Chapter 1. Korn Shell Basics
You’ve used your computer for simple tasks, such as invoking your favorite application programs, reading your electronic mail, and perhaps examining and printing files. You know that your machine runs the Unix operating system, or maybe you know it under some other name, like Solaris, HP-UX, AIX, or SunOS. (Or you may be using a system such as GNU/Linux or one of the 4.4-BSD-derived systems that is not based on the original Unix source code.) But apart from that, you may not have given too much thought to what goes on inside the machine when you type in a command and hit ENTER.
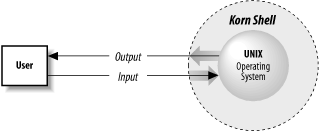
It is true that several layers of events take place whenever you enter a command, but we’re going to consider only the top layer, known as the shell. Generally speaking, a shell is any user interface to the Unix operating system, i.e., any program that takes input from the user, translates it into instructions that the operating system can understand, and conveys the operating system’s output back to the user.
There are various types of user interface. The Korn shell belongs to the most common category, known as character-based user interfaces. These interfaces accept lines of textual commands that the user types; they usually produce text-based output. Other types of interface include the now-common graphical user interfaces (GUI), which add the ability to display arbitrary graphics (not just typewriter characters) and to accept input from mice and other pointing devices, touch-screen interfaces (such as those you see on some automatic teller machines), and so on.
What Is a Shell?
The shell’s job, then, is to translate the user’s command lines into operating system instructions. For example, consider this command line:
sort -n phonelist > phonelist.sorted
This means, “Sort lines in the file phonelist in numerical order, and put the result in the file phonelist.sorted.” Here’s what the shell does with this command:
Breaks up the line into the pieces
sort,-n,phonelist,>, andphonelist.sorted. These pieces are called words.Determines the purpose of the words:
sortis a command;-nandphonelistare arguments;>andphonelist.sorted, taken together, are I/O instructions.Sets up the I/O according to
> phonelist.sorted(output to the file phonelist.sorted) and some standard, implicit instructions.Finds the command sort in a file and runs it with the option -n (numerical order) and the argument phonelist (input filename).
Of course, each step really involves several substeps, and each substep includes a particular instruction to the underlying operating system.
Remember that the shell itself is not Unix — just the user interface to it. This is illustrated in Figure 1-1. Unix is one of the first operating systems to make the user interface independent of the operating system.
Scope of This Book
In this book, you will learn about the Korn shell, which is the most recent and powerful of the shells distributed with commercial Unix systems. There are two ways to use the Korn shell: as a user interface and as a programming environment.
This chapter and the next cover interactive use. These two chapters should give you enough background to use the shell confidently and productively for most of your everyday tasks.
After you have been using the shell for a while, you will undoubtedly find certain characteristics of your environment (the shell’s “look and feel”) that you would like to change and tasks that you would like to automate. Chapter 3 shows several ways of doing this.
Chapter 3 also prepares you for shell programming, the bulk of which is covered in Chapter 4 through Chapter 6. You need not have any programming experience to understand these chapters and learn shell programming. Chapter 7 and Chapter 8 give more complete descriptions of the shell’s I/O and process handling capabilities, and Chapter 9 discusses various techniques for finding and removing problems in your shell programs.
You’ll learn a lot about the Korn shell in this book; you’ll also learn about Unix utilities and the way the Unix operating system works in general. It’s possible to become a virtuoso shell programmer without any previous programming experience. At the same time, we’ve carefully avoided going down past a certain level of detail about Unix internals. We maintain that you shouldn’t have to be an internals expert to use and program the shell effectively, and we won’t dwell on the few shell features that are intended specifically for low-level systems programmers.
History of Unix Shells
The independence of the shell from the Unix operating system per se has led to the development of dozens of shells throughout Unix history, though only a few have achieved widespread use.
The first major shell was the Bourne shell (named after its inventor, Stephen Bourne); it was included in the first widely popular version of Unix, Version 7, starting in 1979. The Bourne shell is known on the system as sh. Although Unix has gone through many, many changes, the Bourne shell is still popular and essentially unchanged. Several Unix utilities and administration features depend on it.
The first widely used alternative shell was the C shell, or csh. It was written by Bill Joy at the University of California at Berkeley as part of the Berkeley Software Distribution (BSD) version of Unix that came out a couple of years after Version 7. It’s included in essentially all recent Unix versions. (A popular variant is the so-called Twenex csh, tcsh.)
The C shell gets its name from the resemblance of its commands to statements in the C programming language, which makes the shell easier for programmers on Unix systems to learn. It supports a number of operating system features (e.g., job control; see Chapter 8) that were once unique to BSD Unix but by now have migrated to just about all other modern versions. It also has a few important features (e.g., aliases; see Chapter 3) that make it easier to use in general.
The Korn Shell
The Korn shell, or ksh, was invented by David Korn of AT&T Bell Laboratories in the mid-1980s. It is almost entirely upwardly compatible with the Bourne shell,[2] which means that Bourne shell users can use it right away, and all system utilities that use the Bourne shell can use the Korn shell instead. In fact, some systems have the Korn shell installed as if it were the Bourne shell.
The Korn shell began its public life in 1986 as part of AT&T’s “Experimental Toolchest,” meaning that its source code was available at very low cost to anyone who was willing to use it without technical support and with the knowledge that it might still have a few bugs. Eventually, AT&T’s Unix System Laboratories (USL) decided to give it full support as a Unix utility. As of USL’s version of Unix called System V Release 4 (SVR4 for short, 1989), it was distributed with all USL Unix systems, all third-party versions of Unix derived from SVR4, and many other versions.
Late in 1993, David Korn released a newer version, popularly known as ksh93. This version is distributed with many commercial Unix systems as part of the Common Desktop Environment (CDE), typically as the “desktop Korn shell,” /usr/dt/bin/dtksh.
Although Unix itself has changed owners several times since then, David Korn remained at Bell Laboratories until 1996, when AT&T (voluntarily, this time) split itself apart into AT&T Corporation, Lucent Technologies, and NCR. At that time, he moved to AT&T Research Laboratories from Bell Labs (which remained part of Lucent). Although both Lucent and AT&T retained full rights to the Korn shell, all enhancements and changes now come from David Korn at AT&T.
On March 1, 2000, AT&T released the ksh93 source code under an Open Source-style license. Getting the source code is discussed further in Appendix C, and the license is presented in Appendix D.
This book focuses on the 2001 version of ksh93. Occasionally, the book notes a significant difference between the 1993 and 1988 versions. Where necessary, we distinguish them as ksh93 and ksh88, respectively. Appendix A describes the differences between the 1988 and 1993 versions in an orderly fashion, and other shell versions are summarized briefly in that appendix, as well.
