In this chapter:
When describing how computers work to someone new to PCs, itâs often easiest to haul out the old notion that a program is a very large collection of instructions that are performed from beginning to end. Our notion of a program can include certain eccentricities, like loops and jumps, that make a program more resemble a game of Chutes and Ladders than a piano roll. If programming instructions were squares on a game board, we can see that our program has places where we stall, squares that we cross again and again, and spots we donât cross at all. But we have one way into our program, regardless of its spins and hops, and one way out.
Not too many years ago, single instructions were how we delivered work to computers. Since then, computers have become more and more powerful and grown more efficient at performing the work that makes running our programs possible. Todayâs computers can do many things at once (or very effectively make us believe so). When we package our work according to the traditional, serial notion of a program, weâre asking the computer to execute it close to the humble performance of a computer of yesterday. If all of our programs run like this, weâre very likely not using our computer to its fullest capabilities.
One of those capabilities is a computing systemâs ability to perform multitasking. Today, itâs frequently useful to look at our program (our very big task) as a collection of subtasks. For instance, if our program is a marine navigation system, we could launch separate tasks to perform each sounding and maintain other tasks that calculate relative depth, correlate coordinates with depth measurements, and display charts on a screen. If we can get the computer to execute some of these subtasks at the same time, with no change in our programâs results, our overall task will continue to get as much processing as it needs, but it will complete in a shorter period of time. On some systems, the execution of subtasks will be interleaved on a single processor; on others, they can run in parallel. Either way, weâll see a performance boost.
Up until now, when we divided our program into multiple tasks, we had only one way of delivering them to the processorâprocesses. Specifically, we started designing programs in which parent processes forked child processes to perform subtasks. In this model, each subtask must exist within its own process. Now, weâve been given an alternative thatâs even more efficient and provides even better performance for our overall programâthreads. In the threads model, multiple subtasks exist as individual streams of control within the same process.
The threads model takes a process and divides it into two parts:
One contains resources used across the whole program (the processwide information), such as program instructions and global data. This part is still referred to as the process.
The other contains information related to the execution state, such as a program counter and a stack. This part is referred to as a thread.
To compare and contrast multitasking between cooperating processes and multitasking using threads, letâs first look at how the simple C program in Example 1-1 can be represented as a process (Figure 1-1), a process with a single thread (Figure 1-2), and, finally, as a process with multiple threads (Figure 1-3).
Example 1-1. A Simple C Program (simple.c)
#include <stdio.h>
void do_one_thing(int *);
void do_another_thing(int *);
void do_wrap_up(int, int);
int r1 = 0, r2 = 0;
extern int
main(void)
{
do_one_thing(&r1);
do_another_thing(&r2);
do_wrap_up(r1, r2);
return 0;
}
void do_one_thing(int *pnum_times)
{
int i, j, x;
for (i = 0; i < 4; i++) {
printf("doing one thing\n");
for (j = 0; j < 10000; j++) x = x + i;
(*pnum_times)++;
}
}
void do_another_thing(int *pnum_times)
{
int i, j, x;
for (i = 0; i < 4; i++) {
printf("doing another \n");
for (j = 0; j < 10000; j++) x = x + i;
(*pnum_times)++;
}
}
void do_wrap_up(int one_times, int another_times)
{
int total;
total = one_times + another_times;
printf("wrap up: one thing %d, another %d, total %d\n",
one_times, another_times, total);
}Figure 1-1 shows the layout of this program in the virtual memory of a process, indicating how memory is assigned and which resources the process consumes. Several regions of memory exist:
A read-only area for program instructions (or âtextâ in UNIX parlance)
A read-write area for global data (such as the variables r1 and r2 in our program)
A heap area for memory that is dynamically allocated through malloc system calls
A stack on which the automatic variables of the current procedure are kept (along with function arguments and other information needed to link it to the procedure that called it), just below similar information for the procedure that called it, just below similar information for the procedure that called it, and so on and so on. Each of these procedure-specific areas is known as a stack frame, and one exists for each procedure in the program that remains active. In the stack area of this illustration you can see the stack frames of our procedures do_one_thing and main.
