Chapter 4. MongoDB
When it comes to NoSQL databases, it is hard to beat the ease of use offered by MongoDB. Not only is it well documented and supported by a large and helpful community, but it is friendly to developers coming from an SQL backgroundâmany queries and a great deal of relational thinking can be directly applied from SQL to MongoDBâmaking it an especially attractive system for newcomers to the NoSQL world.
In relational databases, a single entity is stored in a row with a series of columns. Because entities are defined in a strict schema, every row will have the same columns. Working with entities involves comparing columns with very little overhead: all of the data is the same by design. In MongoDB there is no strictly defined schema and there are no rows containing columnsâinstead, every entity is stored in a document with any number of fields.
Documents provide a lot of power; you can store much more related information about each entity inside the document, even putting lists of documents inside other documents. Instead of making multiple queries to the database to get a complete set of information (as you would have to do with an SQL database), you can load entire datasets in a single operation.
Accessing Data
Not only is MongoDB friendly to developers coming from an SQL background, but its website goes out of its way to show how many SQL statements can be converted to MongoDB queries. In any database system, the end goal is always writing dataâusually, persisting it to a diskâand reading it back out again.
Example 4-1 demonstrates a simple session in
MongoDB. No special setup is required at any step of the wayâall that was
needed here was to install MongoDB and run it, then connect using the
mongo client. Once connected to
MongoDB, I immediately started using a database that I called newdb, but I didnât have to do anything to set
it up: all I needed to do was to start writing data.
>usenewdb;switchedtodbnewdb>book={author:'Jamie Munro',title:'20 Recipes for Programming PhoneGap',published:newDate('04/03/2012')};{"author":"Jamie Munro","title":"20 Recipes for Programming PhoneGap","published":ISODate("2012-04-03T07:00:00Z")}>db.books.insert(book);>db.books.find();{"_id":ObjectId("5063d1d89e302eaf24b259a0"),"author":"Jamie Munro","title":"20 Recipes for Programming PhoneGap","published":ISODate("2012-04-03T07:00:00Z")}
I created a variable named book
to store information about a programming book Iâve been reading, including
the author, title, and publication date. Then I created a books collection
and inserted it using the db.books.insert
command. Along the way I didnât stop once to define a schema; at
no point do I tell MongoDB what a book is, what data it should contain, or
even what a collection of books is. MongoDB takes care of creating
documents, maintaining lists, and evenâas we will discuss later in this
chapterâindexing and constraints.
Writing
As youâve seen, writing data to MongoDB is extremely free form. You have a lot of flexibility because each record stored in the database is basically a JSON document and therefore parsable and usable in both a free and structured manner. You are not bound to a rigid set of columns per table as you would be in a traditional RDBMS. Building upon Example 4-1, you can add an additional book to the database without being bound to follow the structure that came before.
When I added a book in Example 4-2, I included a
new field called keywords that was
not present in the book added in Example 4-1. That
doesnât matter because when I later queried the list of books, both
books were returned even though they didnât have identical field names.
MongoDB happily fetches â20 Recipes for Programming PhoneGapâ along with
â50 Tips and Tricks for MongoDB Developersâ even though they arenât
structured exactly the same.
>book={title:'50 Tips and Tricks for MongoDB Developers',author:'Kristina Chodorow',published:newDate('05/06/2011'),keywords:['design','implementation','optimization']};{"title":"50 Tips and Tricks for MongoDB Developers","author":"Kristina Chodorow","published":ISODate("2011-05-06T07:00:00Z"),"keywords":["design","implementation","optimization"]}>db.books.insert(book);>db.books.find();{"_id":ObjectId("5063d1d89e302eaf24b259a0"),"author":"Jamie Munro","title":"20 Recipes for Programming PhoneGap","published":ISODate("2012-04-03T07:00:00Z")}{"_id":ObjectId("5063d6909e302eaf24b259a1"),"title":"50 Tips and Tricks for MongoDB Developers","author":"Kristina Chodorow","published":ISODate("2011-05-06T07:00:00Z"),"keywords":["design","implementation","optimization"]}
As you can well imagine, there is a lot of power in being able to insert records in such a free form manner. When you are building an application against MongoDB, your program code is in control of the structure of the data you will be using. Any time you need to add a new field, record type, or even database, you will be able to do so by doing nothing more than declaring it and using it. But this flexibility and power comes with a management underside: your application will need to be able to handle old data formats as well as new ones after your application has grown for a period of time. That means you must either be very guarded about making changes at all or your application must be crafted to be resilient to data changes.