Features of the Korn Shell
Although the Bourne shell is still known as the “standard” shell, the Korn shell is also popular. In addition to its Bourne shell compatibility, it includes the best features of the C shell as well as several advantages of its own. It also runs more efficiently than any previous shell.
The Korn shell’s command-line editing modes are the features that tend to attract people to it at first. With command-line editing, it’s much easier to go back and fix mistakes than it is with the C shell’s history mechanism — and the Bourne shell doesn’t let you do this at all.
The other major Korn shell feature that is intended mostly for interactive users is job control. As Chapter 8 explains, job control gives you the ability to stop, start, and pause any number of commands at the same time. This feature was borrowed almost verbatim from the C shell.
The rest of the Korn shell’s important advantages are mainly meant for shell customizers and programmers. It has many new options and variables for customization, and its programming features have been significantly expanded to include function definition, more control structures, built-in regular expressions and arithmetic, associative arrays, structured variables, advanced I/O control, and more.
Getting the 1993 Korn Shell
This book covers the 1993 version of the Korn shell. A large amount of what’s covered is unique to that shell; a subset of what is unique applies only to the recent versions available directly from AT&T. In order to make best use of the book, you should be using the 1993 Korn shell. Use the following sequence of instructions to determine what shell you currently have and whether the 1993 Korn shell exists on your system, and to make the 1993 Korn shell be your login shell.
Determine which shell you are using. The
SHELLvariable denotes your login shell. Log in to your system and typeecho $SHELLat the prompt. You will see a response containingsh,csh, orksh; these denote the Bourne, C, and Korn shells, respectively. (There’s also a good chance that you’re using a third-party shell such as bash or tcsh.) If the response isksh, go to step 3. Otherwise, continue to step 2.See if some version of ksh exists on your system in a standard directory. Type
ksh. If that works (prints a$prompt), you have a version of the Korn shell; proceed to step 3. Otherwise, proceed to step 5.Check the version. Type
echo ${.sh.version}. If that prints a version, you’re all set; skip the rest of these instructions. Otherwise, continue to step 4.You don’t have the 1993 version of the Korn shell. To find out what version you do have, type the command
set -o emacs, then press CTRL-V. This will tell you if you have the 1988 version or the Public Domain Korn shell. In either case, continue to step 5.Type the command
/usr/dt/bin/dtksh. If this gives you a$prompt, you have the Desktop Korn Shell, which is based on an early version of ksh93. You may use this version; almost everything in this book will work. Go to step 7.You need to download an executable version of ksh93 or download the source and build an executable from it. These tasks are described in Appendix C. It would be best to enlist the help of your system administrator for this step. Once you have a working ksh93, continue to step 7.
Install ksh93 as your login shell. There are two situations; pick the one appropriate to you:
- Single-user system
On a single-user system, where you are the administrator, you will probably need to add the full path to ksh93 to the file /etc/shells as the first step. Then, you should be able to change your login shell by typing
chshksh-name, where ksh-name is the full path to the ksh93 executable. If this works, you’ll be prompted for your password. Type in your password, then log out and log back in again to start using the Korn shell.If chsh doesn’t exist or doesn’t work, check the man page for passwd(1). Look for either the -e or -s options for updating your password file information. Use whatever is appropriate for your system to change your login shell.
If none of the above works, you can resort to editing the /etc/passwd file while logged in as
root. If you have the vipw(8) command, you should use that to edit your password file. Otherwise, edit the file manually with your favorite text editor.- Large multi-user system
This situation is even more complex than the single-user case. It is best to let your system administrator handle changing the shell for you. Most large installations have a “helpdesk” (accessible via email or phone, or both) for entering such requests.
Interactive Shell Use
When you use the shell interactively, you engage in a
login session that begins when you log in and ends
when you exit or press CTRL-D.[3]
During a login session, you type command lines into the
shell; these are lines of text ending in ENTER that
you type into your terminal or workstation.[4]
By default, the shell prompts you
for each command with a dollar sign,
though, as you will see in Chapter 3 the prompt can be changed.
Commands, Arguments, and Options
Shell command lines consist of one or more words, which are separated on a command line by spaces or TABs. The first word on the line is the command. The rest (if any) are arguments (also called parameters) to the command, which are names of things on which the command will act.
For example, the command line lpr myfile consists of the command lpr (print a file)
and the single argument myfile.
lpr treats myfile
as the name of a file to print. Arguments are often names
of files, but not necessarily: in the command line
mail billr, the mail program treats billr
as the name of the user to which a message will be sent.
An option is a special type of argument that gives
the command specific information on what it is supposed to do.
Options usually consist of a dash followed by a letter;
we say “usually” because this is a convention rather than a
hard-and-fast rule. The command lpr -h myfile contains
the option -h, which tells lpr not to print the
“banner page” before it prints the file.
Sometimes options take their own arguments. For example,
lpr -P hp3si -h myfile has two options and one argument.
The first option is -P hp3si, which means “Send the output
to the printer called hp3si.” The second
option and argument are as above.
Built-in Help
Almost all the built-in commands in ksh have both minimal and more extensive “online” help. If you give a command the -? option, it prints a short usage summary:
$ cd -?
Usage: cd [-LP] [directory]
Or: cd [ options ] old new
(You may wish to quote the ?, since, as we will see later,
it is special to the shell.)
You may also give the --man option to print
help in the form of the traditional Unix man page.[5]
The output uses ANSI standard
escape sequences to produce a visible change on the screen, rendered here using
a bold font:
$cd --manNAMEcd - change working directorySYNOPSIScd[options] [directory]cd[options] old newDESCRIPTIONcdchanges the current working directory of the current shell environment. In the first form with one operand, ifdirectorybegins with/, or if the first component is.or.., the directory will be changed to this directory. ...
Similarly, the --html option produces output in HTML format for later rendering with a web browser.
Finally, the --nroff option let’s you produce each command’s help in the form of nroff -man input.[6] This is convenient for formatting the help for printed output.
For POSIX compliance, a few commands don’t accept these options:
echo,
false,
jobs,
login,
newgrp,
true,
and
:.
For test, you have to type
test --man -- to get the online help.
Files
Although arguments to commands aren’t always files, files are the most important types of “things” on any Unix system. A file can contain any kind of information, and there are different types of files. Four types are by far the most important:
- Regular files
Also called text files; these contain readable characters. For example, this book was created from several regular files that contain the text of the book plus human-readable DocBook XML formatting instructions.
- Executable files
Also called programs; these are invoked as commands. Some can’t be read by humans; others — the shell scripts that we’ll examine in this book — are just special text files. The shell itself is a (not human-readable) executable file called ksh.
- Directories
Like folders that contain other files — possibly other directories (called subdirectories).
- Symbolic links
A kind of “shortcut” from one place in the system’s directory hierarchy to another. We will see later in this chapter how symbolic links can affect interactive use of the Korn shell.