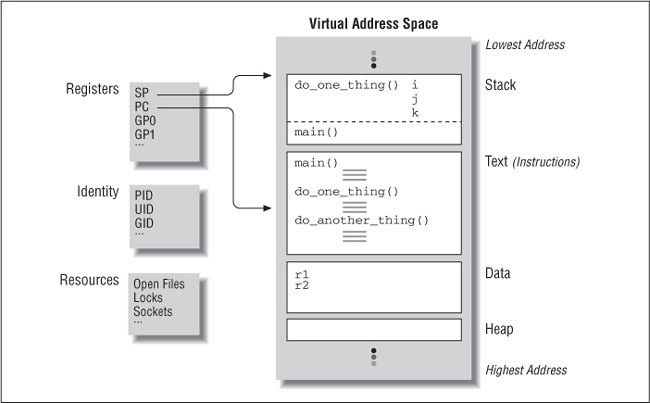
To complete our inventory of system resources needed to sustain this process, notice:
Machine registers, including a program counter (PC) to the currently executing instruction and a pointer (SP) to the current stack frame
Process-specific include tables, maintained by the operating system, to track system-supplied resources such as open files (each requiring a file descriptor), communication end points (sockets), locks, and signals
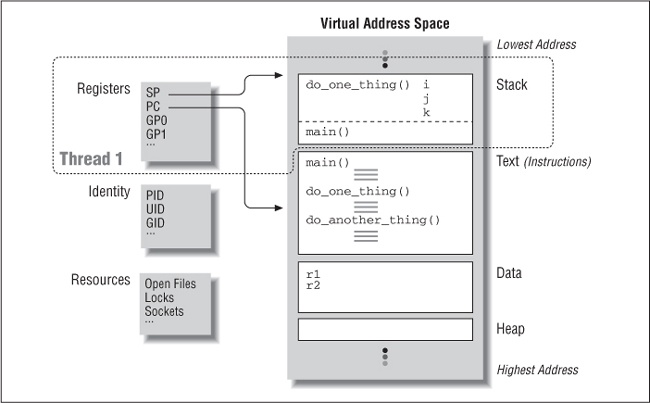
Figure 1-2 shows the same C program as a process with a single thread. Here, the machine registers (program counter, stack pointer, and the rest) have become part of the thread, leaving the rest as the process. As far as the outside observer of the program is concerned, nothing much has changed. As a process with a single thread, this program executes in exactly the same way as it does when modeled as a nonthreaded process. It is only when we design our program to take advantage of multiple threads in the same process that the thread model really takes off.
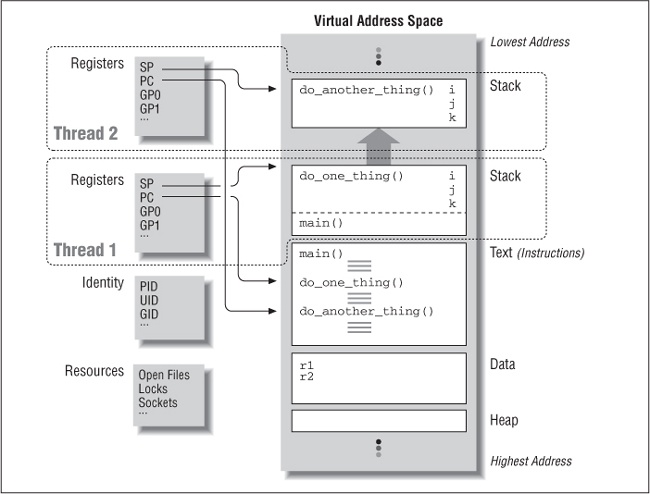
Figure 1-3 shows our program as it might execute if it were designed to operate in two threads in a single process. Here, each thread has its own copy of the machine registers. (Itâs certainly very handy for a thread to keep track of the instruction it is currently executing and where in the stack area it should be pushing and popping its procedure-context information.) This allows Thread 1 and Thread 2 to execute at different locations (or exactly the same location) in the programâs text. Thread 1, the thread in which the program was started, is executing do_one_thing, while Thread 2 is executing do_another_thing. Each thread can refer to global variables in the same data area. (do_one_thing uses r1 as a counter; do_another_thing uses r2.) Both threads can refer to the same file descriptors and other resources the system maintains for the process.
How do you design a program so that it executes in multiple threads within a process? Well, for starters, you need a thread creation routine and a way of letting the new thread know where in the program it should begin executing. But at this point, weâve passed beyond the ability to generalize.
Up to this point, weâve discussed the basics of threads and thread creation at a level common to all thread models. As we move on to discuss specifics (as we will in the remainder of this book), we encounter differences among the popular thread packages. For instance, Pthreads specifies a threadâs starting point as a procedure name; other thread packages differ in their specification of even this most elementary of concepts. Differences such as this motivated IEEE to create the Pthreads standard.
Pthreads is a standardized model for dividing a program into subtasks whose execution can be interleaved or run in parallel. The âPâ in Pthreads comes from POSIX (Portable Operating System Interface), the family of IEEE operating system interface standards in which Pthreads is defined (POSIX Section 1003.1c to be exact). There have been and still are a number of other threads modelsâMach Threads and NT Threads, for example. Programmers experience Pthreads as a defined set of C language programming types and calls with a set of implied semantics. Vendors usually supply Pthreads implementations in the form of a header file, which you include in your program, and a library, to which you link your program.
If we return to the simple program in our examples, we see that it has three tasks to complete. The three tasks are represented by the routines do_one_thing, do_another_thing, and do_wrap_up. The do_one_thing and do_another_thing tasks are simply loops that print out slightly different messages and then perform some token calculations to while away the time. The do_wrap_up task adds together the return values from the other two tasks and prints the result. Many real programs can be split, in a similar way, into individual tasks representing different CPU-based and I/O-based activities. For instance, a program that retrieves blocks of data from a file on disk and then performs computations based on their contents is an eminent candidate for multitasking.
