi-variate regression model, or a set of association rules that characterize the relationships in the data. We make a distinction between the process of building this model (“modeling”) and making decisions using the model (“decision making”).
Anonymized data can be used for modeling. Anonymization addresses the risk of assigning an identity to a record in the database. This promise affects how “personal information” is defined in privacy laws. If the risk of assigning identity is very small, the data will no longer be considered personal information.
Decision making may, however, raise additional privacy concerns. For example, a model could suggest that people living close to an industrial site have a higher incidence of cancer than average making them less employable and reducing their propoerty value. Or a model could be used to send targeted ads to an individual that reveal that that person is gay, pregnant, has had an abortion, or has a mental illness.
In all of these cases, financial, social, and psychological harm may result to the affected individuals. Individuals may be discriminated against due to the decisions made. And in all of these cases the models themselves may have been constructed using anonymized data. The individuals affected by the decisions may not even be in the data sets that were used in building the models. Therefore, opt-out or withdrawal of an individual from a data set wouldn’t necessarily have an impact on whether a decision is made about the individual.
Note
The above are examples of what we call “stigmatizing analytics.” These are the types of analytics that produce models that can lead to decisions that adversely affect individuals and groups. Data custodians that anonymize and share health data need to consider the impact of stigmatizing analytics, even though, strictly speaking, it goes beyond anonymization.
The model builders and the decision makers may belong to different organizations. For example, a researcher may build a model from anonymized data and then publish it. Later on, someone else may use the model to make decisions about individual patients.
Data recipients that build models using anonymized health data therefore have another obligation to manage the risks from stigmatizing analytics. In a research context, research ethics boards often play that role, evaluating whether a research study may potentially cause group harm (e.g., to minority groups or groups living in certain geographies) or whether the publication of certain results may stigmatize communities. In such cases they’re assessing the conclusions that can be drawn from the resultant models and what kinds of decisions can be made. However, outside the research world, a similar structure needs to be put in place. This governance structure would examine the models and the planned or potential decisions that can be made from the models.
Managing the risks from stigmatizing analytics is an ethical imperative. It can also have a direct impact on patient trust, regulator scrutiny of an organization, and the organization’s reputation. Because there is an element of ethics and business impact, social and cultural norms do matter. Some of the factors to consider in this decision-makign include:[15]
- The relationship between the purposes for which the data have been collected and the purposes for further processing.
- The context in which the data have been collected and the reasonable expectations of the data subjects as to their further use.
- The nature of the data and the impact of the further processing on the data subjects.
- The safeguards applied by the controller to ensure fair processing and to prevent any undue impact on the data subjects.
A specific individual or group within the organization should be tasked with reviewing analysis and decision-making protocols to decide whether any fall into the “stigmatizing” category. These individuals should have the requisite backgrounds in ethics, privacy, and business to make the necessary trade-offs and (admittedly), subjective risk assessments.
The fallout from inappropriate models and decisions by data users may go back to the provider of the data. In addition to anonymizing the data they release, data custodians may consider not releasing certain variables to certain data users if there’s an increased potential of stigmatizing analytics. They would also be advised to ensure that their data recipients have appropriate mechanisms to manage the risks from stigmatizing analytics.
Anonymization in Other Domains
Although our focus in this book is on health data, many of the methods we describe are applicable to financial, retail, and advertising data. If an online platform needs to report to its advertisers on how many consumers clicked on an ad and segment these individuals by age, location, race, and income, that combination of information may identify some of these individuals with a high probability. The anonymization methods that we discuss here in the context of health data sets can be applied equally well to protect that kind of advertising data.
Basically, the main data fields that make individuals identifiable are similar across these industries: for example, demographic and socioeconomic information. Dates, a very common kind of data in different types of transactions, can also be an identity risk if the transaction is a financial or a retail one. Location is also very important, regardless of domain, both residential and the places they have visited over time. And billing codes might reveal a great deal more than you would expect.
Because of escalating concerns about the sharing of personal information in general, the methods that have been developed to de-identify health data are increasingly being applied in other domains. Additionally, regulators are increasingly expecting the more rigorous methods applied in health care to be more broadly followed in other domains.
About This Book
Like an onion, this book has layers. Chapter 2 introduces our overall methodology to de-identification (spoiler alert: it’s risk-based), including the threats we consider. It’s a big chapter, but an important one to read in order to understand the basics of de-identification. Skip it at your own risk!
After that we jump into case studies that highlight the methods we want to demonstrate—from cross-sectional to longitudinal data to more methods to deal with different problems depending on the complexity of the data. The case studies are two-pronged: they are based on both a method and a type of data. The methods start with the basics, with Chapter 3, then Chapter 4. But longitudinal data can be complicated, given the number of records per patient or the size of the data sets involved. So we keep refining methods in Chapter 5 and Chapter 6. For both cross-sectional and longitudinal data sets, when you want to lighten the load, you may wish to consider the methods of Chapter 7.