Directories
Let’s review the most important concepts about directories. The fact that directories can contain other directories leads to a hierarchical structure, more popularly known as a tree, for all files on a Unix system. Figure 1-2 shows part of a typical directory tree; ovals are regular files and rectangles are directories.
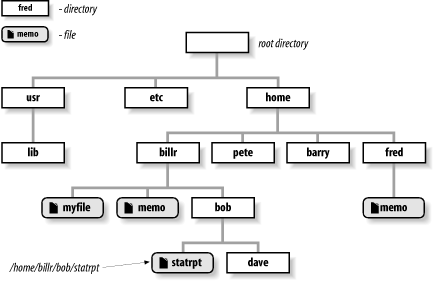
The top of the tree is a directory called “root”
that has no name on the system.[7]
All files can be named by expressing their location on the
system relative to root; such names are built by listing
all the directory names (in order from root), separated
by slashes (/), followed by the file’s name. This way
of naming files is called a full (or absolute)
pathname.
For example, say there is a file called memo in the directory fred, which is in the directory home, which is in the root directory. This file’s full pathname is /home/fred/memo.
The working directory
Of course, it’s annoying to have to use full pathnames whenever you need to specify a file, so there is also the concept of the working directory (sometimes called the current directory), which is the directory you are “in” at any given time. If you give a pathname with no leading slash, the location of the file is worked out relative to the working directory. Such pathnames are called relative pathnames; you’ll use them much more often than full pathnames.
When you log in to the system, your working directory is initially set to a special directory called your home (or login) directory. System administrators often set up the system so that everyone’s home directory name is the same as their login name, and all home directories are contained in a common directory under root. It is now common practice to use /home as the top directory for home directories.
For example, /home/billr is a typical home directory.
If this is your working directory
and you give the command lp memo, the system looks
for the file memo in /home/billr. If you have
a directory called bob in your home directory, and it
contains the file statrpt, you can print statrpt with
the command lp bob/statrpt.
Tilde notation
As you can well imagine, home directories occur often in pathnames. Although many systems are organized so that all home directories have a common parent (such as /home), you should not have to rely on that being the case, nor should you even have to know what the absolute pathname of someone’s home directory is.
Therefore, the Korn shell has a way of abbreviating home
directories: just precede the name of the user with a tilde (~).
For example, you could refer to the file memo in user
fred’s home directory as ~fred/memo.
This is an absolute pathname, so it doesn’t matter
what your working directory is when you use it. If fred’s home
directory has a subdirectory called bob and the file
is in there instead, you can use ~fred/bob/memo as its name.
Even more conveniently, a tilde by itself refers to your own home directory. You can refer to a file called notes in your home directory as ~/notes (note the difference between that and ~notes, which the shell would try to interpret as user notes’s home directory). If notes is in your bob subdirectory, you can call it ~/bob/notes. This notation is handiest when your working directory is not in your home directory tree, e.g., when it’s some “system” directory like /tmp.
Changing working directories
If you want to change your working directory, use the command cd. If you don’t remember your working directory, the command pwd tells the shell to print it.
cd takes as argument the name of the directory you
want to become your working directory. It can be relative
to your current directory, it can contain a tilde, or it can
be absolute (starting with
a slash). If you omit the argument, cd changes to your
home directory (i.e., it’s the same as cd ~).
Table 1-1 gives some sample cd commands. Each command assumes that your working directory is /home/billr just before the command is executed, and that your directory structure looks like Figure 1-2.
| Command | New working directory |
cd bob
| /home/billr/bob |
cd bob/dave
| /home/billr/bob/dave |
cd ~/bob/dave
| /home/billr/bob/dave |
cd /usr/lib
| /usr/lib |
cd ..
| /home |
cd ../pete
| /home/pete |
cd ~pete
| /home/pete |
cd billr pete
| /home/pete |
cd illr arry
| /home/barry |
The first four are straightforward. The next two use a special
directory called .. (two dots, pronounced “dot dot”),
which means “parent of this directory.”
Every directory has one of these; it’s a
universal way to get to the directory above the current
one in the hierarchy — which is called the parent directory.
Each directory also has the special directory .
(single dot), which just means “this directory.”
Thus, cd . effectively does nothing.
Both . and .. are actually
special hidden files
in each directory that point to the directory itself and to its
parent directory, respectively. The root directory is its own parent.
The last two examples in the table use a new form of the cd
command, which is not included in most Bourne shells. The
form is cd
old new. It takes the full pathname of
the current working directory and tries to find the string
old in it. If it finds the string,
it substitutes new
and changes to the resulting directory.
In the first of the two examples, the shell substitutes pete for billr in the current directory name and makes the result the new current directory. The last example shows that the substitution need not be a complete filename: substituting arry for illr in /home/billr yields /home/barry. (If the old string can’t be found in the current directory name, the shell prints an error message.)
Another feature of the Korn shell’s cd command is
the form cd -, which changes to whatever directory you
were in before the current one. For example, if you start out
in /usr/lib, type cd
without an argument
to go to your home directory, and then type
cd -, you will
be back in /usr/lib.
Symbolic links to directories
Modern Unix systems provide symbolic links. Symbolic links (sometimes called soft links) provide a kind of “shortcut” to files in a different part of the system’s file hierarchy. You can make a symbolic link to either a file or a directory, using either full or relative pathnames. When you access a file or directory via a symbolic link, Unix “follows the link” to the real file or directory.
Symbolic links to directories can generate surprising behavior. To explain why, let’s start by assuming that you’re using the regular Bourne shell, sh.[8] Now, suppose that we and user fred are working together on a project, and the primary directory for the project is under his home directory, say /home/fred/projects/important/wonderprog. That’s a fairly long pathname to have to type, even if using the tilde notation (which we can’t in the Bourne shell, but that’s another story). To make life easier, let’s create a symbolic link to the wonderprog directory in our home directory:
$shUse the Bourne shell $cdMake sure we're in our home directory $pwdShow where we are /home/billr Create the symbolic link $ln -s /home/fred/projects/important/wonderprog wonderprog
Now, when we type cd wonderprog, we end up in
/home/fred/projects/important/wonderprog:
$cd wonderprog$pwd/home/fred/projects/important/wonderprog
After working for a while adding important new features[9] to wonderprog, we remember that we need to update the .profile file in our home directory. No problem: just cd back there and start work on the file, by looking at it first with more.
$cd ..Go back up one level $more .profileLook at .profile .profile: No such file or directory
What happened?
The cd .. didn’t take us back the way we came. Instead, it
went up one level in the physical filesystem hierarchy:
$ pwd
/home/fred/projects/important
This is the “gotcha” with symbolic links; the logical view of the filesystem hierarchy presented by a symbolic link to a directory breaks down to the underlying physical reality when you cd to the parent directory.