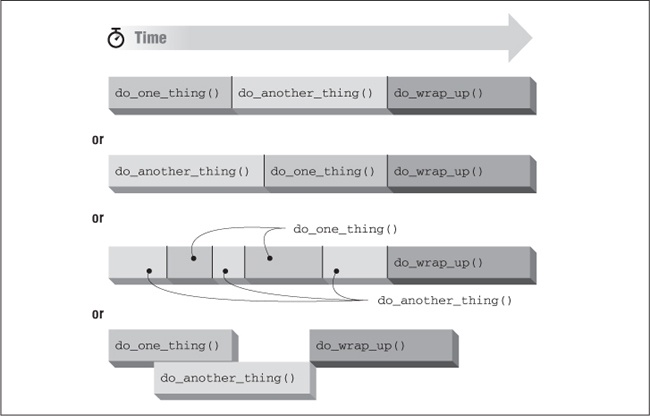
When we run the program, it executes each routine serially, always completely finishing the first before starting the second, and completely finishing the second before starting the third. If we take a closer look at the program, we see that the order in which the first two routines execute doesnât affect the third, as long as the third runs after both of them have completed. This property of a program â that statements can be executed in any order without changing the result â is called potential parallelism.
To illustrate parallelism, Figure 1-4 shows some possible sequences in which the programâs routines could be executed. The first sequence is that of the original program; the second is similar but with the first two routines exchanged. The third shows interleaved execution of the first routines; the last, their simultaneous execution. All sequences produce exactly the same result.
An obvious reason for exploiting potential parallelism is to make our program run faster on a multiprocessor. However, there are additional reasons for investigating a programâs potential parallelism:
- Overlapping I/O
If one or more tasks represent a long I/O operation that may block while waiting for an I/O system call to complete, there may be performance advantages in allowing CPU-intensive tasks to continue independently. For example, a word processor could service print requests in one thread and process a userâs editing commands in another.
- Asynchronous events
If one or more tasks is subject to the indeterminate occurrence of events of unknown duration and unknown frequency, such as network communications, it may be more efficient to allow other tasks to proceed while the task subject to asynchronous events is in some unknown state of completion. For example, a network-based server could process in-progress requests in one group of threads while another thread waits for the asynchronous arrival of new requests from clients through network connections.
- Real-time scheduling
If one task is more important than another, but both should make progress whenever possible, you may wish to run them with independent scheduling priorities and policies. For example, a stock information service application could use high priority threads to receive and update displays of online stock prices and low priority threads to display static data, manage background printing, and perform other less important chores.
Threads are a means to identify and utilize potential parallelism in a program. You can use them in your program design both to enhance its performance and to efficiently structure programs that do more than one thing at a time. For instance, handling signals, handling input from a communication interface, and managing I/O are all tasks that can be doneâand done very wellâby multiple threads executing simultaneously.
Now that we know the orderings that we desire or would allow in our program, how do we express potential parallelism at the programming level? Those programming environments that allow us to express potential parallelism are known as concurrent programming environments. A concurrent programming environment lets us designate tasks that can run in parallel. It also lets us specify how we would like to handle the communication and synchronization issues that result when concurrent tasks attempt to talk to each other and share data.
Because most concurrent programming tools and languages have been the result of academic research or have been tailored to a particular vendorâs products, they are often inflexible and hard to use. Pthreads, on the other hand, is designed to work across multiple vendorsâ platforms and is built on top of the familiar UNIX C programming interface. Pthreads gives you a simple and portable way of expressing multithreading in your programs.
Before looking at threads further, letâs examine the concurrent programming interface that UNIX already supports: allowing user programs to create multiple processes and providing services the processes can use to communicate with each other.
Example 1-2 recasts our earlier single-process program as a program in which multiple processes execute its procedures concurrently. The main routine starts in a single process (which we will refer to as the parent process). The parent process then creates a child process to execute the do_one_thing routine and another to execute the do_another_thing routine. The parent waits for both children to finish (as parents of the human kind often do), calls the do_wrap_up routine, and exits.
Example 1-2. A Simple C Program with Concurrent Processes
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/wait.h>
void do_one_thing(int *);
void do_another_thing(int *);
void do_wrap_up(int, int);
int shared_mem_id;
int *shared_mem_ptr;
int *r1p;
int *r2p;
extern int
main(void)
{
pid_t child1_pid, child2_pid;
int status;
/* initialize shared memory segment */
shared_mem_id = shmget(IPC_PRIVATE, 2*sizeof(int), 0660);
shared_mem_ptr = (int *)shmat(shared_mem_id, (void *)0, 0);
r1p = shared_mem_ptr;
r2p = (shared_mem_ptr + 1);
*r1p = 0;
*r2p = 0;
if ((child1_pid = fork()) == 0) {
/* first child */
do_one_thing(r1p);
exit(0);
}
/* parent */
if ((child2_pid = fork()) == 0) {
/* second child */
do_another_thing(r2p);
exit(0);
}
/* parent */
waitpid(child1_pid, &status, 0);
waitpid(child2_pid, &status, 0);
do_wrap_up(*r1p, *r2p);
return 0;
}The UNIX system call that creates a new process is fork. The fork call creates a child process that is identical to its parent process at the time the parent called fork with the following differences:
The child has its own process identifier, or PID.
The fork call provides different return values to the parent and the child processes.