The simple scenario demonstrated in Example 4-2
is a perfect example of this. Youâve just added a keywords field to your book documentsâevery
new book entered into the system from here on out will contain a
keywords field that is exposed to a library terminal somewhere down the
line. What happens when that terminal tries to read a book that is
missing the keywords field? Hopefully
the developer who built the interface thought of that and is able to
display an empty listâor a special messageâwhen no keywords are
found.
Warning
You should always build your application logic to check for the presence of database fields before using them, otherwise you could end up with a broken application even though your database is behaving exactly as expected.
If you want to make sure all your documents have a field called
keywords, you could trigger an update
across the entire collection, as shown in Example 4-3.
>db.books.update({},{$set:{"keywords":[]}},false,true);
Example 4-3 demonstrates the use of MongoDBâs update command with all four of its parameters:
- Search criteria
This parameter contains all of the search criteria that MongoDB should use to determine which records need to be modified. In this case, no criteria is given, meaning any record is a fair match for this function.
- Update object
During normal operation, this parameter will contain an entire record just like the
insertcommand in Examples 4-1 and 4-2. When presented with an object, MongoDB will save its contents over any document it found matching the search criteria from the first parameter. MongoDB also supports a number of special functions including the$setfunction shown here, which allows manipulation of part of a document, leaving the rest of the data intact.- Upsert
In most cases you would want to update an existing document using the
updatecommand, but there are many times when you will want to update a piece of information or create a new document if that information does not already exist in the database. The upsert pattern means âupdate if possible, insert otherwise.â In Example 4-3, the goal is to set a keyword field for all of the documents but not create any new records; therefore, upsert is set tofalse.- Multiple update
MongoDB expects you to update one record at a time, so when you need to update more than one you need to set this variable to
true; otherwise, the database will stop updating after it operates on the first match. This is a useful safety valve to prevent you from accidentally trashing an entire collection because of a poorly thought out wildcard search pattern.
Example 4-4 demonstrates another useful
operator: the $push command. This
command allows you to add a new item to the end of an array without
modifying anything else in your document. As shown here, the keyword
developer is added to the â50 Tips
and Tricks for MongoDB Developersâ book.
>db.books.update({author:"Kristina Chodorow"},{"$push":{"keywords":"developer"}});>db.books.find();{"_id":ObjectId("5063d1d89e302eaf24b259a0"),"author":"Jamie Munro","title":"20 Recipes for Programming PhoneGap","published":ISODate("2012-04-03T07:00:00Z")}{"_id":ObjectId("5063d6909e302eaf24b259a1"),"author":"Kristina Chodorow","keywords":["design","implementation","optimization","developer"],"published":ISODate("2011-05-06T07:00:00Z"),"title":"50 Tips and Tricks for MongoDB Developers"}
Querying
Querying in MongoDB is analogous to SELECT in SQL. You can not only query across
fields in collections of documents, you can also use custom JavaScript
functions to perform more complicated filtration on your result
sets.
The earliest example in this chapter, Example 4-1, contains an extremely basic query:
db.books.find();
The find command with no
parameters instructs MongoDB to find documents in the books collection
without applying conditions to the search. When there are no conditions
to apply to the search, MongoDB responds by returning all of the
documents in the collection. In this sense, the find command with no parameters is the same as
saying âfind allâ to the database.
If we were to express this in SQL, the query would look like this:
SELECT*FROMbooks;
>db.books.find({author:"Jamie Munro"});{"_id":ObjectId("5063d1d89e302eaf24b259a0"),"author":"Jamie Munro","keywords":[],"published":ISODate("2012-04-03T07:00:00Z"),"title":"20 Recipes for Programming PhoneGap"}
Example 4-5 uses the find command again, but this time a specific
author is specified in the criteria. This time MongoDB will search
through the books collection and return all of the records whose author
field matches the author field in the find command. If we were to express this in
SQL, the query would look like this:
SELECT*FROMbooksWHEREauthor=âJamieMunroâ;
Imagine for a moment that the average document in your collection contained dozens, or even hundreds, of rows. During regular use you would not always want to get every field from the database, especially if youâre interested in only one or two bits of information at a time.
The find command in Example 4-6 has two parameters: the search criteria (empty
in this case) and a desired field map. Because no arguments are supplied
in the search criteria, MongoDB will once again return all of the
documents in the books collection. The desired field map includes the
title field, and will cause MongoDB
to return only the title field.
