One of the things you’ll hear over and over from switch vendors is how fast their switch is, or how fast the fabric is, or how much backplane capacity it has. But what does all that mean?
Note
This book is not intended to explain every possible detail of switch fabrics, but rather to help you understand what the term fabric speed means in a general sense. Entire books could be written on this topic, but my goal here is to help you understand the confusing and often misleading numbers that many vendors include in their switch specification sheets.
In a top-of-rack switch, the fabric is the interconnections between all the interfaces. The term backplane in this case is pretty much synonymous with fabric (though probably inaccurate). On a chassis switch, the terms can be thought of a bit differently.
On a chassis switch, each module may have a fabric, and interfaces within a module may switch between each other while staying local to the blade. When a packet sourced on one blade must travel to another blade, though, the packet needs a path between the blades. The connections between the blades are often called the backplane, although really, that term is more about the hardware connecting the modules to each other. Semantics aside, what you need to know is that there is a master fabric connecting all these modules together in a chassis switch.
In modern chassis switches, like the Arista 7500 and Cisco Nexus 7000, the backplane fabric resides in hot swappable modules in the back of the chassis. In older switches, like the Cisco 6509, they used to consume slots in the front of the switch (at the expense of other useful modules). Later, Cisco incorporated the fabric modules into the supervisors so that more slots could be used in the front for interfaces.
There are many ways in which modules can connect to the backplane fabric. There may be ASICs on the modules that allow packets to flow intramodule without intervention from the fabric modules. Or, the fabric modules may interconnect every port in every module. How the modules are constructed, and how they connect to the backplane, both determine how fast the backplane fabric is. Really, though, many vendors play games with numbers and try to hide what’s really going on. Let’s take a look at why.
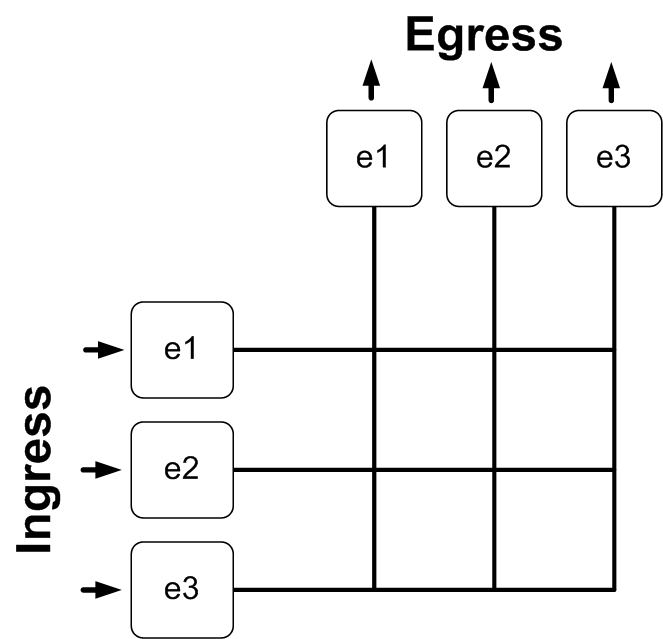
Let’s look at our simple three-port 10 Gbps switch, shown in Figure 4-1. In this switch, the fabric is simple, and non-blocking. Non-blocking means that each port is capable of sending and receiving traffic at wire speed (the maximum speed of the interface) to and from any other port. A non-blocking switch is capable of doing this on all ports at once. Remember, on these fabric drawings, that the ingress is on the left and the egress is on the top. That means that when you see interface e1 in two places that it’s the same interface. It exists in two places to show how packets come in and leave through the fabric.
Now imagine that our simple switch used ASICs to control the flow of packets between ports. There is one ASIC on the ingress, and one on the egress. The kicker here, though, is that each ASIC is only capable of forwarding 10 Gbps at a time. This design is shown in Figure 4-2.