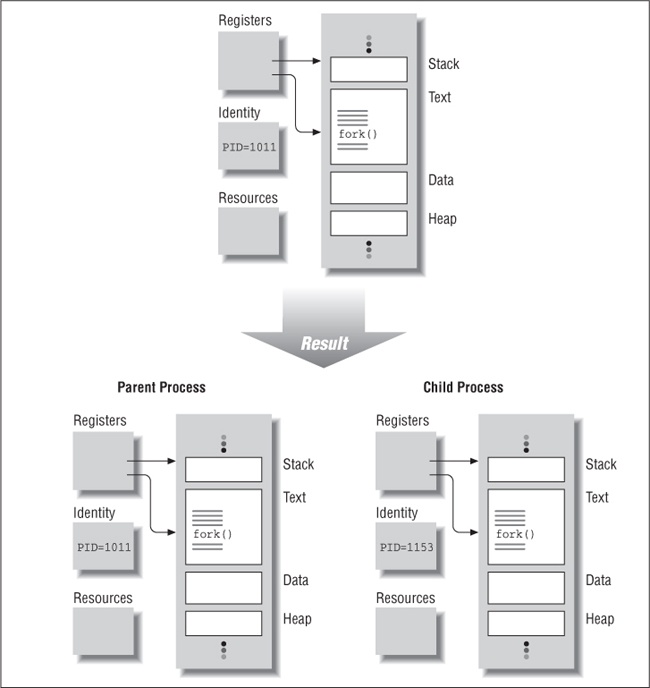
Figure 1-5 shows a process as it forks. Here, both parent and child are executing at the point in the program just following the fork call. Interestingly, the child begins executing as if it were returning from the fork call issued by its parent. It can do so because it starts out as a nearly identical copy of its parent. The initial values of all of its variables and the state of its system resources (such as file descriptors) are the same as those of its parent.
If the fork call returns to both the parent and child, why donât the parent and child execute the same instructions following the fork? UNIX programmers specify different code paths for parent and child by examining the return value of the fork call. The fork call always returns a value of 0 to the child and the childâs PID to the parent. Because of this semantic we almost always see fork used as shown in Example 1-3.
Example 1-3. A fork Call (simple_processes.c)
if ((pid = fork()) < 0 ) {
/* Fork system call failed */
.
.
.
perror("fork"), exit(1);
}else if (pid == 0) {
/* Child only, pid is 0 */
.
.
.
return 0;
}else {
/* Parent only , pid is child's process ID */
.
.
.
}After the program forks into two different processes, the parent and child execute independently unless you add explicit synchronization. Each process executes its own instructions serially, although the way in which the statements of each may be interwoven by concurrency is utterly unpredictable. In fact, one process could completely finish before the other even starts (or resumes, in the case in which the parent is the last to the finish line). To see what we mean, letâs look at the output from some test runs of our program in Example 1-2.
# simple_processes doing another doing one thing doing another doing one thing doing another doing one thing doing one thing doing another wrap up: one thing 4, another 4, total 8 # simple_processes doing another doing another doing one thing doing another doing one thing doing one thing doing another doing one thing wrap up: one thing 4, another 4, total 8 #
This program is a good example of parallelism and it worksâas do the many real UNIX programs that use multiple processes. When looking for concurrency, then, why choose multiple threads over multiple processes? The overwhelming reason lies in the single largest benefit of multithreaded programming: threads require less program and system overhead to run than processes do. The operating system performs less work on behalf of a multithreaded program than it does for a multiprocess program. This translates into a performance gain for the multithreaded program.
Now that weâve seen how UNIX programmers traditionally add concurrency to a program, letâs look at a way of doing so that employs threads. Example 1-4 shows how our single-process program would look if multiple threads execute its procedures concurrently. The program starts in a single thread, which, for reasons of clarity, weâll refer to as the main thread. For the most part, the operating system does not recognize any thread as being a parent or master thread â from its viewpoint, all threads in a process are equal.
Using Pthreads function calls, the creator thread spawns a thread to execute the do_one_thing routine and another to execute the do_another_thing routine. It waits for both threads to finish, calls the do_wrap_up routine, and exits. In the same way that the processes behave in our multiprocess version of the program, each thread executes independently unless you add explicit synchronization.
Example 1-4. A Simple C Program with Concurrent Threads (simple_threads.c)
#include <stdio.h>
#include <pthread.h>
void do_one_thing(int *);
void do_another_thing(int *);
void do_wrap_up(int, int);
int r1 = 0, r2 = 0;
extern int
main(void)
{
pthread_t thread1, thread2;
pthread_create(&thread1,
NULL,
(void *) do_one_thing,
(void *) &r1);
pthread_create(&thread2,
NULL,
(void *) do_another_thing,
(void *) &r2);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
do_wrap_up(r1, r2);
return 0;
}Whereas you create a new process by using the UNIX fork system call, you create a new thread by calling the pthread_create Pthreads function. You provide the following arguments:
A pointer to a buffer to which pthread_create returns a value that identifies the newly created thread. This value, or handle, is of type pthread_t.[1] You can use it in all subsequent calls to refer to this specific thread.
A pointer to a structure known as a thread attribute object. A thread attribute object specifies various characteristics for the new thread. In the example program, we pass a value of NULL for this argument, indicating that we accept the default characteristics for the new thread.
A pointer to the routine at which the new thread will start executing.
A pointer to a parameter to be passed to the routine at which the new thread starts.
Like most Pthreads functions, pthread_create returns a value that indicates whether it has succeeded or failed. A zero value represents success, and a nonzero value indicates and identifies an error.
The formal prototype of a start routine is (void*)routine(void*arg). In our code example, we are adding threads to an existing program (a not atypical scenario) and using the (void *) cast to quit the compiler. In later examples, we redeclare the routine to the correct prototype where possible.