>db.books.find({},{title:1});{"_id":ObjectId("5063d6909e302eaf24b259a1"),"title":"50 Tips and Tricks for MongoDB Developers"}{"_id":ObjectId("5063d1d89e302eaf24b259a0"),"title":"20 Recipes for Programming PhoneGap"}
Wait a minute! Why is the _id
field being returned? MongoDB assumes you will need the recordâs ID
field in most cases, else you would not be able to uniquely name a
document from your application code. If you wanted to show only the
titles without the _id field, you
could explicitly hide the _id field
like this, using 0 to mean false:
db.books.find({},{title:1,_id:0});
The find function as shown in
Example 4-6 is analogous to this SQL query:
SELECT_id,titleFROMbooks;
Indexes
Itâs easy to be fooled into thinking your code is fast when youâre working on small datasets and querying against databases running on your own computer. Performance can suffer tremendously once your code hits a production workload and needs to serve a growing dataset to a large number of users. Although MongoDB is smart about where it looks for data, unless you set up indexes to keep search fields in memory, your database will be doing a lot more work than it needs to.
While going deeply into detail on the explain command would (and does!) fill an
entire book, the first piece of information you should be looking for is
in the cursor field. MongoDB uses
either a BasicCursor or BtreeCursor when scanning collections of
documents; for a heavily-used query, you want to avoid using a
BasicCursor because it scans through every document in the collection to
find a result.
The books collection queries in Example 4-7 is
tiny, having only two records. But because a BasicCursor is used to
perform the search, MongoDB has to examine both records before it can
return a result set. You can see the number of scanned objects in the
nscannedObjects field from the
explain functionâs output.
>db.books.find({author:"Jamie Munro"}).explain();{"cursor":"BasicCursor","nscanned":2,"nscannedObjects":2,"n":1,"millis":0,"nYields":0,"nChunkSkips":0,"isMultiKey":false,"indexOnly":false,"indexBounds":{}}
You use the ensureIndex
function to add an index to your collection. Indexed fields are tracked
in memory and can be retrieved much more rapidly by MongoDB. More
importantly, they act as a filter on queried data; the database only
needs to look at records that it knows match your search criteria based
upon its knowledge of the table as held in the indexes.
Notice how nscannedObjects
dropped to just 1 in Example 4-8 after an index was added to the author field of
the books collection. Because the author is now stored in memory and
known to the database, MongoDB knows it only needs to look more closely
at a single document. If you try to search for an author who doesnât
exist, MongoDB will not have to check any records at all.
>db.books.ensureIndex({author:1});>db.books.find({author:"Jamie Munro"}).explain();{"cursor":"BtreeCursor author_1","nscanned":1,"nscannedObjects":1,"n":1,"millis":0,"nYields":0,"nChunkSkips":0,"isMultiKey":false,"indexOnly":false,"indexBounds":{"author":[["Jamie Munro","Jamie Munro"]]}}
It can take some time to make sure you have all of the right indexes set up in your database. If done properly, it can mean the difference between queries that take minutes versus queries that take seconds or less.
MapReduce
MapReduce is used to batch process huge amounts of data often
across clusters of database servers. If you were to compare MongoDB to a
traditional SQL-based server, MapReduce would fit in the space where you
would normally use GROUP BY to
collect aggregate results.
A MapReduce operation involves two phases: the map phase, which plucks out the relevant data into key/value pairs for aggregation, and the reduce phase, which collects all of the keys and performs math on their values. Take a counting operation for example: if you wanted to know how many books each author in the books collection has written, you would need to go through each document and count the number of times each author appeared in the collection.
Since there have been only two records in the books collection so far, the first thing that needs to happen in Example 4-9 is the creation of more data, so thatâs what happens.
>db.books.insert({"author":"Kristina Chodorow","title":"Scaling MongoDB",..."published":newDate("03/02/2011")});>db.books.insert({"author":"Stoyan Stefanov","title":"JavaScript Patterns",..."published":newDate("09/28/2010")});>db.books.insert({"author":"Stoyan Stefanov",..."title":"JavaScript for PHP Developers",..."published":newDate("10/22/2012")});>db.books.insert({"author":"Stoyan Stefanov","title":"Web Performance Daybook",..."published":newDate("06/27/2012")});>db.books.insert({"author":"Jamie Munro",..."title":"20 Recipes for Programming MVC 3",..."published":newDate("10/11/2011")});>map=function(){emit(this.author,1);};function(){emit(this.author,1);}>reduce=function(key,values){...vartotal=0;...values.forEach(function(value){...total+=value;...});...returntotal;...}function(key,values){vartotal=0;values.forEach(function(value){total+=value;});returntotal;}>db.books.mapReduce(map,reduce,{out:"bookoutput"});{"result":"bookoutput","timeMillis":3,"counts":{"input":7,"emit":7,"reduce":3,"output":3},"ok":1,}>db.bookoutput.find();{"_id":"Jamie Munro","value":2}{"_id":"Kristina Chodorow","value":2}{"_id":"Stoyan Stefanov","value":3}
With some data in the collection, create a map function that will emit an author name and
the number 1 when given a document. emit is a MongoDB helper function that groups
objects by keys; in this case, the key is the author name found in each
document. I used the value 1 for convenience: each time MongoDB reads a
book object, it will count as 1 book credit toward that author. This
could be simplified to emit an empty value, but itâs being left this way
for convenience because most of the MapReduce functions you create will
start with this format and become more complex.