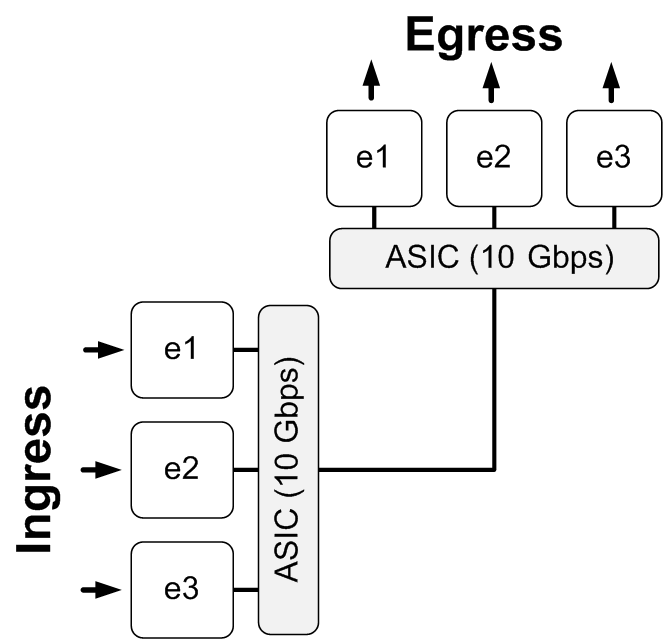
All of a sudden, with the addition of the 10 Gbps ASICs, our switch has lost our non-blocking status (assuming each port is 10 Gbps). Though each interface forwards bits to its connected device at 10 Gbps, should more than two ports be used at the same time, their maximum combined transmit and receive can only be 10 Gbps. Think that sounds bad? Well, it is, assuming you need a non-blocking switch. The truth is, very few networks require real non-blocking architectures. Most eight-port gigabit switches found in the home are blocking architectures just like this. But how often do you really need to push 100% bandwidth through every port in your small office/home office (SOHO) switch? Probably never. And guess what? Building switches this way is inexpensive, which is a plus in the SOHO switch market.
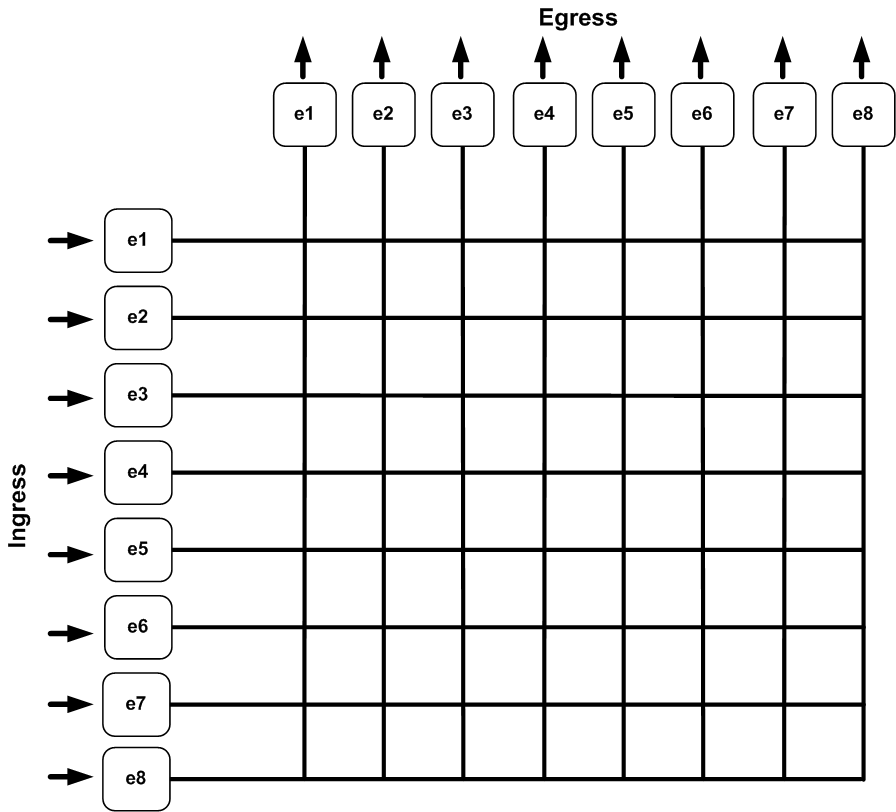
Let’s look at a bigger switch. In Figure 4-3, I’ve built an eight-port 10 Gbps switch. This switch is non-blocking, as evidenced by the fact that each interface has a possible full-speed connection to any other interface.