In the multiprocess version of our example (Example 1-2), we could refer to the caller of fork as the parent process and the process it creates as the child process. We could do so because UNIX process management recognizes a special relationship between the two. It is this relationship that, for instance, allows a parent to issue a wait system call to implicitly wait for one of its children.
The Pthreads concurrent programming environment maintains no such special relationship between threads. We may call the thread that creates another thread the creator thread and the thread it creates the spawned thread, but thatâs just semantics. Creator threads and spawned threads have exactly the same properties in the eyes of the Pthreads. The only thread that has slightly different properties than any other is the first thread in the process, which is known as the main thread. In this simple program, none of the differences have any significance.
Once the two pthread_create calls in our example program return, three threads exist concurrently. Which will run first? Will one run to completion before the others, or will their execution be interleaved? It depends on the default scheduling policies of the underlying Pthreads implementation. It could be predictable, but then again, it may not be. The output on our system looks like this:
# simple_threads doing another doing one thing doing another doing one thing doing another doing one thing doing another doing one thing wrap up: one thing 4, another 4, total 8 # simple_threads doing another doing one thing doing another doing one thing doing one thing doing another doing one thing doing another wrap up: one thing 4, another 4, total 8 #
Letâs make a distinction between concurrent and parallel programming for the remainder of the book. Weâll use concurrent programming in a general sense to refer to environments in which the tasks we define can occur in any order. One task can occur before or after another, and some or all tasks can be performed at the same time. Weâll use parallel programming to specifically refer to the simultaneous execution of concurrent tasks on different processors. Thus, all parallel programming is concurrent, but not all concurrent programming is parallel.
The Pthreads standard specifies concurrency; it allows parallelism to be at the option of system implementors. As a programmer, all you can do is define those tasks, or threads, that can occur concurrently. Whether the threads actually run in parallel is a function of the operating system and hardware on which they run. Because Pthreads was designed in this way, a Pthreads program can run without modification on uniprocessor as well as multiprocessor systems.
Okay, so portability is great, but what of performance? All of our Pthreads programs will be running with specific Pthreads libraries, operating systems, and hardware. To squeeze the best performance out of a multithreaded application, you must understand the specifics of the environment in which it will be runningâespecially those details that are beyond the letter of the standard. Weâll spend some time in the later sections of this book identifying and describing the implementation-specific issues of Pthreads.
Even in our simple program, in Example 1-1 through Example 1-4, some parts can be executed in any order and some cannot. The first two routines, do_one_thing and do_another_thing, can run concurrently because they update separate variables and therefore do not conflict. But the third routine, do_wrap_up, must read those variables, and therefore must ensure that the other routines have finished using them before it can read them. We must force an order upon the events in our program, or synchronize them, to guarantee that the last routine executes only after the first two have completed.
In threads programming, we use synchronization to make sure that one event in one thread happens before another event in another thread. A simple analogy would involve two people working together to jump start a car, one attaching the cables under the hood and one in the car getting ready to turn the key. The two must use some signal between them so that the person connecting the cables completes the task before the other turns the key. This is real life synchronization.
In general, cooperation between concurrent procedures leads to the sharing of data, files, and communication channels. This sharing, in turn, leads to a need for synchronization. For instance, consider a program that contains three routines. Two routines write to variables and the third reads them. For the final routine to read the right values, you must add some synchronization. Itâs telling that, of all the function calls supplied in a Pthreads library, only oneâpthread_createâis used to enable concurrency. Almost all of the other function calls are there to replace the synchronization that was inherent in the program when it executed serially â and slowly!
In the multiprocess version of our program, Example 1-2, we used the UNIX wait-pid system call to prevent the parent process from executing the do_wrap_up routine before the other two processes completed the do_one_thing and do_another_thing routines and exited. The waitpid call provides synchronization by suspending its caller until a child process exits. (Notice that we use the waitpid call only in the code path of the parent.) In the Pthreads version of our program (Example 1-4), we use the pthread_join call to synchronize the threadsâ execution. The pthread_join call provides synchronization for threads similar to that which waitpid provides for processes, suspending its caller until another thread exits. Unlike waitpid, which is specifically intended for parent and child processes, you can use pthread_join between any two threads in a program.
Both the multiprocess and multithreaded versions of our program use coarse methods to synchronize. One process or thread just stalled until the others caught up and finished. In later sections of this book weâll go into great detail on the finer methods of Pthreads synchronization, namely mutex variables and condition variables. The finer methods allow you to synchronize thread activity on a threadâs access to one or more variables, rather than blocking the execution of an entire routine and thread in which it executes. Using the finer synchronization techniques, threads can spend less time waiting on each other and more time accomplishing the tasks for which they were designed.
As a quick introduction to mutex variables, letâs make a slight modification to the Pthreads version of our simple program. In Example 1-5, weâll add a new variable, r3. Because all routines will read from and write to this variable, weâll need some synchronization to control access to it. For this, weâll define a mutex variable (of type pthread_mutex_t) and initialize it. (Just as a thread can have a thread attribute object, a mutex can have a mutex attribute object that indicates its special characteristics. Here, too, weâll pass a value of NULL for this argument, indicating that we accept the default characteristics for the new mutex.)