For something completely different, and to deal with the inevitable free-form text fields we find in many data sets, we look at text anonymization in Chapter 8. Here we can again measure risk to de-identify, although the methods are very different from what’s presented in the previous chapters of the book.
Something else we find in many data sets is the locations of patients and their providers. To anonymize this data, we turn to the geospatial methods in Chapter 9. And we would be remiss if we didn’t also include Chapter 10, not only because medical codes are frequently present in health data, but because we get to highlight the Cajun Code Fest (seriously, what a great name).
We mentioned that there are two pillars to anonymization, so inevitably we needed Chapter 11 to discuss masking. We also describe ways to bring data sets together before anonymization with secure linking in Chapter 12. This opens up many new opportunities for building more comprehensive and detailed data sets that otherwise wouldn’t be possible. And last but not least, we discuss something on everyone’s mind—data quality—in Chapter 13. Obviously there are trade-offs to be made when we strive to protect patient privacy, and a lot depends on the risk thresholds in place. We strive to produce the best quality data we can while managing the risk of re-identification, and ultimately the purpose of this book is to help you balance those competing interests.
[1] Article 29 Working Party, “Opinion 03/2014 on Purpose Limitation,” WP203, Apr. 2013.
[2] K. El Emam, E. Jonker, E. Moher, and L. Arbuckle, “A Review of Evidence on Consent Bias in Research,” American Journal of Bioethics 13:4 (2013): 42–44.
[3] K. El Emam, J. Mercer, K. Moreau, I. Grava-Gubins, D. Buckeridge, and E. Jonker. “Physician Privacy Concerns When Disclosing Patient Data for Public Health Purposes During a Pandemic Influenza Outbreak,” BMC Public Health 11:1 (2011): 454.
[4] K. El Emam, A Guide to the De-identification of Personal Health Information, (Boca Raton, FL: CRC Press/Auerbach, 2013).
[5] Risky Business: Sharing Health Data While Protecting Privacy, ed. K. El Emam (Bloomington, IN: Trafford Publishing, 2013).
[6] Landweher vs AOL Inc. Case No. 1:11-cv-01014-CMH-TRJ in the District Court in the Eastern District of Virginia.
[7] L. Sanches, “2012 HIPAA Privacy and Security Audits,” Office for Civil Rights, Department of Health and Human Services.
[8] B. M. Knoppers and M. Saginur “The Babel of Genetic Data Terminology,” Nat. Biotechnol., vol. 23, no. 8, pp. 925–927, Aug. 2005.
[9] European Medicines Agency, “Publication and access to clinical-trial data,” Policy 70, Jun. 2013.
[10] K. El Emam, E. Jonker, L. Arbuckle, and B. Malin, “A Systematic Review of Re-Identification Attacks on Health Data,” PLoS ONE 6:12 (2011): e28071.
[11] N. Homer, S. Szelinger, M. Redman, D. Duggan, W. Tembe, J. Muehling, J.V. Pearson, D.A. Stephan, S.F. Nelson, and D.W. Craig, “Resolving Individuals Contributing Trace Amounts of DNA to Highly Complex Mixtures Using High-Density SNP Genotyping Microarrays,” PLoS Genetics 4:8 (2008): e1000167.
[12] M. Gymrek, A.L. McGuire, D. Golan, E. Halperin, and Y. Erlich, “Identifying Personal Genomes by Surname Inference,” Science 339:6117 (2013): 321–324.
[13] K. El Emam, E. Jonker, L. Arbuckle, and B. Malin, “A Systematic Review of Re-Identification Attacks on Health Data,” PLoS ONE, vol. 6, no. 12, p. e28071, Dec. 2011.
[14] In some jurisdictions, this is effectively a requirement. For example, the HIPAA expert determination standard for de-identification requires that the techniques used are based on “generally accepted statistical and scientific principles and methods for rendering information not individually identifiable”.
[15] Article 29 Working Party, “Opinion 03/2014 on Purpose Limitation,” WP203, Apr. 2013.
[16] L. Sweeney, A. Abu, and J. Winn, “Identifying Participants in the Personal Genome Project by Name,” (Cambridge, MA: Harvard University, 2013).
[17] W. Lowrance and F. Collins, “Identifiability in Genomic Research,” Science 317:5838 (2007): 600–602.
[18] B. Malin and L. Sweeney, “Determining the Identifiability of DNA Database Entries,” Proceedings of the American Medical Informatics Association Annual Symposium, (Bethesda, MD: AMIA, 2000), 537–541.
[19] M. Wjst, “Caught You: Threats to Confidentiality due to the Public Release of Large-scale Genetic Data Sets,” BMC Medical Ethics, 11:(2010): 21.
[20] M. Kayser and P. de Knijff, “Improving Human Forensics Through Advances in Genetics Genomics and Molecular Biology,” Nature Reviews Genetics 12:(2011): 179–192.
[21] Z. Lin, A. Owen, and R. Altman, “Genomic Research and Human Subject Privacy,” Science 305:(2004): 183.
Get Anonymizing Health Data now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