How might this switch look if we used oversubscription to lower costs? If we used the same 10 Gbps ASICs, each controlling four 10 Gbps interfaces, it might look like the drawing in Figure 4-4.
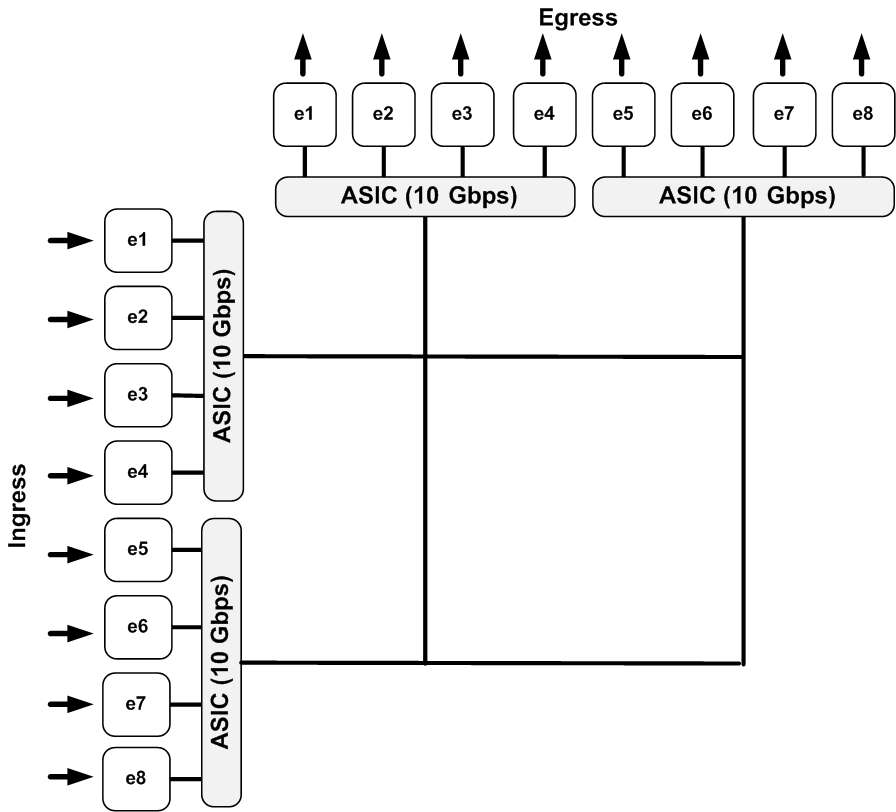
If you think stuff like this couldn’t happen in a modern switch, think again. The Netgear SOHO GS108T switch advertises that it has “eight 10/100/1000 Mbps ports, capable of powering 2000 Mbps of data throughput.” Even the big iron is commonly oversubscribed. The Cisco Nexus N7K-M132XP-12L module, shown in Figure 4-5, sports 32 10 Gbps ports, but each group of four ports only supports an aggregate bandwidth of 10 Gbps. This is illustrated by the fact that one out of each of the four ports can be placed into dedicated mode, in which that port is guaranteed the full 10 Gbps. When put in this mode, the three other ports attached to the ASIC are disabled.

This is not a knock on Netgear or Cisco. In fact, in this case I applaud them for being up front about the product’s capabilities, and in the case of the Cisco blade, providing the ability to dedicate ports. On a server connection, I’m perfectly OK oversubscribing a 10 Gbps port because most servers are incapable of sending 10 Gbps anyway. On an inter-switch link, though, I’d like to be able to dedicate a 10 Gbps port. My point is that this oversubscription is very common, even in high-dollar data center switches.
What if we could get a single super-ASIC that could control all of the ports? Such a switch might look like the one I’ve drawn in Figure 4-6. In this switch, each port still has full 10 Gbps connectivity to any other port on the switch, but there is no oversubscription. This is accomplished by having what I’ll call a next-generation ASIC that can handle the high bandwidth requirements of a non-blocking 10 Gbps switch.