Example 1-5. A Simple C Program with Concurrent Threads and a Mutex (simple_mutex.c)
#include <stdio.h>
#include <pthread.h>
void do_one_thing(int *);
void do_another_thing(int *);
void do_wrap_up(int, int);
int r1 = 0, r2 = 0, r3 = 0;
pthread_mutex_t r3_mutex=PTHREAD_MUTEX_INITIALIZER;
extern int
main(int argc, char **argv)
{
pthread_t thread1, thread2;
r3 = atoi(argv[1]);
pthread_create(&thread1,
NULL,
(void *) do_one_thing,
(void *) &r1);
pthread_create(&thread2,
NULL,
(void *) do_another_thing,
(void *) &r2);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
do_wrap_up(r1, r2);
return 0;
}Weâll also make changes to the routines that will read from and write to r3. Weâll synchronize their access to r3 by using the mutex we created in the main thread. When weâre finished, the code for do_another_thing and do_wrap_up will resemble the code in do_one_thing in Example 1-6.
Example 1-6. Concurrent Threads and a Mutex: do_one_thing Routine
void do_one_thing(int *pnum_times)
{
int i, j, x;
pthread_mutex_lock(&r3_mutex);
if (r3 > 0) {
x = r3;
r3--;
}else {
x = 1;
}
pthread_mutex_unlock(&r3_mutex);
for (i = 0; i < 4; i++) {
printf("doing one thing\n");
for (j = 0; j < 10000; j++) x = x + i;
(*pnum_times)++;
}
}The mutex variable acts like a lock protecting access to a shared resourceâin this case the variable r3 in memory. Whichever thread obtains the lock on the mutex in a call to pthread_mutex_lock has the right to access the shared resource it protects. It relinquishes this right when it releases the lock with the pthread_mutex_unlock call. The mutex gets its name from the term mutual exclusionâall threads have a mutual relationship with regard to the mutex variable; whichever thread holds the lock excludes all others from access.
Youâll notice in Example 1-6 that you must make special Pthreads calls to manipulate mutexes. You canât just invent mutexes in your C code by testing and setting some sort of synchronization flag. If your code tests the mutex and then sets it, you leave a tiny (but potentially fatal) length of time during which another thread could also test and set the same mutex. Pthreads implementors avoid this window of vulnerability by taking advantage of operating system services or special machine instructions.
From a programming standpoint, the major difference between the multiprocess and multithreaded concurrency models is that, by default, all threads share the resources of the process in which they exist. Independent processes share nothing. Threads share such process resources as global variables and file descriptors. If one thread changes the value of any such resource, the change will be evident to any other thread in the process, if anyone cares to look. The sharing of process resources among threads is one of the multithreaded programming modelâs major performance advantages, as well as one of its most difficult programming aspects. Having all of this context available to all threads in the same memory facilitates communication between threads. However, at the same time, it makes it easy to introduce errors of the sort in which one thread affects the value of a variable used by another thread in ways the other thread did not expect.
In Example 1-6, because the do_one_thing and do_another_thing routines simply place their results into global variables, the main thread can also access them should it need to. Because shared data calls for synchronization, the program uses the pthread_join call to enforce the order in which different threads write to and read from these global variables. The way this works is pretty simple. The two spawned threads know that, as long as they are running, the main thread has not passed its pthread_join call and, so, wonât look at their output values. The main thread knows that, once it has passed the second pthread_join call, no other threads are active. The values of the output parameters are set to their final value and can be used.
The processes in the multiprocess version of our program also use shared memory, but the program must do something special so that they can use it. We used the System V shared memory interface. Before it creates any child processes, the parent initializes a region of shared memory from the system using the shmget and shmat calls. After the fork call, all the processes of the parent and its children have common access to this memory, using it in the same way as the multithreaded version uses global variables, and all the parent and children processes can see whatever changes any of them may make to it.
When two concurrent procedures communicate, one writing data and one reading data, they must adopt some type of synchronization so that the reader knows when the writer has completed and the writer knows that the reader is ready for more data. Some programming environments provide explicit communication mechanisms such as message passing. The Pthreads concurrent programming environment provides a more implicit (some would call it primitive) mechanism. Threads share all global variables. This affords threads programmers plenty of opportunities for synchronization.
Multiple processes can use any of the many other UNIX Interprocess Communication (IPC) mechanisms: sockets, shared memory, and messages, to name a few. The multiprocess version of our program uses shared memory, but the other methods are equally valid. Even the waitpid call in our program could be used to exchange information, if the program checked its return value. However, in the multiprocess world, all types of IPC involve a call into the operating systemâto initialize shared memory or a message structure, for instance. This makes communication between processes more expensive than communication between threads.
We can also order the events in our program by imposing some type of scheduling policy on them. Unless our program is running on a system with an infinite number of CPUs, itâs a safe bet that, sooner or later, there will be more concurrent tasks ready to run in our program than there are CPUs available to run them. The operating system uses its scheduler to select from the pool of ready and runnable tasks those that it will run. In a sense, the scheduler synchronizes the tasksâ access to a shared resource: the systemâs CPUs.
Neither the multithreaded version of our program nor the multiprocess version imposes any specific scheduling requirements on its tasks. POSIX defines some scheduling calls as an optional part of its Pthreads package, allowing you to select scheduling policies and priorities for threads.