The Korn shell works differently. It understands symbolic links and, by default, always presents you with a logical view of the filesystem. Not only is cd built into the shell, but so is pwd. Both commands accept the same two options: -L, to perform logical operations (the default), and -P, to perform the operations on the actual directories. Let’s start over in the Korn shell:
$cd wonderprog ; pwdcd through the symbolic link /home/billr/wonderprog Answer is logical location $pwd -PWhat is the physical location? /home/fred/projects/important/wonderprog Answer is physical location $cd .. ; pwdGo back up one level /home/billr Traversal was again logical $cd -P wonderprog; pwdDo a physical cd /home/fred/projects/important/wonderprog Logical now equals physical $cd .. ; pwdGo back up up one level /home/fred/projects/important Logical still equals physical
As shown, the -P option to cd and pwd lets you “get around” the Korn shell’s default use of logical positioning. Most of the time, though, logical positioning is exactly what you want.
Note
The shell sets the PWD and OLDPWD
variables correspondingly whenever you do a cd;
the results of typing pwd and
print $PWD should always be the same.
As an unrelated note that rounds out the discussion, Unix systems also provide “hard links” (or just plain links) to files. Each name for a file is called a link; all hard links refer to the same data on disk, and if the file is changed by one name, that change is seen when looking at it from a different name. Hard links have certain restrictions, which symbolic links overcome. (See ln(1) for more information.) However, you cannot make hard links to directories, so symbolic links are all that matter for cd and pwd.
Filenames and Wildcards
Sometimes you need to run a command on more than one file at a time.
The most common example of such a command is
ls, which lists information about files. In its simplest
form, without options or arguments, it lists the names of all
files in the working directory except special hidden files,
whose names begin with a dot (.).
If you give ls filename arguments,
it will list those files, which is sort of silly: if your
current directory has the files bob and fred in it,
and you type ls bob fred, the system will simply parrot
the filenames back at you.
Actually, ls is more often used with options that tell it
to list information about the files, like the -l
(long) option,
which tells ls to list the file’s owner, group, size, time of
last modification, and other information, or -a (all), which
also lists the hidden files described above.
But sometimes you
want to verify the existence of a certain group of files without
having to know all of their names; for example, if you design web pages,
you might want to see which files
in your current directory have names that end in .html.
Filenames are so important in Unix that the shell provides a built-in way to specify the pattern of a set of filenames without having to know all of the names themselves. You can use special characters, called wildcards, in filenames to turn them into patterns. We’ll show the three basic types of wildcards that all major Unix shells support, and we’ll save the Korn shell’s set of advanced wildcard operators for Chapter 4. Table 1-2 lists the basic wildcards.
| Wildcard | Matches |
?
| Any single character |
*
| Any string of characters |
[
set
]
| Any character in set |
[!
set
]
| Any character not in set |
The ? wildcard matches any single character, so that
if your directory contains the files program.c,
program.log, and
program.o, then the expression program.? matches
program.c and program.o but
not program.log.
The asterisk (*) is more powerful and far more
widely used; it matches
any string of characters. The expression
program.*
will match all three files in the previous paragraph;
web designers
can use the expression
*.html to match their input files.[10]
Table 1-3 should give you a better idea of how the asterisk works. Assume that you have the files bob, darlene, dave, ed, frank, and fred in your working directory.
Notice that * can stand for nothing: both
*ed and
*e* match
ed.
Also notice that the last example shows what the shell
does if it can’t match anything: it just leaves the string
with the wildcard untouched.
| Expression | Yields |
fr*
| frank fred |
*ed
| ed fred |
b*
| bob |
*e*
| darlene dave ed fred |
*r*
| darlene frank fred |
*
| bob darlene dave ed frank fred |
d*e
| darlene dave |
g*
| g* |
Files are kept within directories in an unspecified order;
the shell sorts the results of each wildcard expansion.
(On some systems, the sorting may be subject to an ordering that is
appropriate to the system’s location, but that is different from
the underlying machine collating order.
Unix traditionalists can use export LANG=C
to get the behavior they’re used to.)
The remaining wildcard is the set construct.
A set is a list of characters (e.g., abc),
an inclusive range (e.g., a-z), or some combination of the two.
If you want the dash character to be part of a list, just
list it first or last.
Table 1-4
(which assumes an ASCII environment)
should explain things more clearly.
| Expression | Matches |
[abc]
| a, b, or c |
[.,;]
| Period, comma, or semicolon |
[-_]
| Dash and underscore |
[a-c]
| a, b, or c |
[a-z]
| All lowercase letters |
[!0-9]
| All non-digits |
[0-9!]
| All digits and exclamation point |
[a-zA-Z]
| All lower- and uppercase letters |
[a-zA-Z0-9_-]
| All letters, all digits, underscore, and dash |
In the original wildcard example, program.[co] and
program.[a-z] both match
program.c and program.o,
but not program.log.
An exclamation point after the left bracket lets you
“negate” a set.
For example, [!.;] matches any character
except period and semicolon; [!a-zA-Z] matches any
character that isn’t a letter.
The range notation is handy, but you shouldn’t make too many
assumptions about what characters are included in a range.
It’s generally safe to use a range for uppercase letters, lowercase
letters, digits, or any subranges thereof
(e.g., [f-q], [2-6]).
Don’t use ranges
on punctuation characters or mixed-case letters: e.g.,
[a-Z] and [A-z] should not be trusted to include all of the
letters and nothing more. The problem is that such ranges are
not entirely portable between different types of computers.[11]
Another problem is that modern systems support different locales, which are ways of describing how the local character set works. In most countries, the default locale’s character set is different from that of plain ASCII. In Chapter 4, we show you how to use POSIX bracket expressions to denote letters, digits, punctuation, and other kinds of characters in a portable fashion.
The process of matching expressions containing wildcards to filenames is called wildcard expansion. This is just one of several steps the shell takes when reading and processing a command line; another that we have already seen is tilde expansion, where tildes are replaced with home directories where applicable. We’ll see others in later chapters, and the full details of the process are enumerated in Chapter 7.
However, it’s important to
be aware that the commands that you run see only the
results of wildcard expansion.
(Indeed, this is true of all expansions.)
That is, they just see a list of arguments, and they have
no knowledge of how those arguments came into being. For example, if you type
ls fr*
and your files
are as described earlier, then the shell expands the command
line to ls fred frank and invokes the
command ls
with arguments fred and frank.
If you type ls g*,
then (because there is no match) ls will be given
the literal string g* and will complain with the error message,
g* not found.
[12]
(The actual message is likely to vary from system to system.)
Here is another example that should help you understand
why this is important.
Suppose you are a C programmer.
This just means that you deal with files whose names end
in .c (programs, a.k.a. source files), .h
(header files for programs), and .o
(object code files that aren’t human-readable), as well as
other files.