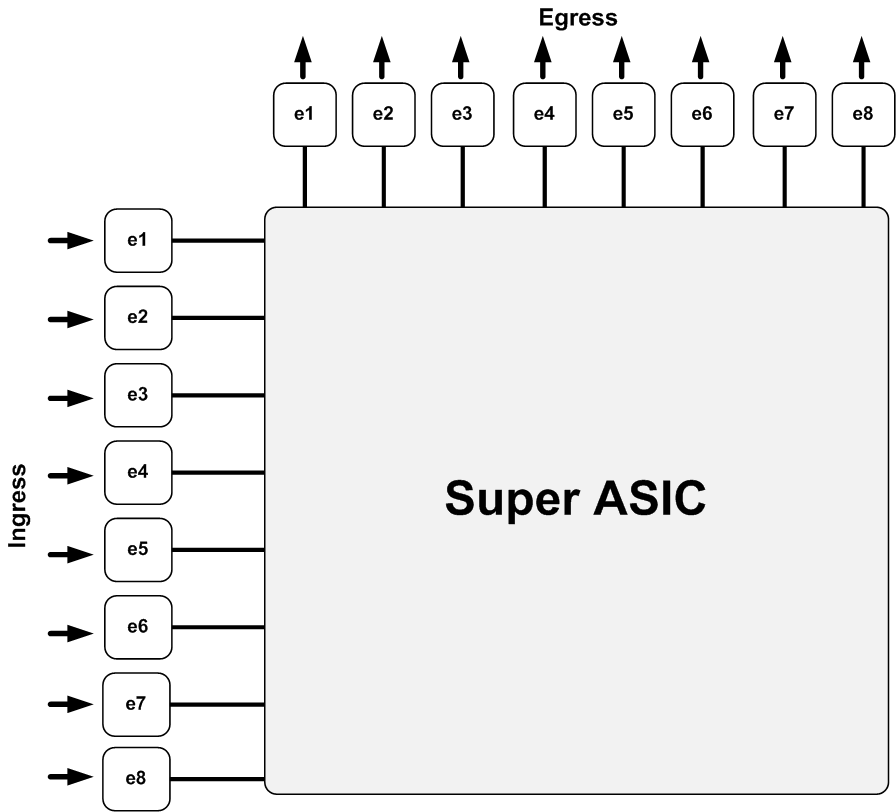
Some switch vendors take a different approach and cascade ASICs. Take a look at Figure 4-7. Here, there are 16 ports, divided into two modules. Each of the four ports is controlled by a single 10 Gbps ASIC. Each of those ASICs connects to a 40 Gbps ASIC that manages interconnectivity between all the modules. This works, but it doesn’t scale well. I’ve seen this type of solution in 1RU or 2RU switches with only a couple of expansion modules. Note that the backplane speed cannot be improved with such a design, as it is purposely built for this scale.