When you create a thread, pthread_create returns a thread handle of type pthread_t. You can save this handle and use it to determine a threadâs identity using the pthread_self and pthread_equal function calls. The pthread_self call returns the thread handle of the calling thread and pthread_equal compares two thread handles.[2] You might use the two calls to identify a thread when it enters a routine, as shown in Example 1-7.
Example 1-7. Code that Examines the Identity of the Calling Thread (ident.c)
.
.
.
pthread_t io_thread;
.
.
extern int
main(void)
{
.
.
.
pthread_create(&io_thread,
.... );
.
.
.
}
void routine_x(void)
{
pthread_t thread;
.
.
.
thread = pthread_self();
if (pthread_equal(io_thread, thread)) {
.
.
.
}
.
.
.
}A process terminates when it comes to the end of main. At that time the operating system reclaims the processâs resources and stores its exit status. Similarly, a thread exits when it comes to the end of the routine in which it was started. (By the way, all threads expire when the process in which they run exits.) When a thread terminates, the Pthreads library reclaims any process or system resources the thread was using and stores its exit status. A thread can also explicitly exit with a call to pthread_exit. You can terminate another thread by calling pthread_cancel. In any of these cases, the Pthreads library runs any routines in its cleanup stack and any destructors in keys in which it has store values. Weâll describe these features in Chapter 4.
The Pthreads library may or may not save the exit status of a thread when the thread exits, depending upon whether the thread is joinable or detached. A joinable thread, the default state of a thread at its creation, does have its exit status saved; a detached thread does not. Detaching a thread gives the library a break and lets it immediately reclaim the resources associated with the thread. Because the library will not have an exit status for a detached thread, you cannot use a pthread_join to join it. Weâll show you how to dynamically set the state of a thread to detached in Chapter 2, when we introduce the pthread_detach call. In Chapter 4, weâll show you how to create a thread in the detached state by specifying attribute objects.
What is the exit status of a thread? You can associate an exit status with a thread in either of two ways:
As defined by the Pthreads standard, the thread-start routine (specified in the pthread_create call) returns a (void *) type. However, youâll often find that your thread-start routines must return something other than an addressâe.g., a binary TRUE/FALSE indicator. They can do this quite easily as long as you remember to cast the return value as a (void *) type and avoid using a value that conflicts with PTHREAD_CANCELED, the only status value that the Pthreads library itself may return. (Pthreads implementations cannot define PTHREAD_CANCELED as a valid address or as NULL, so youâre always safest when returning an address.) Of course, if the thread running the thread-start routine cannot be canceled (peek ahead to Chapter 4 to learn a bit about cancellation), you can ignore this restriction.
In Example 1-8, weâve defined three possible exit status values and elected to have routine_x return pointers to integer constants with these values. We use pthread_exit and âreturn interchangeably.
Example 1-8. Specifying a Threadâs Exit Status (exit_status_alternative.c)
#include <stdio.h>
#include <pthread.h>
pthread_t thread;
static int arg;
static const int internal_error = -12;
static const int normal_error = -10;
static const int success = 1;
void * routine_x(void *arg_in)
{
int *arg = (int *)arg_in;
.
.
.
if ( /* something that shouldn't have happened */) {
pthread_exit((void *) &real_bad_error);
}else if ( /* normal failure */ ) {
return ((void *) &normal_error);
}else {
return ((void *) &success);
}
}
extern int
main(int argc, char **argv)
{
pthread_t thread;
void *statusp;
.
.
.
pthread_create(&thread, NULL, routine_x, &arg);
pthread_join(thread, &statusp);
if (*statusp == PTHREAD_CANCELED) {
printf("Thread was canceled.\n");
}else {
printf("Thread completed and exit status is %ld.\n", *(int *)statusp);
}
return 0;
}A final note on pthread_join is in order. Its purpose is to allow a single thread to wait on anotherâs termination. The result of having multiple threads concurrently call pthread_join is undefined in the Pthreads standard.
Most Pthreads library calls return zero on success and an error number otherwise.[3] Errors numbers are defined in the errno.h header file. The Pthreads standard doesnât require library calls to set âerrno, the global variable traditionally used by UNIX and POSIX.1 calls to deliver an error to their callers.
You can use code similar to that in Example 1-9 to perform error checking on a Pthreads call.
Example 1-9. Full Error-Checking for a Pthreads Library Call
#include <errno.h>
#include <stdio.h>
.
.
.
if (rtn = pthread_create(...)) {
/* error has occurred */
fprintf(stderr,"Error: pthread_create, ");
if (rtn == EAGAIN)
fprintf(stderr,"Insufficent resources\n");
else if (rtn == EINVAL)
fprintf(stderr, "Invalid arguments\n");
exit(1);
}
/* no error */
.
.
.If your platform supports a routine to convert error numbers to a readable string such as the XPG4 call, strerror, your code could be simplified as in Example 1-10.
Example 1-10. Full Error-Checking for a Pthreads Library Call, Simplified
#include <string.h> #include <stdio.h> . . . if (rtn = pthread_create(...)) fprintf(stderr, "Error: pthread_create, %s\n", strerror(rtn)), exit(1); /* no error */ . . .
In both examples, we made the rather typical decision to terminate the entire program rather than the individual thread that encountered the error (that is, we called exit rather than pthread_exit). What you do depends upon what your program is doing and what type of error it encounters.