Once all of the keys have been emitted, MongoDB collects the
results and reduces them; so while any particular key may have been
found multiple times if any author wrote more than one book, the final
result should contain only one valueâthe sum of written booksâper
author. The reduce function in Example 4-9 adds all of the values found for each author and
returns a total count of each books.
When the mapReduce function is
performed on the books collection, it is given three parameters: the
user-defined map function, the user-defined reduce function, and the
name of a new collection to contain the results. After the mapReduce function executes, it will save the
author book counts into a new collection called bookoutput, which can then be queried just
like any other collection. Example 4-9 concludes by
querying it to reveal the number of books next to each authorâs
name.
Working with Node.js
The primary MongoDB driver supported for Node.js is the Node MongoDB Native Project, a pure-JavaScript driver that provides asynchronous I/O to MongoDB from Node. Because the driver can save your JavaScript objects directly into MongoDB, by all rights you could build out the full application with it.
The Mongoose project extends the native drivers by providing a means to define the database schema. If this seems to go against the NoSQL âschema-lessâ philosophy, donât worry. Changes to the JavaScript schema definitions do not require special processing by MongoDBâthe schema only exists to make your life easier as a developer trying to make a consistent application.
Mongoose also provides a powerful set of middleware designed to ease the process of working with serial and parallel requests in Nodeâs asynchronous environment:
npminstallmongoose
Concurrent Access
Picture this: Adam and Greg access the same document and begin making changes. Since they are each working on their own computers, their changes are not being saved directly back to the database and refreshed in each otherâs workâthey can be said to be editing in âofflineâ mode. Adam finishes his work first and saves his complete changes back to the database. At some later point, Greg finishes his own edits and saves those into the database. Because Greg started working on the document before Adamâs changes went into effect, his edits do not include Adamâs; so when he saves his work back into the database, Adamâs work is effectively erased, as demonstrated in Figure 4-1.
What to do? While most of the examples in this book involve write-only transactions (meaning we will write but never modify certain data), there will inevitably be occasions where you will need to work on a shared document at the same time as someone else and want to prevent your users from losing their changes if they were unfortunate enough to post first.
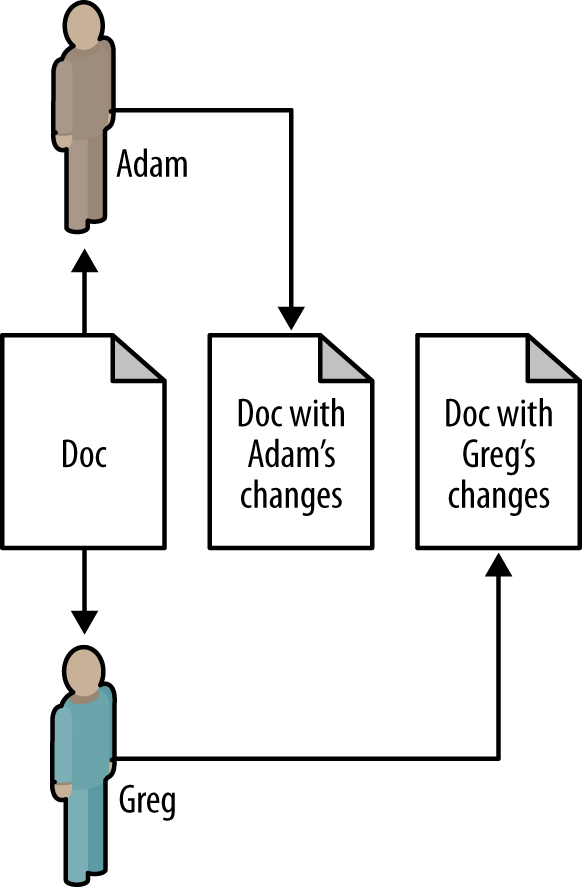
One way to accomplish this is by assigning a signature to every record and updating that signature every time you write to the database. If updating an existing document, only update the document whose ID and signature both match the values observed when the document was first read. This way, when two users try to save the same data, the first userâs update will cause the signature to change and the second userâs update will fail because the signature does not match.