Let’s say you want to list all
source, object, and header files in your working directory. The command
ls *.[cho] does the trick.
The shell expands *.[cho] to
all files whose names end in a period followed
by a c, h, or o
and passes the resulting list to ls as
arguments.
In other words, ls will see the filenames just as if they were all typed in individually — but notice that we assumed no knowledge of the actual filenames whatsoever! We let the wildcards do the work.
As you gain experience with the shell, reflect on what life would be like without wildcards. Pretty miserable, we would say.
A final note about wildcards. You can set the variable
FIGNORE to a shell pattern describing
filenames to ignore during pattern matching.
(The full pattern capabilities of the shell are described later, in
Chapter 4.)
For example,
emacs saves backup versions of files by appending a
~ to the original filename.
Often, you don’t need to see these files.
To ignore them, you
might add the following to your .profile file:
export FIGNORE='*~'
As with wildcard expansion, the test against FIGNORE
applies to all components of a pathname, not just the final one.
Input and Output
The software field — really, any scientific field — tends to advance most quickly and impressively on those few occasions when someone (i.e., not a committee) comes up with an idea that is small in concept yet enormous in its implications. The standard input and output scheme of Unix has to be on the short list of such ideas, along with such classic innovations as the LISP language, the relational data model, and object-oriented programming.
The Unix I/O scheme is based on two dazzlingly simple ideas. First, Unix file I/O takes the form of arbitrarily long sequences of characters (bytes). In contrast, file systems of older vintage have more complicated I/O schemes (e.g., “block,” “record,” “card image,” etc.). Second, everything on the system that produces or accepts data is treated as a file; this includes hardware devices like disk drives and terminals. Older systems treated every device differently. Both of these ideas have made systems programmers’ lives much more pleasant.
Standard I/O
By convention, each Unix program has a single way of accepting input called standard input, a single way of producing output called standard output, and a single way of producing error messages called standard error output, usually shortened to standard error. Of course, a program can have other input and output sources as well, as we will see in Chapter 7.
Standard I/O was the first scheme of its kind that was designed specifically for interactive users, rather than the older batch style of use that usually involved decks of punch-cards. Since the Unix shell provides the user interface, it should come as no surprise that standard I/O was designed to fit in very neatly with the shell.
All shells handle standard I/O in basically the same way. Each program that you invoke has all three standard I/O channels set to your terminal or workstation window, so that standard input is your keyboard, and standard output and error are your screen or window. For example, the mail utility prints messages to you on the standard output, and when you use it to send messages to other users, it accepts your input on the standard input. This means that you view messages on your screen and type new ones in on your keyboard.
When necessary, you can redirect input and output to come from or go to a file instead. If you want to send the contents of a preexisting file to someone as mail, you redirect mail’s standard input so that it reads from that file instead of your keyboard.
You can also hook up programs into a pipeline, in which the standard output of one program feeds directly into the standard input of another; for example, you could feed mail output directly to the lp program so that messages are printed instead of shown on the screen.
This makes it possible to use Unix utilities as building blocks for bigger programs. Many Unix utility programs are meant to be used in this way: they each perform a specific type of filtering operation on input text. Although this isn’t a textbook on Unix utilities, they are essential to productive shell use. The more popular filtering utilities are listed in Table 1-5.
| Utility | Purpose |
| cat | Copy input to output |
| grep | Search for strings in the input |
| sort | Sort lines in the input |
| cut | Extract columns from input |
| sed | Perform editing operations on input |
| tr | Translate characters in the input to other characters |
You may have used some of these before and noticed that they take names of input files as arguments and produce output on standard output. You may not know, however, that all of them (and most other Unix utilities) accept input from standard input if you omit the argument.[13]
For example, the most basic utility is cat, which simply
copies its input to its output. If you type cat with a
filename argument, it will print out the contents of that file
on your screen. But if you invoke it with no
arguments, it will read standard input and copy it to standard
output. Try it: cat will wait for you to type a line of
text; when you type ENTER, cat will parrot the text back at you. To stop the
process, hit CTRL-D at the beginning of a line (see
below for
what this character means). You will see ^D when you
type CTRL-D. Here’s what this should look like:
$catHere is a line of text.Here is a line of text.This is another line of text.This is another line of text.^D$
I/O Redirection
cat is actually short for “catenate,” i.e., link together.
It accepts multiple
filename arguments and copies them to the standard output.
But let’s pretend, for the moment, that cat
and other utilities don’t accept
filename arguments and accept only standard input. As we said
above, the shell lets you redirect standard input so that it comes
from a file. The notation command
<
filename
does this; it sets things up so that command takes standard input
from a file instead of from a terminal.
For example, if you have a file called fred that contains
some text, then cat < fred will print fred’s contents
out onto your terminal. sort < fred will sort the lines in
the fred file and print the result on your terminal
(remember: we’re pretending that utilities don’t take
filename arguments).
Similarly, command
>
filename
causes command’s
standard output to be redirected to the named file.
The classic “canonical” example of this is date > now:
the date command prints the current date and time on the
standard output; the above command saves it in a file called now.
Input and output redirectors can be combined. For example, the cp command is normally used to copy files; if for some reason it didn’t exist or was broken, you could use cat in this way:
cat <file1>file2
This would be similar to cp file1 file2.
As a mnemonic device, think of < and >
as “data funnels.”
Data goes into the big end and comes out the small end.
When used interactively, the Korn shell lets you use a shell wildcard after an I/O redirection operator. If the pattern matches exactly one file, that file is used for I/O redirection. Otherwise, the pattern is left unchanged, and the shell attempts to open a file whose name is exactly what you typed. In addition, it is invalid to attempt a redirection with the null string as the filename (such as might happen when using the value of a variable, and the variable happens to be empty).
Finally, it is tempting to use the same file for both input and output:
sort < myfile > myfile Sort myfile in place? No!This does not work! The shell truncates myfile when opening it for output, and there won’t be any data there for sort to process when it runs.
Pipelines
It is also possible to redirect the output of one command into
the standard input of another running command instead of a file.
The construct that does this is called the pipe, notated
as |. A command line that includes two or more commands
connected with pipes is called a pipeline.
Pipes are very often used with the more
command, which works just like cat except that it prints
its output screen by screen, pausing for the user to type
SPACE (next screen), ENTER (next line), or other commands.
If you’re in a directory with a large number of files and you
want to see details about them, ls -l | more will give
you a detailed listing a screen at a time.
Pipelines can get very complex (see, for example,
the lsd function in
Chapter 4 or
the pipeline version of the C compiler driver in
Chapter 7);
they can also be combined with other I/O redirectors. To
see a sorted listing of the file fred a screen at a time,
type sort < fred | more.
To print it instead of viewing it
on your terminal, type sort < fred | lp.
Here’s a more complicated example.
The file /etc/passwd
stores information about users’ accounts on a Unix system.