As you may have noticed, we normally donât test the return values of the Pthreads library calls we make in the code examples in this book. We felt that doing so would get in the way of the threads programming practices the examples are meant to illustrate. If we were writing this code for a commercial product, we would diligently perform all required error checking.
If both the process model and threads model can provide concurrent program execution, why use threads over processes?
Creating a new process can be expensive. It takes time. (A call into the operating system is needed, and if the process creation triggers process rescheduling activity, the operating systemâs context-switching mechanism will become involved.) It takes memory. (The entire process must be replicated.) Add to this the cost of interprocess communication and synchronization of shared data, which also may involve calls into the operating system kernel, and threads provide an attractive alternative.
Threads can be created without replicating an entire process. Furthermore, some, if not all, of the work of creating a thread is done in user space rather than kernel space. When processes synchronize, they usually have to issue system calls, a relatively expensive operation that involves trapping into the kernel. But threads can synchronize by simply monitoring a variableâin other words, staying within the user address space of the program.
Weâll spell out the advantages of threads over the multiprocess model of multitasking in our performance measurements in Chapter 6. In the meantime, weâll show you how to build a multithreaded program.
Revisiting the techniques used to obtain concurrency that we discussed earlierâpotential parallelism, overlapping I/O, asynchronous events, and real-time schedulingâwe find that UNIX offers many disjointed mechanisms to accomplish them between processes. They include the select system call, signals, nonblocking I/O, and the setjmp/longjmp system call pair, plus many calls for real time (such as aio_read and aio_write) and parallel processing. Pthreads offers a clean, consistent way to address all of these motivations. If youâre a disciplined programmer, designing and coding a multithreaded program should be easier than designing and coding a multiprocess program.
Now, we know that the example program weâve been looking at in this chapter is far too simple to convince anyone that a particular programming style is more structured or elegant than another. Subsequent examples will venture into more complex territory and, in doing so, illustrate Pthreads mechanisms for a more practical set of coding problems. We hope that they may make the case for Pthreads.
The major benefit of multithreaded programs over nonthreaded ones is in their ability to concurrently execute tasks. However, in providing concurrency, multithreaded programs introduce a certain amount of overhead. If you introduce threads in an application that canât use concurrency, youâll add overhead without any performance benefit.
So what makes concurrency possible? First, of course, your application must consist of some independent tasksâtasks that do not depend on the completion of other tasks to proceed. Secondly, you must be confident that concurrent execution of these tasks would be faster than their serial execution.
On a uniprocessing system, the concurrent execution of independent tasks will be faster than their serial execution if at least one of these tasks issues a lot of I/O requests and must wait for the device to complete each request. On a multiprocessor, even CPU-bound tasks can benefit from concurrency because they can truly proceed in parallel.
If you are writing an application for a uniprocessor, look at overlapping I/O and asynchronous events as the motivation for threading an application. If your program is hung up in doing a lot of disk, file, or network accesses when it could be doing other useful things, threads offer a means of doing them while the thread that handles the I/O is waiting.[4] If your program must deal with many asynchronous events, such as the receipt of an out-of-band message, threads give you an efficient way to structure its event handling where the only alternatives for a single-threaded process would be to either abruptly change context or put off handling the event to a more convenient time. The server portion of a client/server program often meets both of these criteria for concurrency: it must handle asynchronous requests and wait while retrieving and storing data in secondary storage.
If your application has been designed to use multiple processes, itâs likely that it would benefit from threading. A common design model for a UNIX server daemon is to accept requests and fork a child image of itself to process the request. If the benefits of concurrency outweighed the overhead of using separate processes in the application, threading is bound to improve its performance because threads involve less overhead.
The remaining class of applications that can benefit from threads are those that execute on multiprocessing systems. Purely CPU-bound applications can achieve a performance boost with threads. A matrix-multiply program (or similar analytical program) with independent computational tasks but no excessive I/O requirements would not benefit from threads on a uniprocessing system. However, on a multiprocessor, this same application could speed up dramatically as the threads performed their computations in parallel.
As weâll see in Chapter 6, there are commonly three different types of Pthreads implementations. To take full advantage of a multiprocessing system, youâll need an implementation thatâs sophisticated enough to allow multiple threads in a single process to access multiple CPUs.
[1] The pthread_t type may look a little strange to you if youâre used to the data types returned by C language system calls on many UNIX systems. Because many of these types (like int) reveal quite a bit about the underlying architecture of a given platform (such as whether its addresses are 16, 32, or 64 bits long), POSIX prefers to create new data types that conceal these fundamental differences. By convention, the names of these data types end in _t.
[2] The Pthreads standard leaves the exact definition of the pthread_t type up to system implementors. Because a system implementor might define a thread handle to be a structure, you should always use pthread_equal to compare threads. A direct comparison (such as io_thread == thread) may not work.
[3] The two Pthreads library calls that donât return an error code upon failure are pthread_getspecific and pthread_self. A pthread_getspecific call returns NULL if itâs unsuccessful. A pthread_self call always succeeds.
[4] A side benefit is that your code is ready to take advantage of multiprocessing systems in the future. Multiprocessing UNIX hosts are not restricted to exotic scientific number crunching anymore as two- to four-CPU server and desktop platforms have become commonplace.
Get PThreads Programming now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

