The Q value
An important question is that if the RL problem is to find  , how does the agent learn by interacting with the environment? Equation
9.1.3 does not explicitly indicate the action to try and the succeeding state to compute the return. In RL, we find that it's easier to learn
, how does the agent learn by interacting with the environment? Equation
9.1.3 does not explicitly indicate the action to try and the succeeding state to compute the return. In RL, we find that it's easier to learn  by using the Q value:
by using the Q value:
![]() (Equation 9.2.1)
(Equation 9.2.1)
Where:
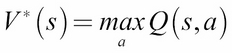 (Equation 9.2.2)
(Equation 9.2.2)
In other ...
Get Advanced Deep Learning with Keras now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