Each line in the file contains a user’s login name, user ID number,
encrypted password, home directory, login shell, and other info.
The first field of each line is the login name;
fields are separated by colons (:).
A sample line might look like this:
billr:5Ae40BGR/tePk:284:93:Bill Rosenblatt:/home/billr:/bin/ksh
To get a sorted listing of all users on the system, type:
cut -d: -f1 < /etc/passwd | sort
(Actually, you can omit the <,
since cut accepts
input filename arguments.)
The cut command extracts the first field (-f1),
where fields are separated by colons
(-d:), from the input.
The entire pipeline prints a list that looks like this:
al billr bob chris dave
ed frank ...
If you want to send the list directly to the printer (instead of your screen), you can extend the pipeline like this:
cut -d: -f1 < /etc/passwd | sort | lp
Now you should see how I/O redirection and pipelines support the Unix building block philosophy. The notation is extremely terse and powerful. Just as important, the pipe concept eliminates the need for messy temporary files to store output of commands before it is fed into other commands.
For example, to do the same sort of thing as the above command line on other operating systems (assuming that equivalent utilities were available), you would need three commands. On Compaq’s OpenVMS system, they might look like this:
$cut [etc]passwd /d=":" /f=1 /out=temp1$sort temp1 /out=temp2$print temp2
After sufficient practice, you will find yourself routinely typing in powerful command pipelines that do in one line what in other operating systems would require several commands (and temporary files) to accomplish.
Background Jobs
Pipes are actually a special case of a more general feature: doing more than one thing at a time. any other commercial operating systems don’t have this capability, because of the rigid limits that they tend to impose upon users. Unix, on the other hand, was developed in a research lab and meant for internal use, so it does relatively little to impose limits on the resources available to users on a computer — as usual, leaning towards uncluttered simplicity rather than overcomplexity.
“Doing more than one thing at a time” means running more than one program at the same time. You do this when you invoke a pipeline; you can also do it by logging on to a Unix system as many times simultaneously as you wish. (If you try that on an IBM VM/CMS system, for example, you get an obnoxious “already logged in” message.)
The shell also lets you run more than one command at a time
during a single login session. Normally, when you type a command
and hit ENTER, the shell lets the command have control of your
terminal until it is done; you can’t run further commands until
the first one finishes. But if you want to run a command that does
not require user input and you want to do other things while the
command is running, put an ampersand (&) after the command.
This is called running the command in the background, and a command that runs in this way is called a background job; for contrast, a job run the normal way is called a foreground job. When you start a background job, you get your shell prompt back immediately, enabling you to enter other commands.
The most obvious use for background jobs is programs that can take a long time to run, such as sort or gunzip on large files. For example, assume you just got an enormous compressed file loaded into your directory from magnetic tape. Today, the gzip utility is the de-facto file compression utility. gzip often achieves 50% to 90% compression of its input files. The compressed files have names of the form filename.gz, where filename is the name of the original uncompressed file. Let’s say the file is gcc-3.0.1.tar.gz, which is a compressed archive file that contains well over 36 MB of source code files.
Type gunzip gcc-3.0.1.tar.gz &,
and the system starts a job in the
background that uncompresses the data “in place” and ends
up with the file gcc-3.0.1.tar.
Right after you type the command, you see a line like this:
[1] 4692
followed by your shell prompt, meaning that you can enter other commands. Those numbers give you ways of referring to your background job; Chapter 8 explains them in detail.
You can check on background jobs with the command jobs. For each background job, jobs prints a line similar to the above but with an indication of the job’s status:
[1] + Running gunzip gcc-3.0.1.tar.gz
When the job finishes, you see a message like this right before your shell prompt:
[1] + Done gunzip gcc-3.0.1.tar.gz
The message changes if your background job terminated with an error; again, see Chapter 8 for details.
Background I/O
Jobs you put in the background should not do I/O to your terminal. Just think about it for a moment and you’ll understand why.
By definition, a background job doesn’t have control over your terminal. Among other things, this means that only the foreground process (or, if none, the shell itself) is “listening” for input from your keyboard. If a background job needs keyboard input, it will often just sit there doing nothing until you do something about it (as described in Chapter 8).
If a background job produces screen output, the output will just appear on your screen. If you are running a job in the foreground that also produces output, the output from the two jobs will be randomly (and often annoyingly) interspersed.
If you want to run a job in the background that expects standard input or produces standard output, the obvious solution is to redirect it so that it comes from or goes to a file. The only exception is that some programs produce small, one-line messages (warnings, “done” messages, etc.); you may not mind if these are interspersed with whatever other output you are seeing at a given time.
For example, the diff utility examines two files, whose names are given as arguments, and prints a summary of their differences on the standard output. If the files are exactly the same, diff is silent. Usually, you invoke diff expecting to see a few lines that are different.
diff, like sort and gzip,
can take a long
time to run if the input files are very large. Suppose you have
two large files called warandpeace.html
and warandpeace.html.old.
The command diff warandpeace.html.old warandpeace.html
reveals that the author decided to change the name “Ivan”
to “Aleksandr” throughout the entire file — i.e., hundreds of
differences, resulting in large amounts of output.
If you type diff warandpeace.html.old warandpeace.html &,
then the system will spew lots and lots of output at you,
which it will be very difficult to stop — even with the techniques
explained in Chapter 7. However, if you type:
diff warandpeace.html.old warandpeace.html > wpdiff &
the differences will be saved in the file wpdiff for you to examine later.
Background Jobs and Priorities
Background jobs can save you a lot of thumb-twiddling time (or can help you diet by eliminating excuses to run to the candy machine). But remember that there is no free lunch; background jobs take resources that become unavailable to you or other users on your system. Just because you’re running several jobs at once doesn’t mean that they will run faster than they would if run sequentially — in fact, it’s usually worse.
Every job on the system is assigned a priority, a number that tells the operating system how much priority to give the job when it doles out resources (the higher the number, the lower the priority). Foreground commands that you enter from the shell usually have the same, standard priority. But background jobs, by default, have lower priority.[14] You’ll find out in Chapter 3 how you can override this priority assignment so that background jobs run at the same priority as foreground jobs.
If you’re on a large multiuser system, running lots of background jobs may eat up more than your fair share of the shared resources, and you should consider whether having your job run as fast as possible is really more important than being a good citizen.
On the other hand, if you have a dedicated workstation with a fast processor and loads of memory and disk, then you probably have cycles to spare and shouldn’t worry about it as much. The typical usage pattern on such systems largely obviates the need for background processes anyway: you can just start a job and then open another window and keep working.
nice
Speaking of good citizenship, there is also a shell command that lets you lower the priority of any job: the aptly-named nice. If you type the following, the command will run at a lower priority:
nice command
You can control just how much lower by giving nice a numerical argument; consult the man page for details.[15]
Special Characters and Quoting
The characters <, >,
|, and &
are four examples of special characters that have
particular meanings to the shell. The wildcards we saw
earlier in this chapter (*, ?,
and [...])
are also special characters.