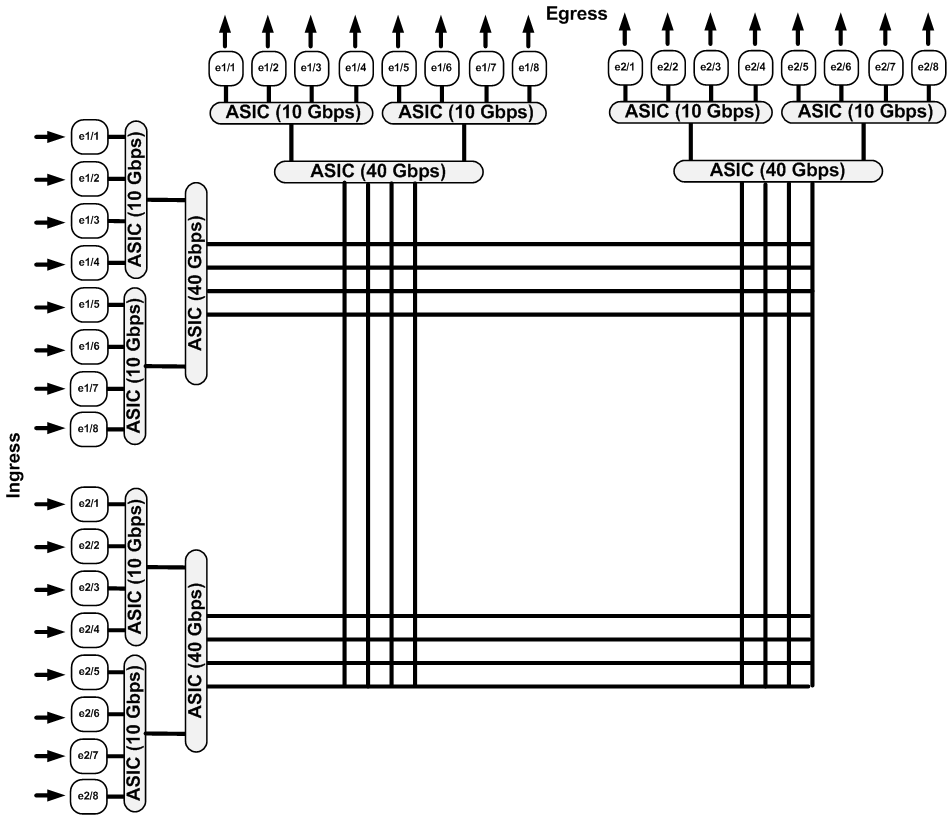
This type of switch will get you 10 Gbps connectivity, but at a lower aggregate throughput, which equates to oversubscription. Fine for an office switch, and for some datacenter switches, but for high-end networking, I’d like to see a non-blocking eight-port 10 Gbps switch. That would look something like the switch depicted in Figure 4-8.
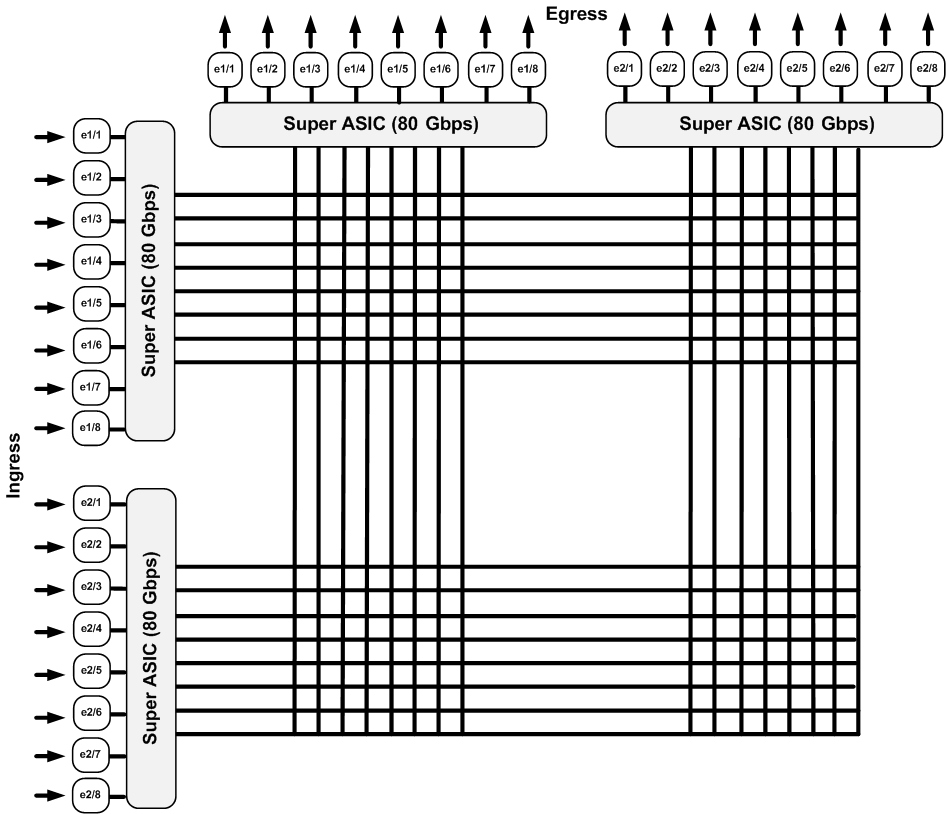
This is better, but it’s still not scalable because we can’t add any connections to the core fabric. So what if we used even bigger, better ASICs to mesh all of our modules together? In Figure 4-9, ASICs perform the intermodule connectivity. In this model, assuming the hardware was designed for it, we could theoretically add more modules, provided the ASICs in the center could support the aggregate bandwidth.
