Analysis in the Best, Average, and Worst Cases
One question to ask is whether the results of the previous section will be true for all input problem instances. Perhaps Sort-2 is only successful in sorting a small number of strings. There are many ways the input could change:
There could be 1,000,000 strings. How does an algorithm scale to large input?
The data could be partially sorted, meaning that almost all elements are not that far from where they should be in the final sorted list.
The input could contain duplicate values.
Regardless of the size n of the input set, the elements could be drawn from a much smaller set and contain a significant number of duplicate values.
Although Sort-4 from Figure 2-2 was the slowest of the four algorithms for sorting n random strings, it turns out to be the fastest when the data is already sorted. This advantage rapidly fades away, however, with just 16 random items out of position, as shown in Figure 2-3.
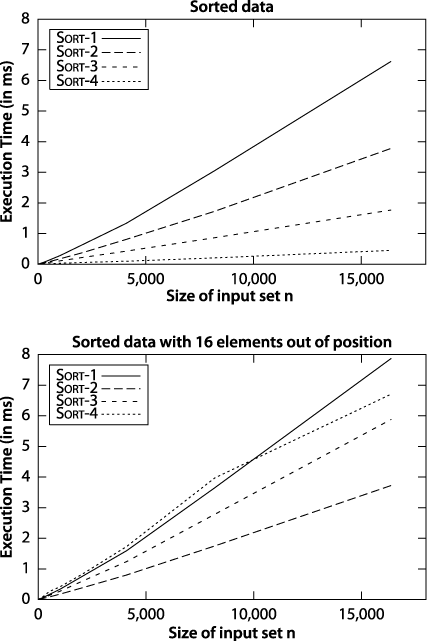
Figure 2-3. Comparing sort algorithms on sorted and nearly sorted data
However, suppose an input array with n strings is "nearly sorted"—that is, n/4 of the strings (25% of them) are swapped with another position just four locations away. It may come as a surprise to see in Figure 2-4 that Sort-4 outperforms the others.
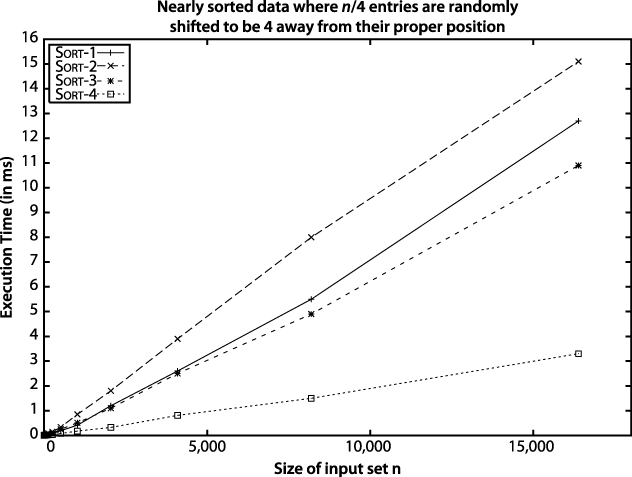
Figure 2-4. Sort-4 wins on nearly ...
Get Algorithms in a Nutshell now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