Table 1-6 gives indications of the meanings of all special characters within shell command lines only. Other characters have special meanings in specific situations, such as the regular expressions and string-handling operators we’ll see in Chapter 3 and Chapter 4.
| Character | Meaning | See chapter |
~
| Home directory | 1 |
`
| Command substitution (archaic) | 4 |
#
| Comment | 4 |
$
| Variable expression | 3 |
&
| Background job | 1 |
*
| String wildcard | 1 |
(
| Start subshell | 8 |
)
| End subshell | 8 |
\
| Quote next character | 1 |
|
| Pipe | 1 |
[
| Start character-set wildcard | 1 |
]
| End character-set wildcard | 1 |
{
| Start code block | 7 |
}
| End code block | 7 |
;
| Shell command separator | 3 |
'
| Strong quote | 1 |
"
| Weak quote | 1 |
<
| Input redirect | 1 |
>
| Output redirect | 1 |
/
| Pathname directory separator | 1 |
?
| Single-character wildcard | 1 |
%
| Job name/number identifier | 8 |
Quoting
Sometimes you will want to use special characters literally, i.e., without their special meanings. This is called quoting. If you surround a string of characters with single quotes, you strip all characters within the quotes of any special meaning they might have.
The most obvious situation where you might need to quote a string is with the print command, which just takes its arguments and prints them to the standard output. What is the point of this? As you will see in later chapters, the shell does quite a bit of processing on command lines — most of which involves some of the special characters listed in Table 1-6. print is a way of making the result of that processing available on the standard output.
But what if we wanted to print the string,
2 * 3 > 5 is a valid inequality? Suppose you typed this:
print 2 * 3 > 5 is a valid inequality.
You would get your shell prompt back, as if nothing happened!
But then there would be a new
file, with the name 5, containing “2”, the names of all
files in your current directory, and then the string 3 is a valid inequality. Make sure you understand why.[16]
However, if you type:
print '2 * 3 > 5 is a valid inequality.'
the result is the string, taken literally. You needn’t quote the entire line, just the portion containing special characters (or characters you think might be special, if you just want to be sure):
print '2 * 3 > 5' is a valid inequality.
This has exactly the same result.
Notice that
Table 1-6
lists double quotes (") as weak quotes.
A string in double quotes is subjected to some of the steps
the shell takes to process command lines, but not all.
(In other words, it treats only some special characters
as special.) You’ll
see in later chapters why double quotes are sometimes
preferable; Chapter 7 contains the most comprehensive explanation
of the shell’s rules for quoting and other aspects of command-line processing.
For now, though, you should stick to single quotes.
Backslash-Escaping
Another way to change the meaning of a character is to precede
it with a backslash (\). This is called backslash-escaping
the character. In most cases, when you backslash-escape
a character, you quote it. For example:
print 2 \* 3 \> 5 is a valid inequality.
produces the same results as if you surrounded the string
with single quotes. To use a literal backslash, just
surround it with quotes ('\')
or, even better, backslash-escape
it (\\).
Here is a more practical example of quoting special characters. A few Unix commands take arguments that often include wildcard characters, which need to be escaped so the shell doesn’t process them first. The most common such command is find, which searches for files throughout entire directory trees.
To use find, you supply the root of the tree you want to
search and arguments that
describe the characteristics of the file(s) you want to find.
For example, the command
find . -name
string
-print
searches the directory
tree whose root is your current directory for files whose names
match the string, and prints their names. (Other arguments allow you to search
by the file’s size, owner, permissions, date of last access, etc.)
You can use wildcards in the string, but you must quote them,
so that the find command itself can match them against names
of files in each directory it searches. The command
find . -name '*.c' will
match all files whose names end in .c anywhere in
your current directory, subdirectories, sub-subdirectories, etc.
Quoting Quotation Marks
You can also use a backslash to include double quotes within a string. For example:
print \"2 \* 3 \> 5\" is a valid inequality.
produces the following output:
"2 * 3 > 5" is a valid inequality.
Within a double-quoted string, only the double quotes need to be escaped:
$ print "\"2 * 3 > 5\" is a valid inequality."
"2 * 3 > 5" is a valid inequality.
However, this won’t work with single quotes inside
quoted expressions.
For example,
print 'Bob\'s hair is brown' will not
give you Bob's hair is brown. You can get around this
limitation in various ways. First, try eliminating the quotes:
print Bob\'s hair is brown
If no other characters are special (as is the case here), this works. Otherwise, you can use the following command:
print 'Bob'\''s hair is brown'
That is, '\'' (i.e., single quote, backslash, single quote,
single quote) acts like a single quote within a quoted
string. Why? The first ' in
'\''
ends the quoted string we started
with 'Bob,
the \' inserts a literal single quote,
and the next '
starts another quoted string that ends with the word
“brown”.
If you understand this,
you will have no trouble resolving the other bewildering
issues that arise from the shell’s often cryptic syntax.
A somewhat more legible mechanism, specific to ksh93,
is available for cases where you need to quote single quotes.
This is the shell’s extended quoting mechanism: $'...'.
This is known in ksh documentation as
ANSI C quoting, since the rules closely resemble those of
ANSI/ISO Standard C. The full details are provided in Chapter 7.
Here is how to use ANSI C quoting for the previous example:
$ print $'Bob\'s hair is brown'
Bob's hair is brownContinuing Lines
A related issue is how to continue the text of a command beyond a single line on your terminal or workstation window. The answer is conceptually simple: just quote the ENTER key. After all, ENTER is really just another character.
You can do this in two ways: by ending a line with a backslash or by not closing a quote mark (i.e., by including ENTER in a quoted string). If you use the backslash, there must be nothing between it and the end of the line — not even spaces or TABs.
Whether you use a backslash or a single quote, you are telling
the shell to ignore the special meaning of the ENTER character.
After you press ENTER, the shell understands that you haven’t
finished your command line (i.e., since you haven’t typed a
“real” ENTER), so it responds with a secondary
prompt, which is > by default, and waits for you to
finish the line. You can continue a line as many times as you wish.
For example, if you want the shell to print the first sentence of Thomas Hardy’s The Return of the Native, you can type this:
$print A Saturday afternoon in November was approaching the \>time of twilight, and the vast tract of unenclosed wild known \>as Egdon Heath embrowned itself moment by moment.
Or you can do it this way:
$print 'A Saturday afternoon in November was approaching the>time of twilight, and the vast tract of unenclosed wild known>as Egdon Heath embrowned itself moment by moment.'
There is a difference between the two methods. The first prints the sentence as one long line. The second preserves the embedded newlines. Try both, and you’ll see the difference.