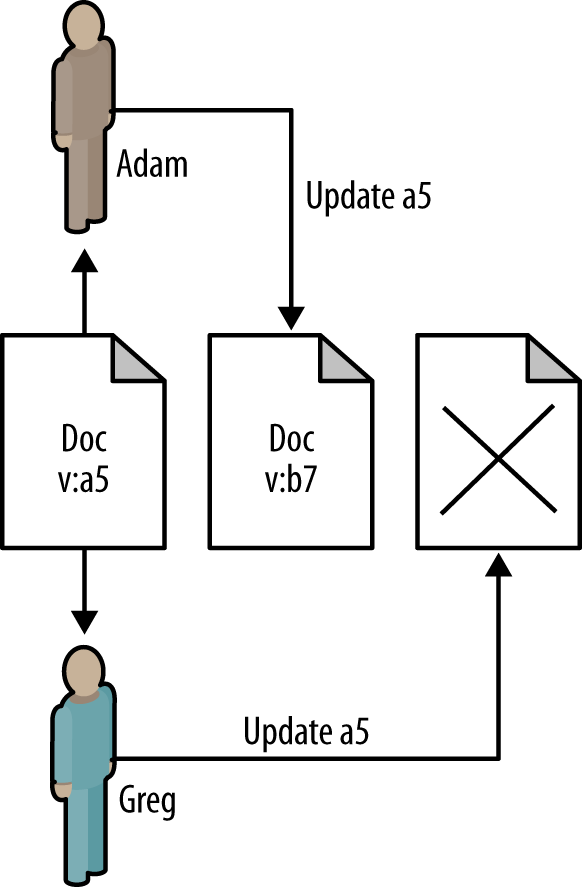
In Figure 4-2, users Greg and Adam both begin editing the same document, but when Adam saves his changes he updates the documentâs version number from a5 to b7. Now, when Greg saves his changes, he specifies that he is updating version a5, which no longer exists in the database; instead of writing his changes, the update fails. From here, Greg can update his copy of the document using the changes submitted by Adam, or the software he is using can do it intelligently in the background and resubmit on his behalf.
MongoDB includes a function called findAndModify, which handles searching and
updating in a single function. This adds an extra layer of security
because it ensures the update happens immediately when a record is found,
rather than adding round-trip time to process the record on the client
side and save it back to the database, during which time someone else
might change the record and cause the concurrent access problem described
earlier.
Example 4-10 demonstrates how an article can be
created and updated using the findAndModify method. Notice how the first time
findAndModify is executed, it returns
the contents of the article without the updated revision numberâthat is,
it indicates the revision is a5 instead
of the new value b7 provided in the
command. If you wanted to display the new, updated version of the article,
you would include the keyword new in
the findAndModify command. In either
case, when the find command is later
issued, the new revision value is shown. Next, when the findAndModify command is rerun, Mongo is unable
to find the record because the revision version is no longer a5, therefore
it returns null.
>db.articles.save({...title:"Jolly Roger",...published:"September 12, 2007",...description:"A riveting tale of suspense and drama.",...revision:"a5"...});>db.articles.find();{"_id":ObjectId("505a9b4fd5f42989fe6d8015"),"title":"Jolly Roger","published":"September 12, 2007","description":"A riveting tale of suspense and drama.","revision":"a5"}>db.articles.findAndModify({...query:{"_id":ObjectId("505a9b4fd5f42989fe6d8015"),revision:"a5"},...update:{$set:{revision:"b7"}}...});{"_id":ObjectId("505a9b4fd5f42989fe6d8015"),"title":"Jolly Roger","published":"September 12, 2007","description":"A riveting tale of suspense and drama.","revision":"a5"}>db.articles.find();{"_id":ObjectId("505a9b4fd5f42989fe6d8015"),"title":"Jolly Roger","published":"September 12, 2007","description":"A riveting tale of suspense and drama.","revision":"b7"}>db.articles.findAndModify({...query:{"_id":ObjectId("505a9b4fd5f42989fe6d8015"),revision:"a5"},...update:{$set:{revision:"90jasv"}}...});null>db.articles.find();{"_id":ObjectId("505a9b4fd5f42989fe6d8015"),"title":"Jolly Roger","published":"September 12, 2007","description":"A riveting tale of suspense and drama.","revision":"b7"}>
Get Building Node Applications with MongoDB and Backbone now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