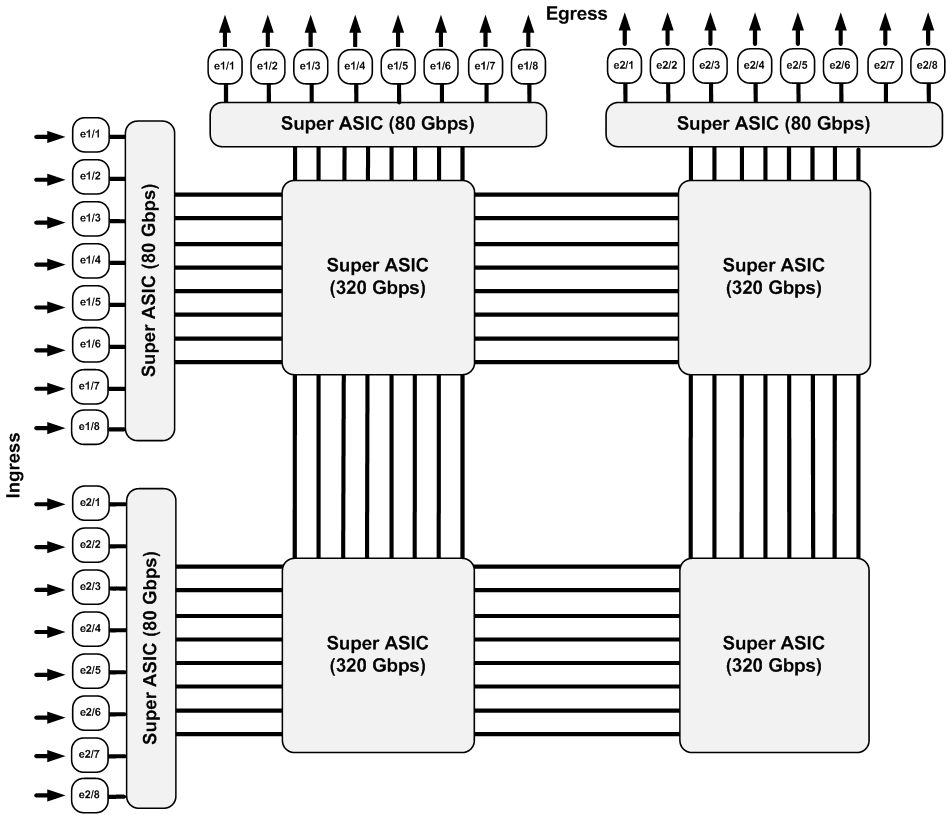
When it really comes down to it, how the backplane functions rarely matters. What matters is whether or not the switch is truly non-blocking. If that’s done with 1 ASIC or 12, does it really matter? Probably not to those of use who are designing and building networks, but to the guys that write the code, it can make their lives easier or harder.
Arista switches incorporate a few different designs, depending on the design requirements of the switch. The Arista 7050S-64 uses a single Broadcom Trident+ ASIC to switch 64 non-blocking 10 Gbps ports. To put that in perspective, that’s more non-blocking port density than a Cisco 6509 loaded with the latest supervisors and seven 8-port 10 Gbps modules. There are a lot of ASICs in a fully loaded 6509.
That’s not to say that the single ASIC approach is always the right solution. The Arista 7500 chassis 48-port 10 Gbps non-blocking modules has one ASIC per every eight ports (six per module). Each module has a total of 1.25 Tb access to the backplane fabric (648 Gbps TX and 648 Gbps RX), which translates to the possibility of each slot supporting multiple 40 Gbps and even 100 Gbps interfaces, all of which would be non-blocking.
Get Arista Warrior now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