Control Keys
Control keys — those that you type by holding down the CONTROL (or CTRL) key and hitting another key — are another type of special character. These normally don’t print anything on your screen, but the operating system interprets a few of them as special commands. You already know one of them: ENTER is actually the same as CTRL-M (try it and see). You have probably also used the BACKSPACE or DEL key to erase typos on your command line.
Actually, many control keys have functions that don’t really concern you — yet you should know about them for future reference and in case you type them by accident.
Perhaps the most difficult thing about control keys is that they can differ from system to system. The usual arrangement is shown in Table 1-7, which lists the control keys that all major modern versions of Unix support. Note that CTRL-\ and CTRL-| (control-backslash and control-pipe) are the same character notated two different ways; the same is true of DEL and CTRL-?.
You can use the stty(1) command to find out what your settings
are and change them if you wish; see Chapter 8 for details.
On modern Unix systems (including GNU/Linux), use stty -a to
see your control-key settings:
$ stty -a
speed 38400 baud; rows 24; columns 80; line = 0;
intr = ^C; quit = ^\; erase = ^H; kill = ^U; eof = ^D; eol = <undef>;
eol2 = <undef>; start = ^Q; stop = ^S; susp = ^Z; rprnt = ^R; werase = ^W;
lnext = ^V; flush = ^O; min = 1; time = 0;
...
The ^X notation stands for CTRL-X.
| Control key | stty name | Function description |
| CTRL-C |
intr
|
Stop current command. |
| CTRL-D |
eof
|
End of input. |
| CTRL-\ or CTRL-| |
quit
|
Stop current command, if CTRL-C doesn’t work. |
| CTRL-S |
stop
|
Halt output to screen. |
| CTRL-Q |
start
|
Restart output to screen. |
| BACKSPACE or CTRL-H |
erase
|
Erase last character. This is the most common setting. |
| DEL or CTRL-? |
erase
|
Erase last character. This is a common alternative setting.
for the |
| CTRL-U |
kill
|
Erase entire command line. |
| CTRL-Z |
susp
|
Suspend current command (see Chapter 8). |
| CTRL-R |
rprnt
|
Reprint the characters entered so far. |
The control key you will probably use most often is CTRL-C, sometimes called the interrupt key. This stops — or tries to stop — the command that is currently running. You will want to use this when you enter a command and find that it’s taking too long, when you gave it the wrong arguments by mistake, when you change your mind about wanting to run it, and so on.
Sometimes CTRL-C doesn’t work; in that case, if you really want to stop a job, try CTRL-\. But don’t just type CTRL-\; always try CTRL-C first! Chapter 8 explains why in detail. For now, suffice it to say that CTRL-C gives the running job more of a chance to clean up before exiting, so that files and other resources are not left in funny states.
We’ve already seen an example of CTRL-D.
When you are running a command that accepts standard input from
your keyboard, CTRL-D (as the first character on the line) tells the process that your input
is finished — as if the process were reading a file and it reached the
end of the file.
mail is a utility in which this happens often.
When you are typing in a message, you end by
typing CTRL-D. This tells mail that your message is complete
and ready to be sent. Most utilities that accept standard
input understand CTRL-D as the end-of-input character, though many such
programs accept commands like q, quit, exit, etc.
The shell itself understands CTRL-D as the end-of-input character:
as we saw earlier in this chapter, you can normally end a login session
by typing CTRL-D at the shell prompt. You are just telling the shell
that its command input is finished.
CTRL-S and CTRL-Q are called flow-control characters. They represent an antiquated way of stopping and restarting the flow of output from one device to another (e.g., from the computer to your terminal) that was useful when the speed of such output was low. They are rather obsolete in these days of high-speed local networks and dialup lines. In fact, under the latter conditions, CTRL-S and CTRL-Q are basically a nuisance. The only thing you really need to know about them is that if your screen output becomes “stuck,” then you may have hit CTRL-S by accident. Type CTRL-Q to restart the output; any keys you may have hit in between will then take effect.
The final group of control characters gives you rudimentary ways to edit your command line. BACKSPACE or CTRL-H acts as a backspace key (in fact, some systems use the DEL or CTRL-? keys as “erase” instead of BACKSPACE); CTRL-U erases the entire line and lets you start over. Again, most of these are outmoded.[17] Instead of using these, go to the next chapter and read about the Korn shell’s editing modes, which are among its most exciting features.
[2] With a few extremely minor exceptions. See Chapter 10 for the only important one.
[3]
You can set up your shell so that it doesn’t accept CTRL-D, i.e.,
it requires you to type exit to end your session.
We recommend this, because CTRL-D is too easy to type by accident;
see the section on options in Chapter 3.
[4] Although we assume that there are few people still using real serial terminals, modern windowing systems provide shell access through a terminal emulator. Thus, at least when it comes to interactive shell use, the term “terminal” applies equally well to a windowing environment.
[5] Starting with ksh93i.
[6]
All of the help options send their output to standard error (which is
described later in this chapter).
This means you have to use shell facilities that we don’t cover
until Chapter 7
to catch their output. For example,
cd --man 2>&1 | more
runs the online help through the pager program more.
[7]
Most introductory Unix tutorials say that root has the
name /.
We stand by this alternative explanation because it is more
logically consistent.
[8] If you have a system where the Korn shell is installed as /bin/sh, this example won’t work.
[9] “Important new features” are those that the marketing department wants, whether or not the customers actually need them.
[10]
MS-DOS, Windows, and OpenVMS users should note that there is
nothing special about the dot (.) in Unix filenames (aside from the leading dot, which
“hides” the file); it’s just another character. For example,
ls * lists all files in the current directory; you don’t
need *.* as you do on other systems.
[11] Specifically, ranges depend on the character encoding scheme your computer uses. The vast majority use ASCII, but IBM mainframes use EBCDIC. (Actually, on EBCDIC systems, not even the upper- and lowercase letters make a contiguous range.)
[12] This is different from the C shell’s wildcard mechanism, which prints an error message and doesn’t execute the command at all.
[13]
If a particular Unix utility doesn’t accept standard input when
you leave out the filename argument, try using - as the argument.
This is a common, although not universal, convention.
[14] This feature was borrowed from the C shell; it is not present in most Bourne shells.
[15]
If you are a system administrator logged in as root, you can also use nice to raise a job’s priority.
[16] This should also teach you something about the flexibility of placing I/O redirectors anywhere on the command line — even in places where they don’t seem to make sense.
[17] Why are so many outmoded control keys still in use? They have nothing to do with the shell per se; instead, they are recognized by the tty driver, an old and hoary part of the operating system’s lower depths that controls input and output to/from your terminal. It is, in fact, the tty driver that understands CTRL-D and signals end-of-input to programs reading from the terminal, not the programs themselves.
Get Learning the Korn Shell, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

